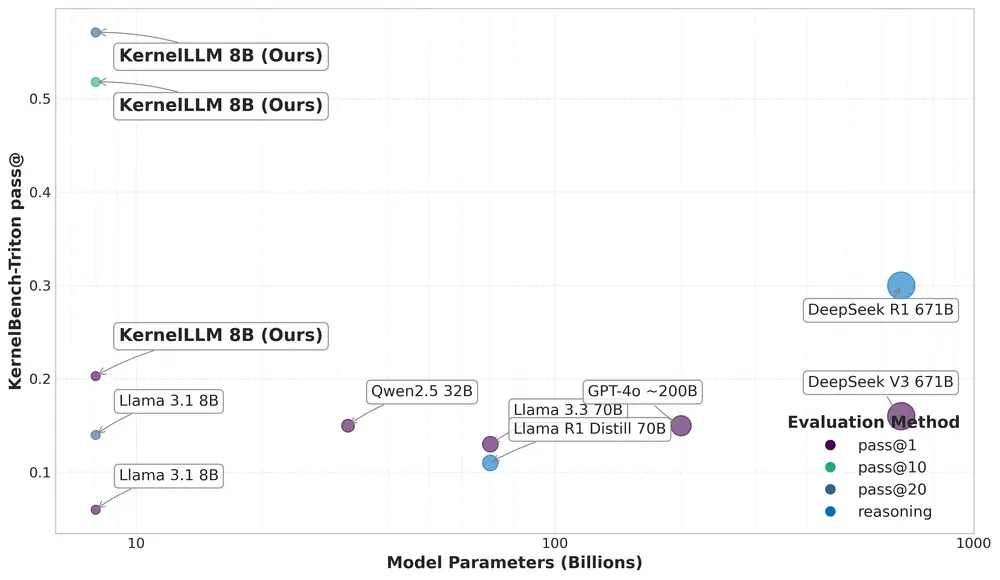
Meta推出基于 Llama 3.1 Instruct的大语言模型KernelLLM:专注于使用 Triton 编写高效GPU内核的任务Meta推出了一款名为 KernelLLM 的大语言模型,该模型基于 Llama 3.1 Instruct,专注于使用 Triton 编写高效GPU内核的任务。KernelLLM的核心目标是通过自动化...大语言模型# KernelLLM# Llama 3.1 Instruct# Meta7个月前01350
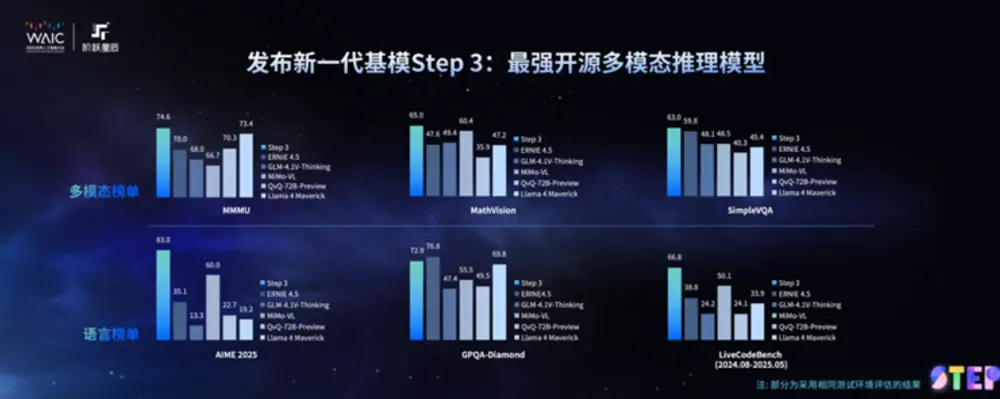
阶跃星辰发布 Step 3:开源最强多模态推理模型,推动“模芯”生态共建在2025世界人工智能大会(WAIC)开幕前夕,中国大模型企业阶跃星辰于今日在上海正式发布其新一代基础大模型——Step 3。该模型定位为“推理时代最适合应用的基座模型”,将于7月31日面向全球开源...大语言模型# Step 3# 多模态推理模型# 阶跃星辰5个月前01330
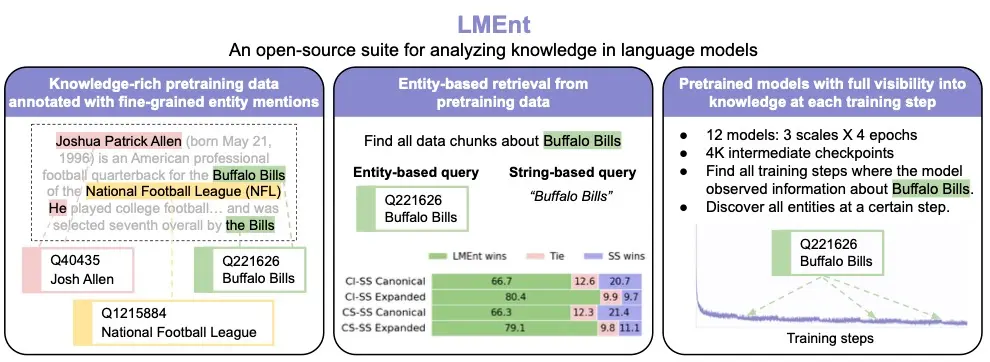
