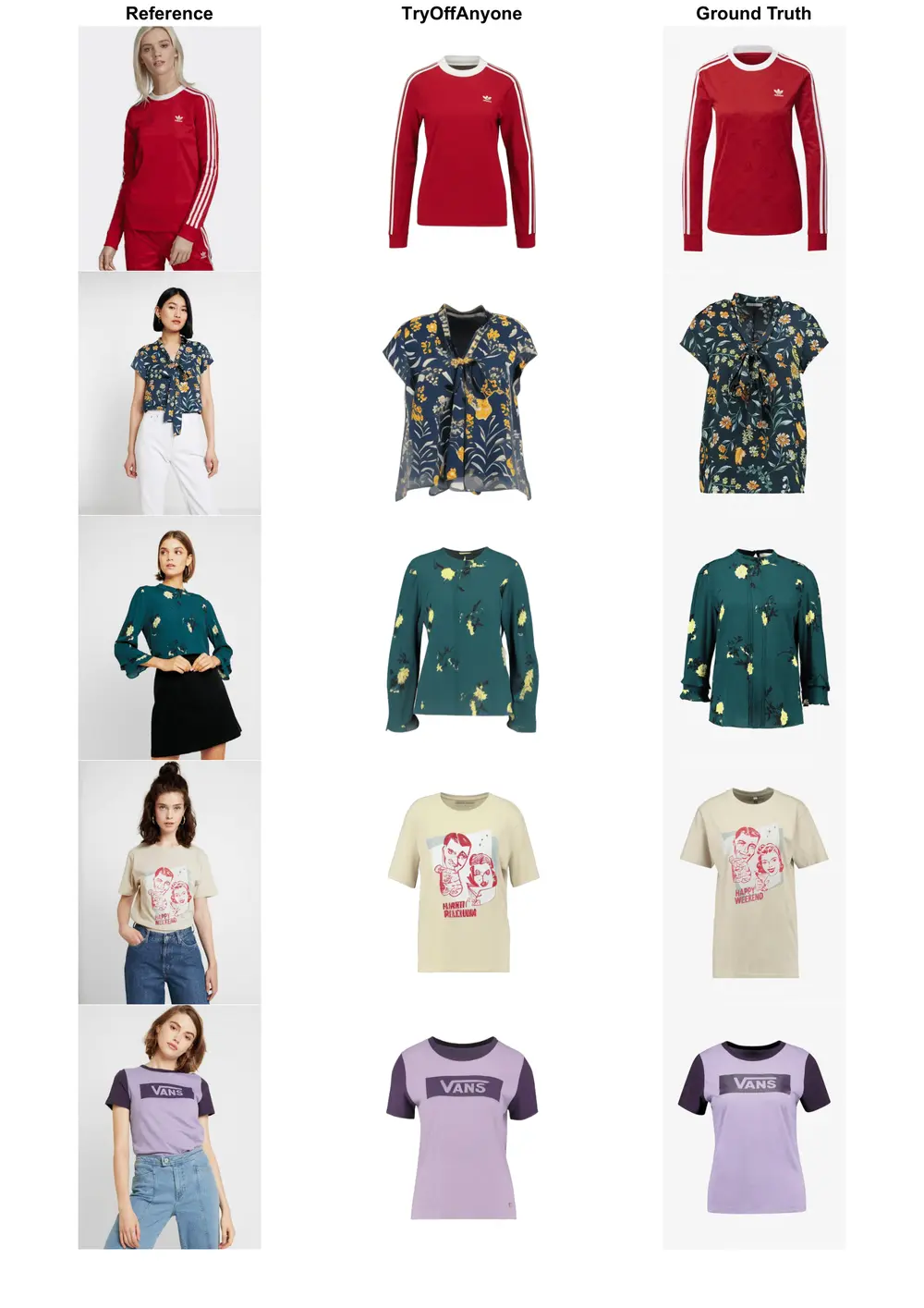
虚拟脱衣TryOffAnyone:从穿着服装的人身上生成高保真平铺服装图像多伦多大学和帕特雷大学的研究人员推出TryOffAnyone,这是一个从穿着服装的人身上生成高保真平铺服装图像的技术。这项技术对于时尚行业来说非常重要,因为它可以增强在线购物体验,提供个性化推荐、服装...新技术# TryOffAnyone# 虚拟脱衣1年前09010
视频流翻译方法Live2Diff:专为直播视频转换设计的时间单向注意力视频扩散模型上海人工智能实验室、马克斯普朗克信息研究所和南洋理工大学的研究人员推出视频流翻译方法Live2Diff(LIVE2DIFF),它利用了单向注意力机制在视频扩散模型中,专门为直播视频流设计。这种方法的核...新技术# Live2Diff# 直播2年前09010
小冰推出Portrait4D-v2:创建出逼真的4D头部头像小冰推出Portrait4D-v2,它能够创建出逼真的4D头部头像。4D头像不仅具有三维的立体形状,还能随着时间变化而展示出不同的面部表情和头部动作,就像活生生的人一样。这项技术的应用前景非常广泛,比...新技术# 4D头部头像# Portrait4D-v22年前09000
虚拟服装试穿技术IDM-VTON:根据一个人的图片和一件衣服的图片,生成这个人穿上这件衣服的图像来自韩国科学技术院和OMNIOUS.AI的研究人员推出虚拟服装试穿技术IDM-VTON,该技术能够根据分别描绘人物和服装的图像对,渲染出人物穿着精选服装的视觉效果。虚拟试穿是一种计算机视觉技术,它可以...新技术# IDM-VTON# 虚拟服装试穿# 虚拟试穿2年前08970
视觉-语言适配器PaLM2-VAdapter:将传统的视觉编码器和大语言模型结合起来PaLM2-VAdapter模型的主要目的是更有效地连接视觉编码器和大语言模型,以提高它们之间的协同工作效果。 论文 它能够有效地将传统的视觉编码器(vision encoders)和大语言模型(LL...新技术# PaLM2-VAdapter# 大语言模型# 视觉编码器2年前08970
AI视频编辑工具LAVE:利用大语言模型(LLMs)来辅助用户进行视频编辑来自加州大学圣地亚哥分校和Meta的研究人员推出AI视频编辑工具LAVE(LLM-Powered Agent Assistance and Language Augmentation for Vide...新技术# AI视频编辑# LAVE2年前08940
