LatticeWorld:基于多模态指令的高效 3D 世界生成框架由网易、北京航空航天大学、清华大学与香港城市大学联合研究团队提出,LatticeWorld 是一个面向复杂 3D 虚拟环境自动生成的新框架。它通过融合轻量级大型语言模型(LLM)与工业级渲染引擎,探索...3D模型# LatticeWorld5个月前01090
英伟达开源ViPE工具:从普通视频中精准提取3D信息,还附赠9600万帧标注数据集在空间AI领域,“3D几何感知”是许多技术落地的基础——无论是AR场景构建、自动驾驶环境感知,还是视频内容的3D重构,都需要精准的相机姿态、内参和深度信息。但长期以来,从野外随机拍摄的视频(如自拍、行...3D模型# ViPE# 英伟达5个月前03460
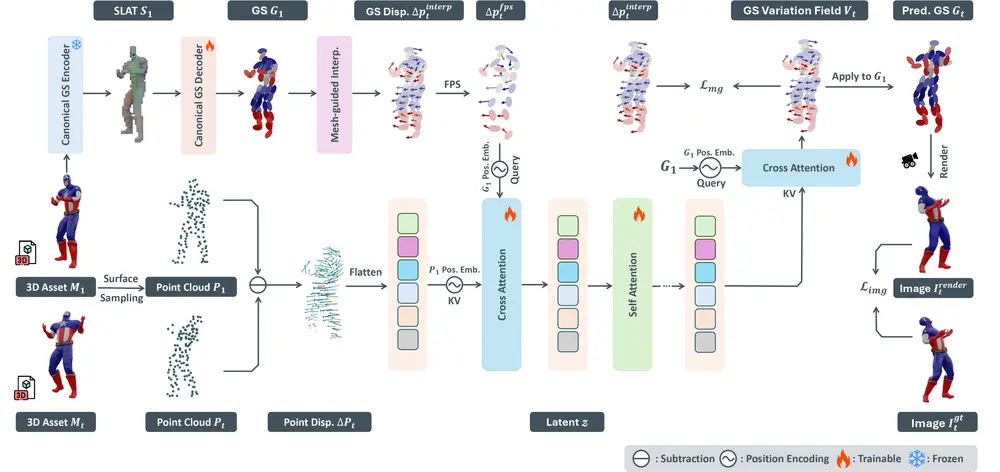
AnimaX:支持任意骨骼结构的高效 3D 动画生成框架由北京航空航天大学软件学院、清华大学、香港大学与 VAST 联合提出的新框架 AnimaX,为 3D 角色动画生成带来了一种高效且通用的解决方案。 项目主页:https://anima-x.githu...3D模型# 3D 动画生成# AnimaX5个月前0930
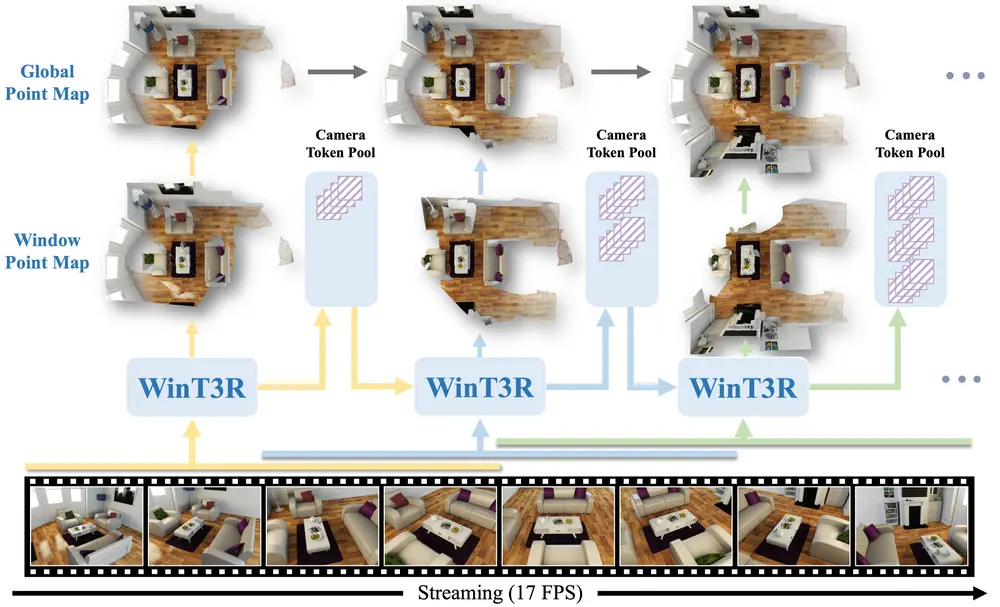
中科大等提出 WinT3R:一种兼顾高精度与实时性的在线 3D 重建新方法由中国科学技术大学、上海人工智能实验室、SII 与浙江大学联合提出的新模型 WinT3R(Window-based Streaming Reconstruction with Camera Token...3D模型# 3D 重建# WinT3R5个月前02010
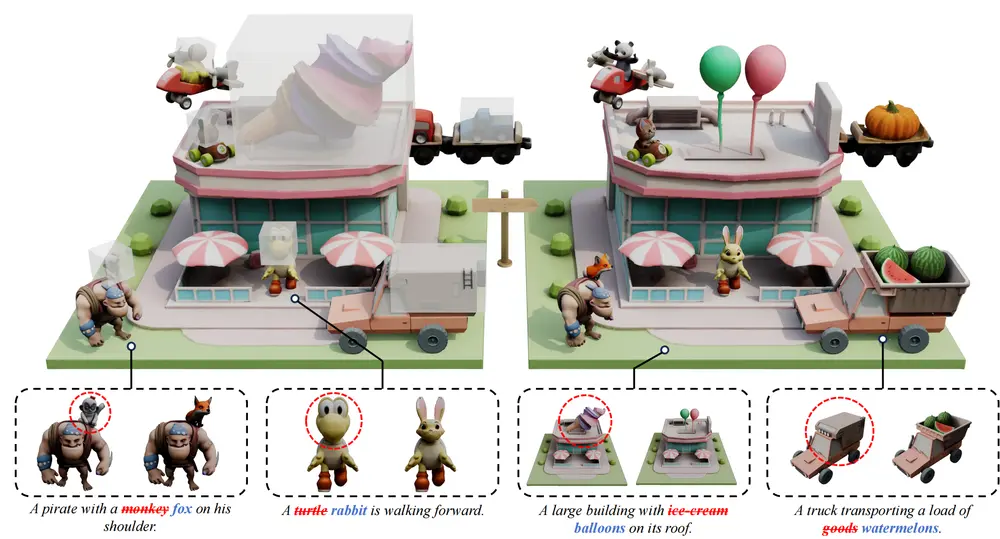
北航、人大等联合腾讯混元提出VoxHammer:无需训练,实现3D模型精准局部编辑3D指定区域的局部编辑,是游戏资产制作、机器人交互场景中的核心需求——比如给游戏角色更换装备、调整机器人零件结构,都需要在修改目标区域的同时,确保未编辑部分的几何形态与纹理不被破坏。 近期,北京航空航...3D模型# 3D模型精准局部编辑# VoxHammer6个月前02590
MV-RAG:用检索增强实现更可靠的文本到3D生成近年来,基于预训练2D扩散模型的文本到3D生成方法取得了显著进展。这类方法通过“蒸馏”2D先验知识,能够生成视觉质量高、多视角一致的3D内容。然而,当面对罕见或未见过的概念(如“博洛尼亚犬”或“Lab...3D模型# 3D生成# MV-RAG6个月前02690