大语言模型知识获取研究新工具:特拉维夫大学与麦吉尔大学推出 LMEnt 套件语言模型正在越来越多地承担需要世界知识的任务:回答问题、生成事实性文本、辅助决策……但一个根本性问题仍未解决: 模型是如何从训练数据中“学会”知识的? 我们训练模型时喂的是文本,但它输出的却是“信念...大语言模型# LMEnt# 大语言模型4个月前01320
OPPO AI实验室推出新范式Chain-of-Agents(CoA):用于在单个模型中实现多智能体系统的复杂问题解决能力OPPO AI实验室推出一种新的范式——Chain-of-Agents(CoA),用于在单个模型中实现多智能体系统(Multi-Agent Systems, MAS)的复杂问题解决能力。传统的多智能体...大语言模型# Chain-of-Agents# CoA# OPPO AI实验室4个月前01320
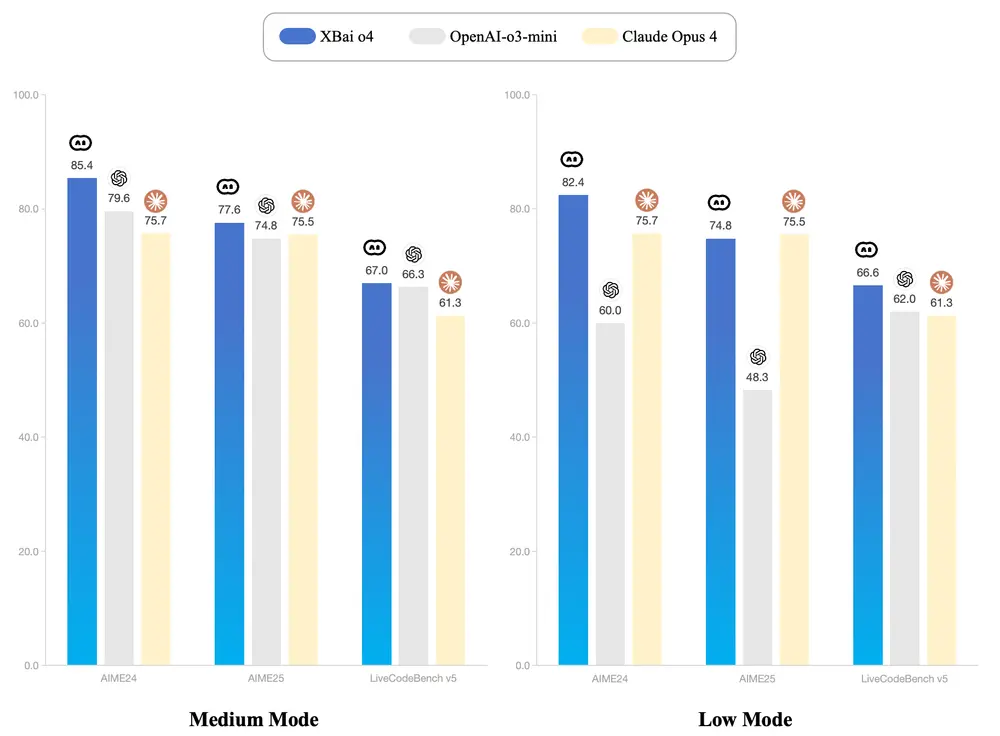
问小白开源基于反思型生成范式训练的推理模型XBai o4问小白发布了XBai o4,o=open,o4代表其开源的第四代大模型技术。XBai o4在复杂推理能力方面表现出色,在Medium模式下,XBai o4 现已全面超越OpenAI-o3-mini。 ...大语言模型# XBai o4# 问小白5个月前01320
