Momo XL:基于SDXL的动漫风格模型Momo XL 是一个基于 Stable Diffusion XL (SDXL) 的动漫风格模型,经过微调后,能够生成具有详细和生动美学的优质动漫风格图像。这款模型专为艺术家和动漫爱好者设计,提供了多...图像模型# Momo XL# SDXL# 动漫风格1年前05060
高级插图模型Illustrious:专门针对插画和动画任务进行了优化,主要用于生成动漫风格的图像OnomaAI 研究小组推出一个高级插图模型Illustrious,它主要用于生成动漫风格的图像。Illustrious XL是一个基于SDXL的模型,专门针对插画和动画任务进行了优化。它是基于 Ko...图像模型# Illustrious# Illustrious XL# 插图模型1年前01,2610
智谱AI推出图像生成模型 CogView3 以及 CogView-3Plus清华和智谱 AI的研究团队开源了图像生成模型 CogView3 以及CogView-3-Plus ,CogView3 是一个基于级联扩散的文本生成图像系统,采用了接力扩散(relay diffusio...图像模型# CogView-3Plus# CogView3# 图像生成1年前06040
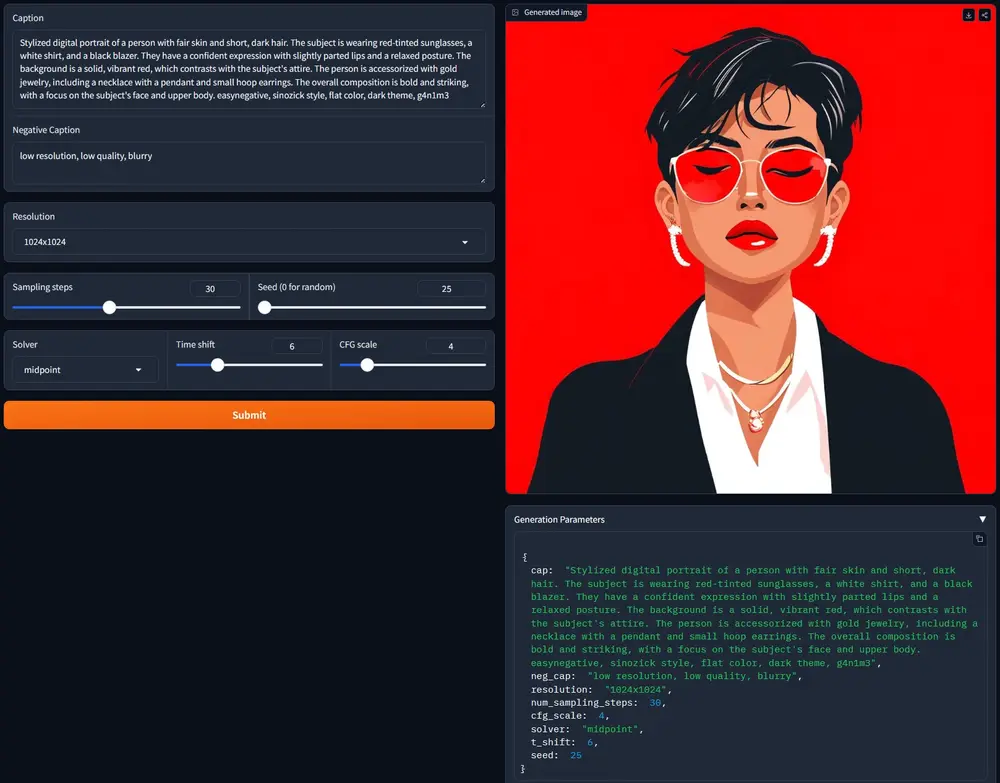
