
随着 AI 编程能力的快速演进,越来越多的模型可以“一键生成”完整应用。但一个问题随之而来:我们该如何判断这些 AI 生成的应用,是否真的可用?
传统的代码评测方法,如 LeetCode 式的算法题或单元测试覆盖率,已无法满足对现代 Web 应用的评估需求——因为它们衡量的是代码正确性,而非实际功能完整性与用户体验一致性。
RealDevWorld 应运而生。它不是一个普通的代码测试集,而是首个专为评估 AI 在真实软件开发任务中表现而设计的综合性基准测试平台。
它的目标很明确:让 AI 生成的应用,经得起生产环境的考验。
为什么需要 RealDevWorld?
当前 AI 编程面临三大评估困境:
- 生成代码 ≠ 可运行系统
很多模型能写出语法正确的代码,但无法保证项目可部署、前端可交互、后端能响应。 - 缺乏真实场景约束
合成性编码任务(如“写一个排序函数”)脱离真实开发语境,忽视了依赖管理、UI 设计、跨文件协调等关键环节。 - 传统测试无法自动化评估交互式应用
网页不是静态脚本。点击按钮、表单提交、页面跳转……这些用户行为难以通过单元测试捕捉。
RealDevWorld 的出现,正是为了填补这一空白。
核心能力:用 AI 评估 AI
RealDevWorld 引入了 AppEvalPilot ——一个基于智能代理(intelligent agent)的自动化评估系统,具备 GUI 理解能力和端到端操作能力。
它不仅能运行生成的应用,还能像真实用户一样:
- 启动服务
- 访问页面
- 模拟点击与输入
- 验证功能流程是否完整
- 检查部署质量与响应性能
这意味着,评估不再依赖人工抽查或预设测试用例,而是由 AI 自动完成从“构建”到“使用”的全流程验证。
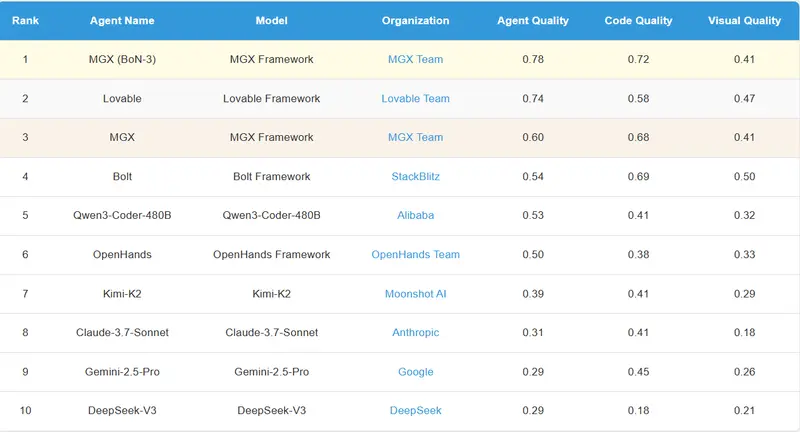
数据集概览:194 个真实开发任务
RealDevBench 是 RealDevWorld 的核心数据集,包含 194 个精心策划的真实项目需求,覆盖多种应用场景:
| 类别 | 项目数 | 占比 | 典型示例 |
|---|---|---|---|
| 展示项目 | 97 | 50.0% | 企业官网、作品集、产品介绍页 |
| 分析项目 | 36 | 18.6% | 销售数据看板、用户行为分析工具 |
| 游戏项目 | 33 | 17.0% | 小型网页游戏、互动解谜应用 |
| 数据项目 | 28 | 14.4% | 数据导入导出系统、CSV 可视化工具 |
每个项目都包含:
- 明确的功能需求说明
- 多模态输入要求(如图片、文档、3D 模型、数据文件)
- UI/UX 设计指导
- 部署与运行期望
此外,团队还公开了 54 个标准化测试样本,可用于快速批量评估不同模型的输出质量,兼顾效率与可比性。
不止于“写代码”:评估完整的开发链路
RealDevWorld 的评估维度远超传统编码任务,涵盖现代软件开发的关键环节:
✅ 多文件结构组织
✅ 前后端协同能力
✅ 静态资源处理(图像、样式、脚本)
✅ 用户界面可用性
✅ 实际部署可行性(Docker、端口配置等)
✅ 功能流程闭环验证
这使得它成为目前最接近“生产就绪”标准的 AI 开发评估体系。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











