大型扩散模型如 Flux-dev 能够生成高质量图像,但它们通常需要大量显存和计算资源。对于大多数用户来说,这可能是一个难以跨越的门槛。
有没有一种方式,在不明显牺牲效果的前提下,降低模型对硬件的要求?答案是:量化技术。
通过将模型权重从高精度(如BF16)转换为低精度(如INT8或INT4),我们可以显著减少模型体积和推理时的显存占用。但问题来了:
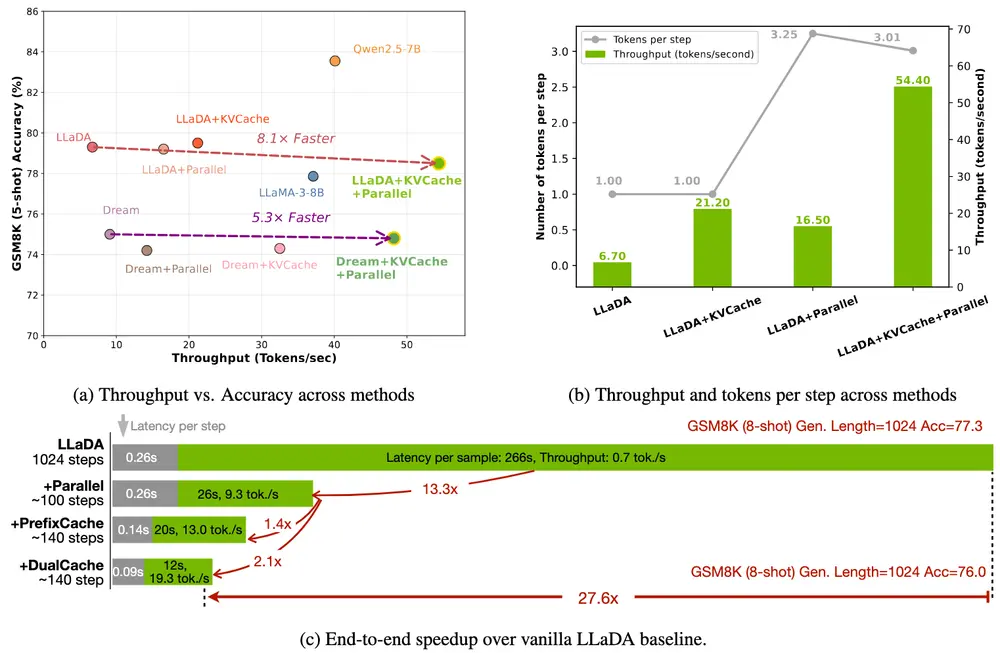
你真的能分辨出量化后的图像质量差异吗?
研究人员做了一个小实验:你可以输入提示词,我们会用原始高精度模型和多个量化版本(如BnB 4位、8位)生成图像,然后让你判断哪张来自量化模型。(来源)
结果往往令人惊讶:8位量化几乎看不出差别,而4位虽然略有下降,但节省的显存非常可观。
接下来,我们将深入探讨 Hugging Face Diffusers 中支持的几种主流量化后端,并以 FLUX.1-dev 模型为例,展示它们如何帮助我们在性能与资源消耗之间找到最佳平衡点。
一、模型结构概览:Flux Pipeline 的三大组件
在进入量化之前,先来认识一下我们即将量化的模型结构 —— FluxPipeline 的主要组成部分:
| 组件 | 功能 | 显存占用(BF16) |
|---|---|---|
| 文本编码器(T5 + CLIP) | 理解输入提示,生成文本嵌入 | T5: ~9.52GB, CLIP: ~246MB |
| 变换器(MMDiT) | 核心生成模块,负责从文本生成图像潜在空间表示 | ~23.8GB |
| VAE(变分自编码器) | 将潜在空间转换为像素图像 | ~168MB |
为了最大化内存节省,我们的实验将聚焦于 T5 和 MMDiT 这两个组件。
二、主流量化后端对比分析
我们选取了目前在 Hugging Face Diffusers 中支持较好的几个量化库进行比较:
- bitsandbytes (BnB)
- torchao
- Quanto
- GGUF
- FP8 分层转换
以下是各方案在加载后内存、峰值内存和推理时间方面的表现:
1. bitsandbytes(BnB)
bitsandbytes 是一个广受欢迎且易于使用的库,支持8位和4位量化,广泛用于大型语言模型和QLoRA微调。我们也可以将其用于基于变换器的扩散和流模型。

| 精度 | 加载后内存 | 峰值内存 | 推理时间 |
|---|---|---|---|
| BF16 | ~31.447 GB | 36.166 GB | 12秒 |
| 4位 | 12.584 GB | 17.281 GB | 12秒 |
| 8位 | 19.273 GB | 24.432 GB | 27秒 |
✅ 支持广泛,适合QLoRA微调;4位量化节省内存最多。
2. torchao
torchao 是一个PyTorch原生库,用于架构优化,提供量化、稀疏性和自定义数据类型,设计上与torch.compile和FSDP兼容。Diffusers支持torchao的多种特殊数据类型,允许对模型优化进行细粒度控制。