Sarvam AI 发布 Sarvam-Translate:支持印度22种语言的文档级翻译模型Sarvam AI 推出了其最新翻译模型 Sarvam-Translate,一款专注于支持印度 22 种官方语言的高质量、上下文感知翻译系统。该模型基于 Google 的 Gemma3-4B-IT 进...大语言模型# Sarvam AI# Sarvam-Translate# 翻译模型5个月前01320
谷歌发布推出改进的 Gemini 2.5 Flash 和 Flash-Lite 版本:响应更快、成本更低、智能更强谷歌今日推出 Gemini 2.5 Flash 和 Gemini 2.5 Flash-Lite 的预览更新版本,已在 Google AI Studio 与 Vertex AI 平台上线。此次升级聚焦于...大语言模型# Gemini 2.5 Flash# Gemini 2.5 Flash-Lite# 谷歌3个月前01310
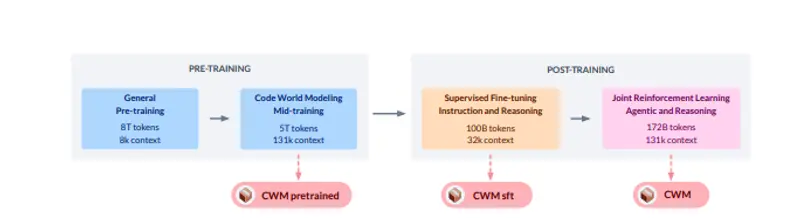