小红书推出图像生成模型StoryMaker:不仅能保持面部一致性,还能保持服装、发型和身体的一致性,从而通过一系列图像促进故事的创作小红书推出图像生成模型StoryMaker,它专门设计用于在文本到图像的生成过程中保持人物的一致性。这种一致性不仅限于人物的面部特征,还包括服装、发型和身体特征。通过这种方式,StoryMaker能够...图像模型# StoryMaker# 小红书1年前05320
Playground推出Playground v3:不仅在图形设计方面表现出色,还引入了一些新的能力,比如精确的RGB颜色控制和强大的多语言理解能力Playground上线了Playground v3 beta版本,同时还发布了技术报告,与传统的依赖T5或CLIP文本编码器的预训练语言模型的文本到图像生成模型不同,Playground v3完全集...图像模型# Playground v31年前04210
基于Mamba架构的自回归(AR)图像生成模型AiM:实现高质量和高效率的图像生成,同时保持推理速度的优势北京邮电大学、中国科学院大学、香港理工大学和中国科学院自动化研究所的研究人员推出自回归(autoregressive, AR)图像生成模型AiM,它基于Mamba架构构建。AiM模型的目的是实现高质量...图像模型# AiM# Mamba架构1年前07030
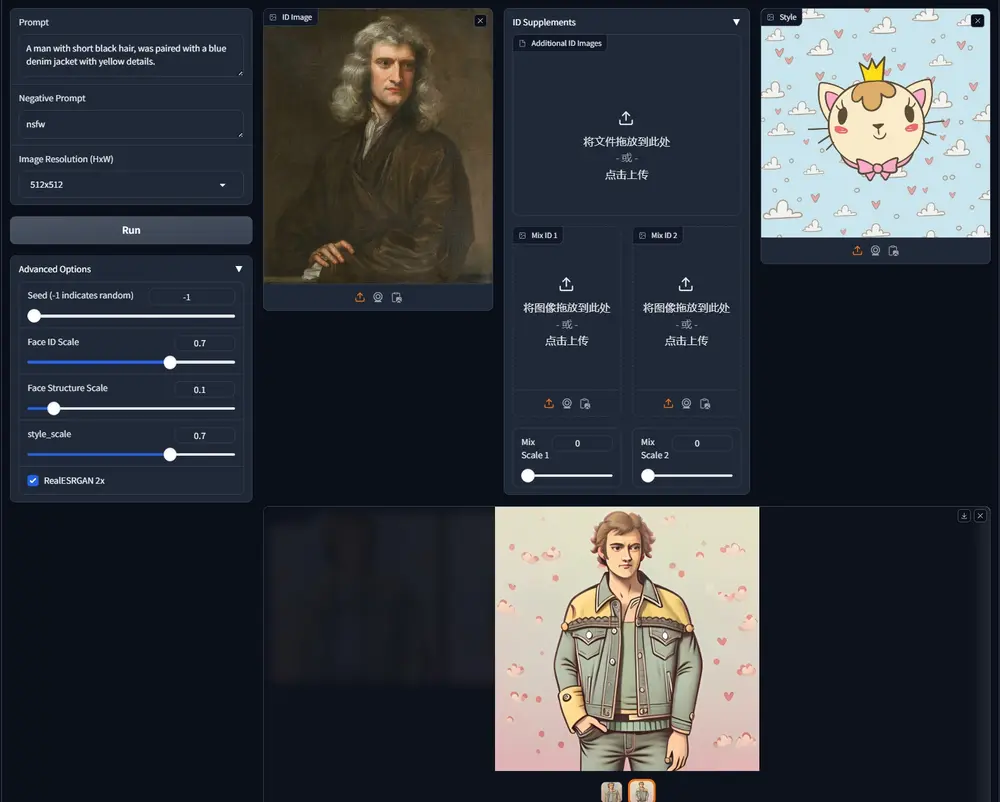