新型3D 编辑框架TINKER:用于高保真度的 3D 编辑浙江大学和浙江工业大学的研究人员推出新型3D 编辑框架TINKER ,用于高保真度的 3D 编辑,能够在仅有少量输入图像(甚至一张或两张)的情况下实现多视角一致的编辑效果,且无需针对每个场景进行优化...3D模型# 3D 编辑框架# TINKER6个月前02390
Matrix-3D:天工AI提出全景式3D世界生成新框架从一张照片或一段文字出发,生成一个可以自由探索的3D世界——这是空间智能的核心愿景之一。近年来,基于视频扩散模型的方法在3D内容生成上取得进展,但普遍存在两大瓶颈: 视野受限:生成视角有限,难以实现全...3D模型# Matrix-3D# 天工AI6个月前02550
中科大&微软提出GVFDiffusion:从单个视频生成动态3D,实现高效4D生成你有没有想过: 仅凭一段手机拍摄的旋转物体视频,就能重建出一个可自由操控、动态连贯的3D模型? 这不是特效,而是AI正在实现的能力。 中国科学技术大学与微软的研究团队近日提出 GVFDiffusion...3D模型# GVFDiffusion6个月前01440
3D-R1:让大模型真正理解三维空间的统一推理模型上海工程技术大学与北京大学计算机学院联合提出一个开源通用模型 3D-R1,旨在提升3D视觉-语言模型(3D Vision-Language Models, 3D-VLMs)在复杂场景中的推理能力,推动...3D模型# 3D-R1# 推理模型7个月前01300
DreamScene:用 GPT-4 规划 + 3D 高斯建模,实现端到端文本生成 3D 场景从一句“现代客厅,带沙发和挂墙电视”,到一个完整、一致、可编辑的 3D 场景——这曾是 3D 内容创作的理想。如今,中国科学技术大学、南洋理工大学、香港科技大学(广州)与奥胡斯大学联合提出的 Drea...3D模型# 3D 场景# DreamScene7个月前02170
清华团队提出3D场景生成新框架ScenePainter:解决3D生成中的语义漂移难题从一张街景照片出发,AI能否自动“走”过整条街道,生成沿途连续、风格统一的3D视图?这不仅是虚拟现实、自动驾驶仿真的基础需求,也是生成式AI在空间理解上的重要挑战。 然而,当前主流方法在生成长序列3D...3D模型# 3D生成# ScenePainter7个月前03050