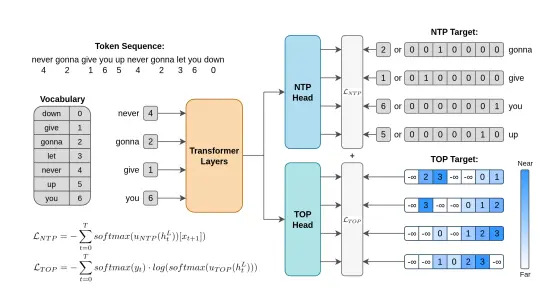
MBZUAI推出新型辅助训练目标Token Order Prediction (TOP),用于改进语言模型中的下一个词预测(Next-Token Prediction, NTP)任务。TOP 通过预测即将出现的词的顺序而不是精确预测未来的词,来提高语言模型的性能。
你正在开发一个文本生成系统,需要生成连贯且准确的文本。传统的 NTP 方法可能会在长文本生成中积累错误,导致生成的文本质量下降。而 TOP 方法通过预测词的顺序,而不是精确预测未来的词,可以更好地捕捉文本的结构和语义,从而生成更高质量的文本。例如,在生成一篇新闻报道时,TOP 可以帮助模型更好地组织句子和段落的顺序,使生成的新闻报道更加连贯和准确。
主要功能
- 改进下一个词预测:通过预测即将出现的词的顺序,而不是精确预测未来的词,来提高语言模型的性能。
- 提高模型泛化能力:在多个标准自然语言处理(NLP)基准测试中,TOP 显示出比传统 NTP 和 MTP 更好的性能。
主要特点
- 学习排序而非预测:与传统的多词预测(Multi-Token Prediction, MTP)不同,TOP 不尝试精确预测未来的词,而是学习预测词的顺序。
- 参数效率高:TOP 只需要一个额外的解嵌入层(unembedding layer),而 MTP 需要多个 Transformer 层,因此 TOP 更加参数高效。
- 可扩展性强:TOP 在不同规模的模型(340M、1.8B 和 7B 参数)上均显示出良好的性能,表明其具有良好的可扩展性。
工作原理
- 目标序列构建:给定一个输入词序列,TOP 构建一个目标序列,其中每个位置的词都被赋予一个基于其在序列中出现顺序的分数。这些分数用于训练模型预测词的顺序。
- 学习排序损失:TOP 使用学习排序(learning-to-rank)损失函数,如 ListNet,来训练模型。这种损失函数允许模型学习预测词的顺序,而不是精确预测未来的词。
- 模型结构:TOP 在标准 Transformer 架构的基础上,增加了一个额外的解嵌入层,用于预测词的顺序。这个额外的层与 NTP 头共享相同的隐藏状态,但使用不同的损失函数进行训练。
测试结果
- 性能提升:在八个标准 NLP 基准测试中,TOP 在大多数任务上都优于 NTP 和 MTP,尤其是在大规模模型(7B 参数)上,TOP 的性能提升更为显著。
- 训练损失:尽管 TOP 的训练损失高于 NTP,但其在 Lambada 测试中的困惑度(perplexity)更低,且在基准测试中得分更高,表明 TOP 可能起到了正则化的作用,减少了过拟合。
应用场景
- 自然语言处理任务:TOP 可以应用于各种自然语言处理任务,如问答、文本生成、摘要等,以提高模型的性能和泛化能力。
- 大规模语言模型训练:由于 TOP 的可扩展性强,它可以应用于大规模语言模型的训练,以提高模型在复杂任务上的表现。
- 多轮对话系统:在多轮对话系统中,TOP 可以帮助模型更好地理解和生成连贯的对话内容,提高对话系统的性能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...