腾讯推出 Think in Games (TiG) 框架,通过强化学习(Reinforcement Learning, RL)结合大语言模型(LLMs)来提升模型在游戏环境中的决策和推理能力。TiG 通过让 LLMs 直接与游戏环境互动,学习如何将理论知识转化为实际操作,同时保留了 LLMs 本身强大的推理和解释能力。
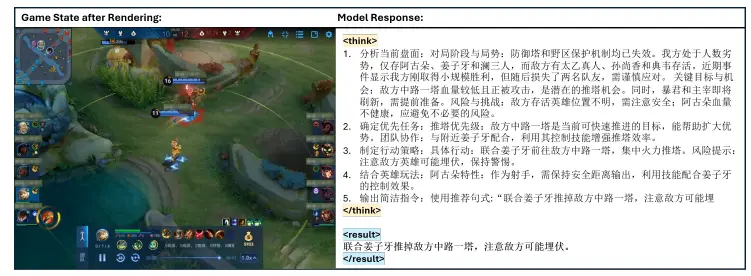
例如,在一个多人在线战斗竞技场(MOBA)游戏中,玩家控制的角色需要决定下一步的行动。TiG 会分析当前的游戏状态,包括队友的位置、敌人的位置、防御塔的血量等,然后生成一个建议的行动,如“与队友一起推掉敌方中路一塔,并注意敌方可能的埋伏”。同时,TiG 会提供详细的推理过程,解释为什么选择这个行动,包括当前的局势分析、风险评估和团队协作建议。
主要功能
TiG 的主要功能包括:
- 语言引导的策略生成:LLMs 生成基于语言的策略,这些策略通过在线强化学习根据环境反馈进行迭代优化。
- 实时决策支持:为游戏玩家提供实时的决策建议,帮助玩家在复杂的游戏环境中做出最优选择。
- 透明和可解释的决策过程:TiG 不仅提供决策建议,还生成详细的推理过程,使玩家能够理解模型的决策逻辑。
主要特点
TiG 的主要特点包括:
- 高效的数据和计算需求:与传统的强化学习方法相比,TiG 在数据和计算需求上显著降低,同时保持了竞争力。
- 深度理解游戏机制:通过直接与游戏环境互动,TiG 能够学习到游戏的深层次机制,而不仅仅是基于文本的知识。
- 透明和可解释性:TiG 提供了详细的自然语言解释,使决策过程更加透明,便于人类理解和信任。
工作原理
TiG 的工作原理基于以下几个关键步骤:
- 游戏状态表示:游戏状态被表示为一个 JSON 对象,包括队友属性、可见防御塔和地图视野数据等。
- 宏观行动空间:定义了一个有限的宏观行动空间,每个行动对应一个预定义的团队目标,如“推上路塔”或“保护基地”。
- 策略模型:使用 LLM 作为策略模型,将游戏状态映射到宏观行动。
- 强化学习:采用 Group Relative Policy Optimization (GRPO) 算法,通过环境反馈对策略模型进行在线优化。
- 奖励建模:使用基于规则的奖励系统,根据模型的行动是否与真实玩家的行为匹配来给予奖励。
测试结果
TiG 的测试结果表明:
- 性能提升:通过多阶段训练(包括监督微调和强化学习),TiG 在游戏决策任务上取得了显著的性能提升。例如,Qwen-2.5-32B 在经过 GRPO 训练后,准确率从 66.67% 提升到 86.84%。
- 数据和计算效率:TiG 在数据和计算需求上显著低于传统强化学习方法,同时保持了竞争力。
- 透明和可解释性:TiG 提供了详细的自然语言解释,使决策过程更加透明和可解释。
应用场景
TiG 的应用场景包括:
- 游戏辅助:为游戏玩家提供实时的决策建议,帮助玩家在复杂的游戏环境中做出最优选择。
- 游戏开发:帮助游戏开发者测试和优化游戏机制,提供基于 AI 的对手或队友。
- 教育和培训:用于教育和培训场景,帮助学生或新手玩家快速掌握游戏策略和技巧。
- 研究和分析:为研究人员提供一个强大的工具,用于研究和分析游戏中的决策过程和策略。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...