人像个性化框架UniPortrait:支持单人物(Single-ID)和多人物(Multi-ID)图像的定制化生成阿里巴巴集团智能计算研究院推出人像个性化框架UniPortrait,支持单人物(Single-ID)和多人物(Multi-ID)图像的定制化生成。简单来说,UniPortrait能够根据用户提供的文本...图像模型# UniPortrait# 人像个性化1年前08480
强大且高效的图像和视频生成控制方法ControlNeXt:同时支持图像和视频,并能整合多种形式的控制信息香港中文大学和思谋科技的研究人员推出强大且高效的图像和视频生成控制方法ControlNeXt,它同时支持图像和视频,并能整合多种形式的控制信息。在这个项目中,我们提出了一种新方法,与 ControlN...图像模型# ControlNeXt1年前09410
新型多模态自回归模型Lumina-mGPT:能够执行各种视觉和语言任务,尤其擅长根据文本描述生成逼真的图片上海人工智能实验室和香港中文大学的研究人员推出新型多模态自回归模型Lumina-mGPT,它能够执行各种视觉和语言任务,尤其擅长根据文本描述生成逼真的图片。与现有的基于自回归的图像生成方法不同,Lum...图像模型# Lumina-mGPT# 多模态自回归模型1年前07250
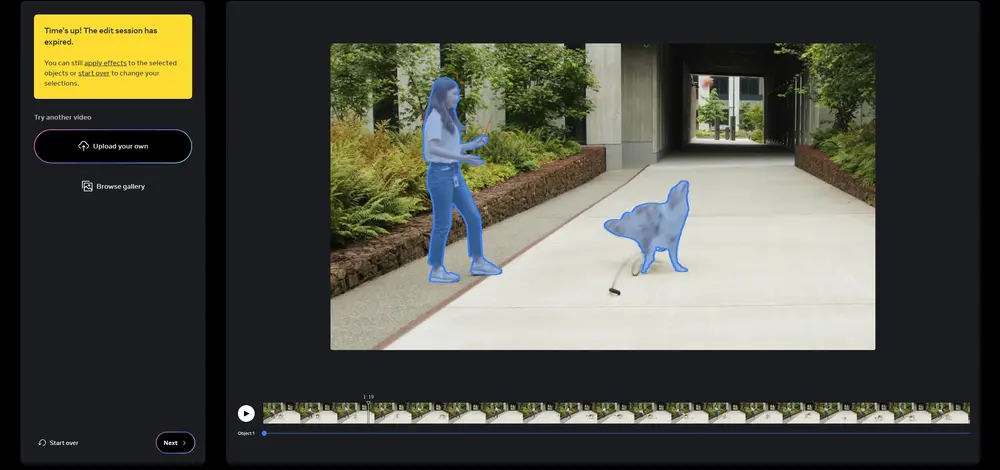