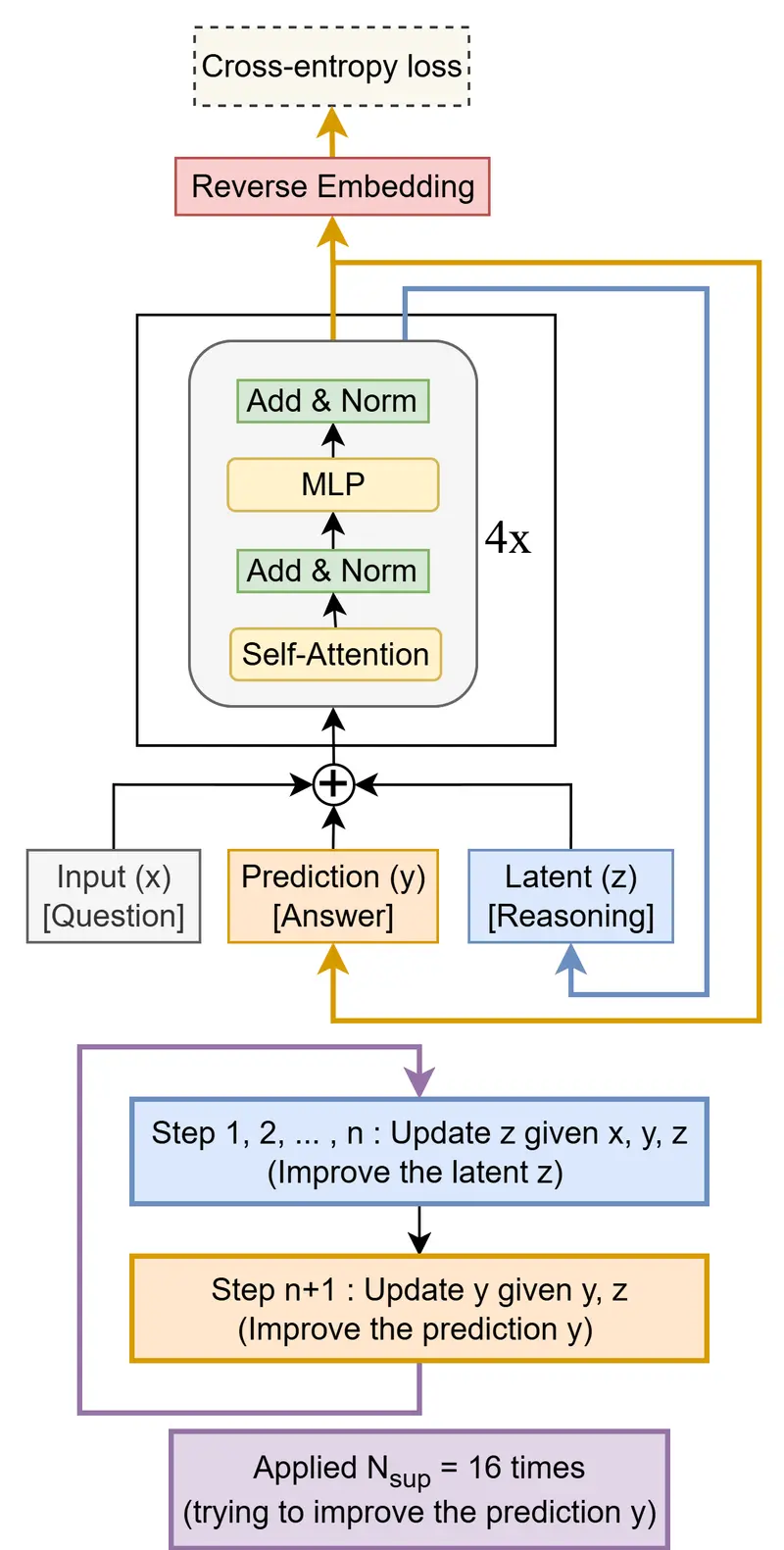
Meta 开源代码世界模型CWM:让AI像程序员一样"推演"代码的世界模型Meta近日发布并开源代码世界模型(Code World Model, CWM),这是一款320亿参数的仅解码器大型语言模型(LLM),支持最长131k tokens的上下文长度。不同于传统代码模型仅...大语言模型# CWM# Meta# 代码世界模型3个月前01310
三星研究员发布 TRM:700万参数小模型,在特定推理任务上超越大模型一个仅含 700万参数 的神经网络,如何在性能上匹敌甚至超过参数量高达其 10,000倍 的大语言模型? 这不是理论设想,而是现实。 三星先进技术研究院(SAIT)蒙特利尔分部的高级AI研究员 Ale...大语言模型# TRM# 三星# 小模型2个月前01300
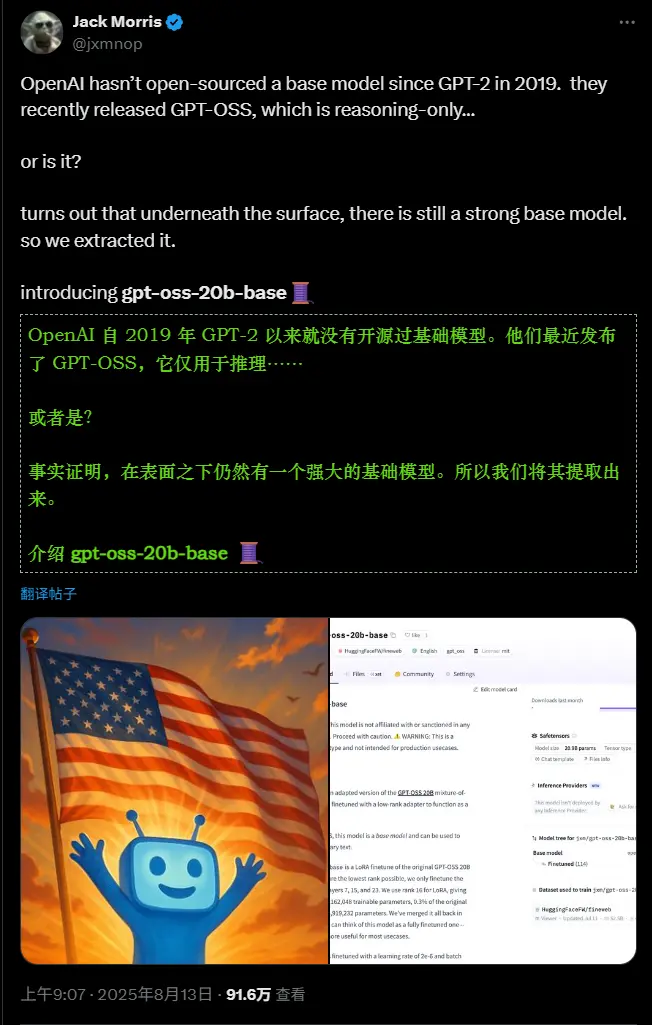
研究员改造 OpenAI 开源模型 gpt-oss-20b:移除推理约束,还原 “无对齐” 基础版本8月初,OpenAI 发布了其首个自 GPT-2 以来的开放权重大语言模型系列 gpt-oss,包含 200 亿(gpt-oss-20b)和 1200 亿(gpt-oss-120b)参数两个版本,采用...