在视频理解任务中,如何让机器“看懂”复杂的视觉场景?不仅要知道画面中有哪些对象,还要理解它们之间的互动关系——这正是动态场景图生成(Dynamic Scene Graph Generation, DSGG) 的核心目标。
然而,传统方法依赖大量逐帧标注的关系数据,成本极高。为此,弱监督动态场景图生成(Weakly Supervised DSGG, WS-DSGG) 应运而生:仅使用视频中单帧的未定位场景图作为监督信号,大幅降低标注负担。
但现有方法存在明显短板:依赖现成外部检测器生成伪标签 → 在动态、交互丰富的场景中定位不准、置信度低 → 最终影响场景图质量。
为解决这一瓶颈,来自腾讯、百度与北京大学的研究团队提出 TRKT(Temporal-enhanced Relation-aware Knowledge Transferring),一种全新的知识迁移框架,在不增加标注成本的前提下,显著提升对象检测精度与关系推理能力。
问题背景:弱监督下的检测困境
WS-DSGG 的训练数据仅包含:
- 一段视频
- 一帧带有对象和关系标签的场景图(无空间位置信息)
模型需自行推断:
- 哪些帧包含这些对象?
- 它们出现在画面的什么位置?
- 关系发生在谁与谁之间?
现有方法通常依赖预训练的目标检测器(如 Faster R-CNN)生成候选区域(proposals),但这类检测器:
- 缺乏对对象间关系的感知
- 忽视视频的时间连续性
- 在运动模糊、遮挡等复杂动态场景中表现不佳
结果是:伪标签噪声大、定位不准、置信度低 → 场景图生成质量受限。
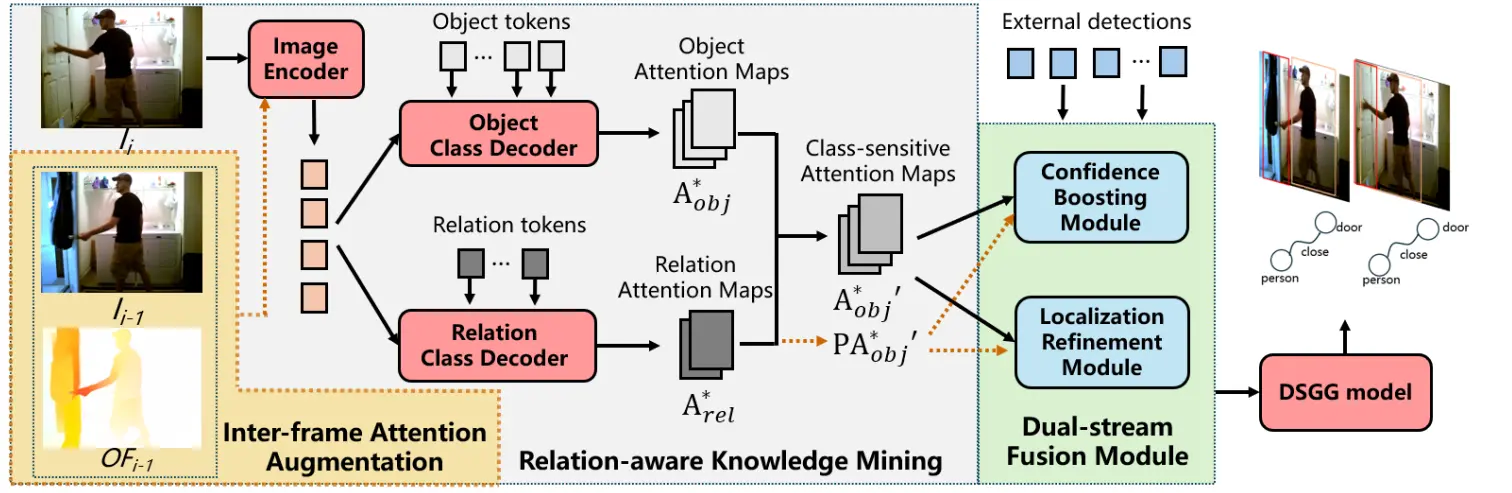
TRKT 的核心思路:从视频中“挖掘知识”,反向增强检测
TRKT 的核心思想是:
不再被动依赖外部检测器,而是主动从视频中提取关系感知的时空线索,用于优化检测结果。
它通过两个关键机制实现这一目标:
1. 关系感知知识挖掘(Relation-aware Knowledge Mining)
引入对象与关系类别解码器,为每个类别生成对应的注意力图。
- 对象解码器 → 生成“猫”、“人”等类别的注意力热图
- 关系解码器 → 生成“人-骑-马”、“狗-追-球”等三元组的交互区域热图
这些热图能精准突出目标对象及其交互区域,形成语义引导的空间先验。
✅ 优势:比通用检测器更关注“关系发生的位置”
2. 帧间注意力增强(Temporal Attention Enhancement)
单纯的空间注意力在运动模糊或快速移动场景中仍不稳定。
TRKT 引入光流信息作为时间线索,对注意力图进行增强:
- 利用光流估计相邻帧之间的像素运动
- 将当前帧的注意力图沿运动方向传播并融合
- 得到更具时序一致性的增强注意力图
✅ 优势:减少运动模糊影响,提升跨帧稳定性
双流融合:用知识反哺检测器
有了高质量的关系感知注意力图,TRKT 通过双流融合模块将其反馈给外部检测器,提升其输出质量。
该模块包含两个子组件:
✅ 定位细化模块(Localization Refinement Module, LRM)
- 将注意力图作为空间权重,重新加权检测器的候选区域
- 抑制低响应区域,增强高相关区域
- 输出更精确的对象边界框
✅ 置信度增强模块(Confidence Boosting Module, CBM)
- 根据注意力强度调整候选框的分类置信度
- 高注意力区域 → 提升置信度;低响应区域 → 降低分数
- 减少误检,提升高质量提议的比例
💡 这是一种“闭环式”知识迁移:从视频中学习知识,再用于改进检测本身。
实验结果:全面超越基线
在主流数据集 Action Genome 上进行评估,TRKT 表现出显著优势:
1. 对象检测性能提升
| 指标 | 提升幅度 |
|---|---|
| 平均精度(AP) | +13.0% |
| 平均召回率(AR) | +1.3% |
显著改善了低质量提议问题,尤其在小目标和交互区域。
2. 场景图生成性能
| 场景 | 提升幅度 |
|---|---|
| With Constraint | +1.72% |
| No Constraint | +2.42% |
TRKT 在所有评估指标上均优于基线方法 PLA,验证了其在复杂视频理解任务中的有效性。
应用场景
TRKT 的技术路径适用于多种需要细粒度视频理解的场景:
| 场景 | 应用价值 |
|---|---|
| 视频监控 | 自动识别“人闯入禁区”、“车辆追逐”等事件,依赖准确的对象与关系检测 |
| 体育分析 | 分析球员间的传球、对抗关系,构建战术图谱 |
| 自动驾驶 | 理解“行人欲横穿马路”、“车辆变道”等交互行为,提升决策安全性 |
| 智能内容创作 | 辅助视频剪辑、自动生成字幕或描述,理解画面语义结构 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...