Meta推出图像和视频分割模型SAM 2:图像和视频中的可提示视觉分割Meta在去年推出了图像分割模型Segment Anything,今年它们又推出了升级版Segment Anything Model 2 (SAM 2),这是一种用于图像和视频中可提示视觉分割的基础模...图像模型# Meta# SAM 2# 分割模型1年前06150
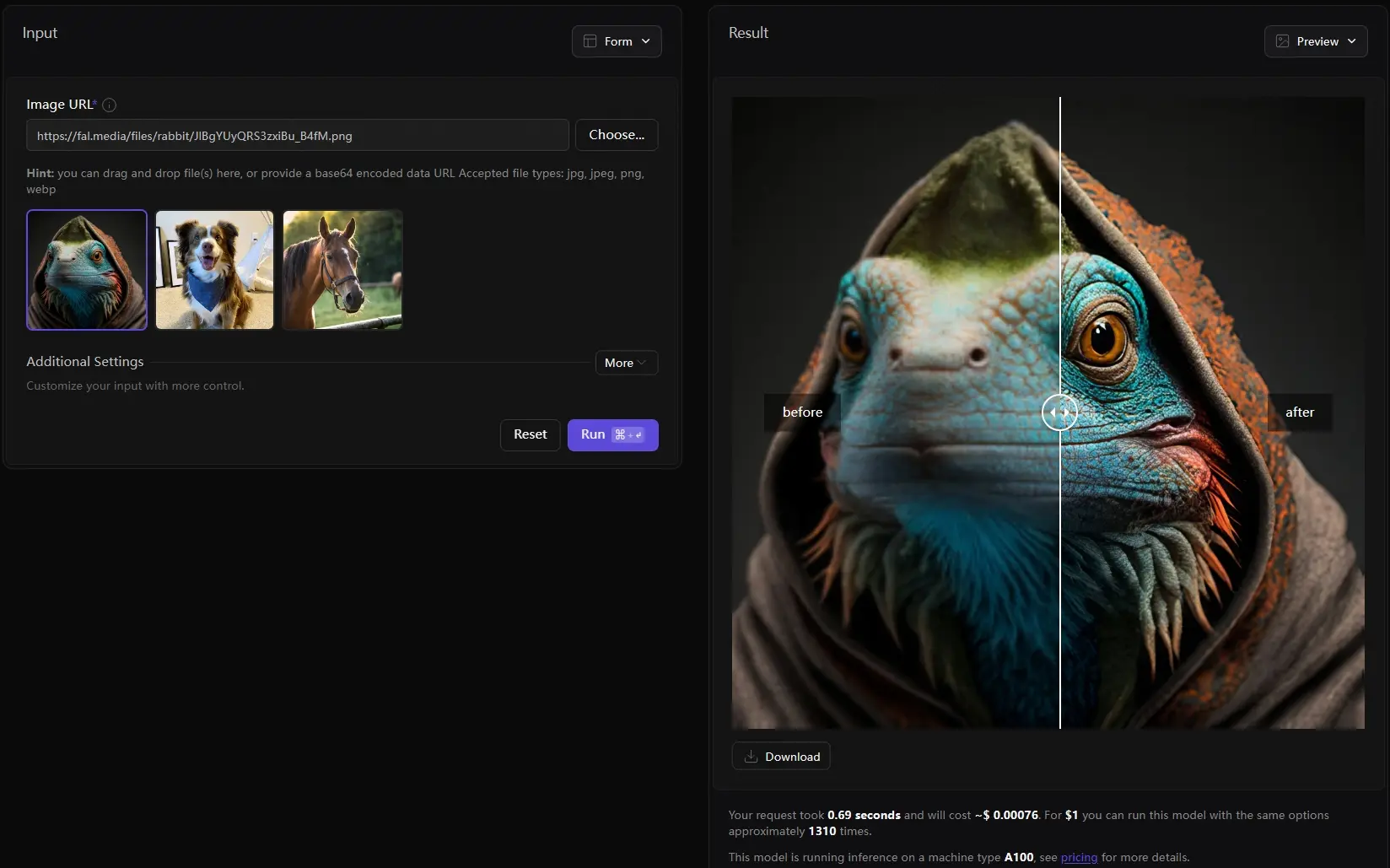
Fal.ai平台推出了新一代GAN 图像放大工具AuraSR的第二版AuraSR-v2Fal.ai平台推出了新一代GAN 图像放大工具AuraSR的第二版,上个月它们推出了AuraSR 第一版后,得到了开源社区积极回应,让他们立刻着手开发新版。AuraSR 以 Adobe 的 Giga...图像模型# AuraSR# AuraSR-v2# Fal.ai1年前07450
日本团队推出浮世绘风格专用生成模型Evo-Ukiyoe和浮世绘上色模型Evo-Nishikie日本AI团队Sakana AI发布了专门用于生成浮世绘风格的生成模型Evo-Ukiyoe和浮世绘上色模型Evo-Nishikie,此模型是是以转为日语打造的图像生成模型Evo-SDXL-JP为基础,通...图像模型# Evo-Nishikie# Evo-Ukiyoe# 浮世绘1年前07860