大语言模型# gpt-oss-20b# gpt-oss-20b-base4个月前01290
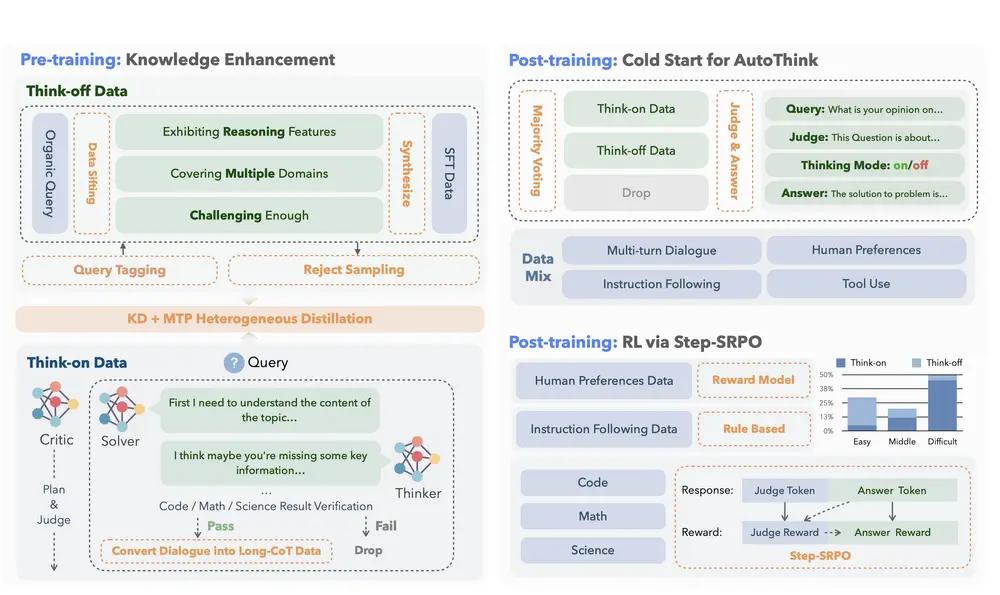
快手 Kwaipilot 团队开源 40B 大模型 KAT-V1-40B :用 AutoThink 实现智能“何时思考”在当前大模型普遍追求“深度推理”的趋势下,一个更现实的问题逐渐浮现:是否每个问题都需要长篇思维链? 过度使用思维链(Chain-of-Thought, CoT)不仅增加计算开销、拖慢响应速度,还可能导...大语言模型# KAT-V1-40B# 快手5个月前01290
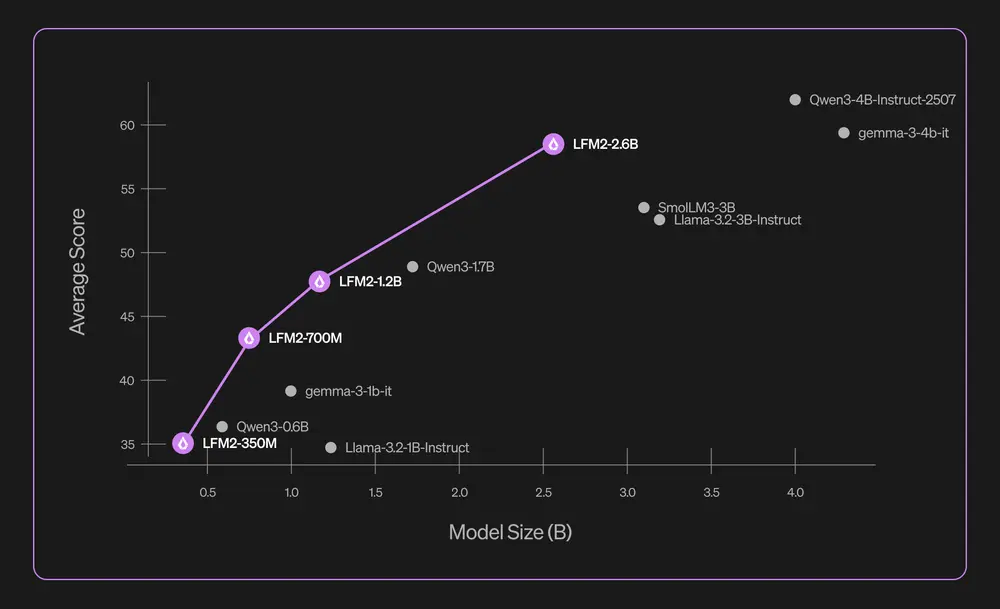
LFM2-2.6B发布:小参数,高性能,重新定义语言模型效率在大模型“军备竞赛”愈演愈烈的今天,参数规模是否仍是衡量能力的唯一标准? Liquid AI 最新推出的 LFM2-2.6B 给出了一个有力的回答: 更优的架构设计,可以让更小的模型,在关键任务上超越...大语言模型# LFM2-2.6B3个月前01270