| 精度 | 加载后内存 | 峰值内存 | 推理时间 |
|---|---|---|---|
| int4_weight_only | 10.635 GB | 14.654 GB | 109秒 |
| int8_weight_only | 17.020 GB | 21.482 GB | 15秒 |
| float8_weight_only | 17.016 GB | 21.488 GB | 15秒 |
✅ PyTorch原生优化,兼容性强;int4 内存最小,但推理速度慢。
3. Quanto
Quanto 是一个与Hugging Face生态系统集成的量化库,通过optimum库实现。

| 精度 | 加载后内存 | 峰值内存 | 推理时间 |
|---|---|---|---|
| INT4 | 12.254 GB | 16.139 GB | 109秒 |
| INT8 | 17.330 GB | 21.814 GB | 15秒 |
| FP8 | 16.395 GB | 20.898 GB | 16秒 |
✅ 与Hugging Face生态深度集成;适合快速部署。
4. GGUF
GGUF 是一个在llama.cpp社区中流行的文件格式,用于存储量化模型。

| 精度 | 加载后内存 | 峰值内存 | 推理时间 |
|---|---|---|---|
| Q2_k | 13.264 GB | 17.752 GB | 26秒 |
| Q4_1 | 16.838 GB | 21.326 GB | 23秒 |
| Q8_0 | 21.502 GB | 25.973 GB | 15秒 |
✅ 来自llama.cpp生态,适用于离线部署;Q2_k最省内存。
5. FP8 分层转换(enable_layerwise_casting)
FP8分层转换是一种内存优化技术。它通过将模型权重存储为紧凑的FP8(8位浮点)格式工作,大约只占用标准FP16或BF16精度一半的内存。在层进行计算之前,其权重会动态转换为更高的计算精度(如FP16/BF16)。计算完成后,权重立即转换回FP8以实现高效存储。这种方法有效是因为核心计算保持高精度,而对量化特别敏感的层(如归一化层)通常会被跳过。该技术还可以与组卸载结合,进一步节省内存。

| 精度 | 加载后内存 | 峰值内存 | 推理时间 |
|---|---|---|---|
| FP8 (e4m3) | 23.682 GB | 28.451 GB | 13秒 |
✅ 对关键层保留高精度,兼顾性能与稳定性;可与其他优化结合使用。
三、进阶技巧:结合更多内存优化策略
单一量化往往不足以应对大规模模型的需求,我们可以结合以下策略进一步压缩资源占用:
1. 模型 CPU 卸载(enable_model_cpu_offload)
该方法在推理流水线中将整个模型组件(如 UNet、文本编码器或 VAE)在 CPU 和 GPU 之间移动。它能显著节省显存,通常比更细粒度的卸载更快,因为涉及的数据传输较少且规模较大。
| 精度 | 加载后内存 | 峰值内存 | 推理时间 |
|---|---|---|---|
| BnB 4位 | 12.383 GB | 12.383 GB | 17秒 |
| BnB 8位 | 19.182 GB | 23.428 GB | 27秒 |
✅ 显存节省明显,适合资源有限设备。
2. 组卸载(enable_group_offload / apply_group_offloading)
它将模型内部的层组(如 torch.nn.ModuleList 或 torch.nn.Sequential 实例)移动到 CPU。这种方法通常比完整模型卸载更节省内存,且比顺序卸载更快。
| 精度 | 加载后内存 | 峰值内存 | 推理时间 |
|---|---|---|---|
| FP8 + 组卸载 | 9.264 GB | 14.232 GB | 58秒 |
✅ 显存最小化方案,代价是推理时间增加。
3. torch.compile 加速
另一种补充方法是使用 PyTorch 2.x 的 torch.compile() 功能加速模型执行。编译模型不会直接降低内存使用,但可以显著加快推理速度。PyTorch 2.0 的编译(Torch Dynamo)通过提前跟踪和优化模型图来实现。
| torchao精度 | 加载后内存 | 峰值内存 | 推理时间 | 编译耗时 |
|---|---|---|---|---|
| int4_weight_only | 10.635 GB | 15.238 GB | 6秒 | ~285秒 |
| int8_weight_only | 17.020 GB | 22.473 GB | 8秒 | ~851秒 |
| float8_weight_only | 17.016 GB | 22.115 GB | 8秒 | ~545秒 |
✅ 可大幅缩短推理时间,适合长期运行任务。
四、总结:选择最适合你的量化方案
| 方案 | 内存最小 | 推理最快 | 易用性 | 备注 |
|---|---|---|---|---|
| BnB 4位 | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | 最常用,效果稳定 |
| torchao int4 | ⭐⭐⭐⭐ | ⭐ | ⭐⭐ | 内存最优,速度慢 |
| Quanto INT4 | ⭐⭐⭐ | ⭐ | ⭐⭐⭐ | 集成好,适合Hugging Face用户 |
| GGUF Q2_k | ⭐⭐⭐ | ⭐⭐ | ⭐⭐ | 离线部署友好 |
| FP8 + 组卸载 | ⭐⭐⭐⭐ | ⭐ | ⭐⭐⭐ | 极致内存压缩 |
根据你的使用场景选择合适的组合,就能在资源受限的情况下,依然获得不错的生成效果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