新型图像压缩技术CMC(模态压缩):利用大型多模态模型来实现图像到文本再到图像的转换,从而在保持图像质量的同时,大幅度减小图像的大小上海交通大学和南洋理工大学的研究人员推出一种新型的图像压缩技术“跨模态压缩”(Cross Modality Compression,简称CMC)。这项技术的核心思想是利用大型多模态模型(Large M...新技术# CMC# CMC-Bench# 图像压缩2年前08910
基于SAM的新型视觉模型Open-Vocabulary SAM:交互式的图像分割和识别来自南洋理工大学、上海AI实验室的研究人员推出了一款基于SAM的新型视觉模型Open-Vocabulary SAM,它结合了Segment Anything Model(SAM)和CLIP模型的优势...新技术# Open-Vocabulary SAM# SAM# 图像分割2年前08910
清华大学和新畅元科技推出Human4DiT:能够根据单幅图像及任意视点生成高质量、时空连贯的人类视频清华大学和新畅元科技推出新技术Human4DiT,它是一种用于生成高质量、时空一致的人类视频的4D扩散变换器(4D Diffusion Transformer)。这项技术可以从单张图片生成逼真的人类动...新技术# Human4DiT# 新畅元科技# 清华大学2年前08900
FontStudio系统:为多语言字体生成文字特效,创造具有艺术感的字体效果微软亚洲研究院和利物浦大学推出FontStudio系统,它是一个基于现代扩散模型的文本到图像生成系统,专门用来创造具有艺术感的字体效果。例如,你想在电脑上设计一个独特的字体,比如让字母'A'看起来像一...新技术# FontStudio# 字体2年前08890
新型图像生成模型EMMA:能够接受多模态提示,并生成高质量的图像南洋理工大学和腾讯的研究人员推出新型图像生成模型EMMA,它基于最先进的文本到图像(T2I)扩散模型ELLA,能够接受多模态提示(multi-modal prompts),并生成高质量的图像。简单来说...新技术# ELLA# EMMA# 图像生成2年前08890
IDEA研究院推出先进开集目标检测模型系列Grounding DINO 1.5:推动开放集对象检测技术的边界IDEA研究院(粤港澳大湾区数字经济研究院)推出先进模型系列Grounding DINO 1.5,旨在推动开放集对象检测技术的边界。开放集对象检测是一种计算机视觉任务,它要求模型能够识别图像中的对象...新技术# Grounding DINO 1.5# 开集目标检测模型2年前08870