创新框架MotionBooth:生成具有定制主体和可控主体及摄像机运动的动画视频北京大学、南洋理工大学、上海人工智能实验室、浙江大学和上海交通大学的研究人员推出创新框架MotionBooth,它专门用于生成具有定制主体和可控主体及摄像机运动的动画视频。简单来说,MotionBoo...新技术# MotionBooth2年前09770
基于指令的高质量图像编辑数据集HQ-Edit加州大学圣克鲁斯分校的研究人员推出高质量数据集HQ-Edit,它专门用于基于指令的图像编辑任务。例如,你有一张图片,想要根据某些具体的指令来修改它,比如改变背景、调整物体的颜色或者添加一些新元素。HQ...新技术# HQ-Edit# 图像编辑数据集2年前09770
开源人像生成器InstantID:只需一张人脸照片,快速生成不同风格的人物照片开源人像生成器InstantID今天在推特引发了热议,InstantID只需要一张人脸照片,就能快速生成多种风格的人物照片,无需复杂的训练或微调过程。InstantID还能与流行的图像扩散模型(如 S...新技术# controlnet# InstantID# LCM2年前09700
文生图模型GLIGEN:用于将Stable Diffusion模型扩展为可定制模型威斯康星大学麦迪逊分校、哥伦比亚大学和微软的研究人员推出的GLIGEN模型,用于将Stable Diffusion模型扩展为可定制的模型。这个模型的核心目标是让计算机能够根据文本描述生成图像,并且能够...新技术# GLIGEN# Stable Diffusion# 文生图模型2年前09690
新型图像抠图技术Matting by Generation:能够生成更高分辨率和细节丰富的抠像结果东京大学、合肥大学、Snap Research、阳明大学、香港中文大学、台湾大学和日本国立信息研究所的研究人员推出新型图像抠图技术Matting by Generation,图像抠图是指从一幅图片中精...新技术# Matting by Generation# 抠图2年前09620
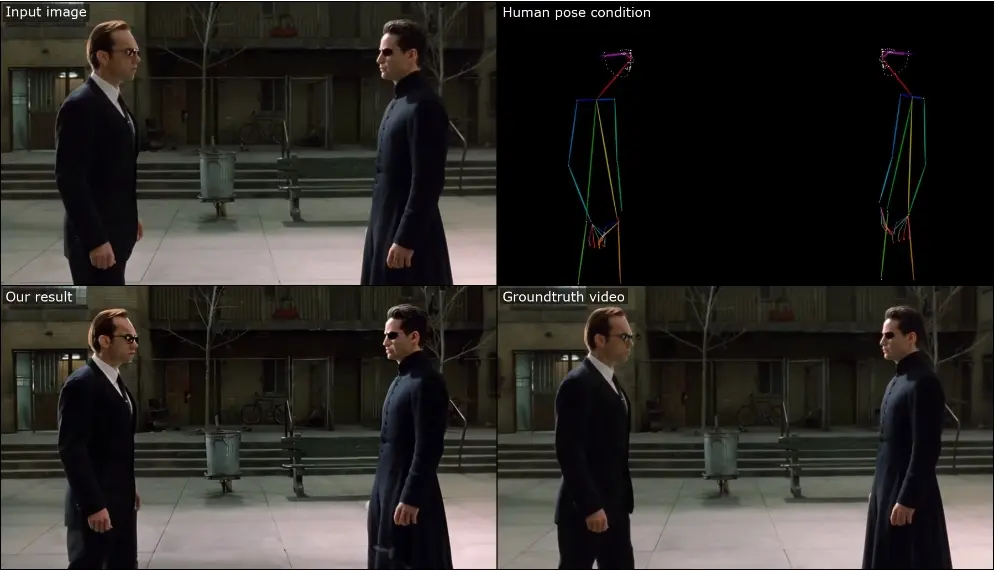
新型可控图像动画方法MOFA-Video:能够根据给定的图像和额外的可控信号(例如人体标记、手动轨迹或提供的其他视频)或它们的组合生成视频来自东京大学和腾讯AI实验室推出新型可控图像动画方法MOFA-Video,能够根据给定的图像和额外的可控信号(例如人体标记、手动轨迹或提供的其他视频)或它们的组合,从给定的图像中生成视频。这与以往的方...新技术# MOFA-Video# 可控图像动画生成2年前09580
通义千问视觉理解模型 Qwen-VL升级版:Qwen-VL-Plus、Qwen-VL-Max阿里云宣布通义千问视觉理解模型 Qwen-VL 再次升级,继 Plus 版本之后推出 Max 版本,升级版模型拥有更强的视觉推理能力和中文理解能力,能够根据图片识人、答题、创作、写代码,并在多个权威测...新技术# Qwen-VL-Max# Qwen-VL-Plus# 视觉理解模型2年前09540
不可混合扩散Immiscible Diffusion:加速扩散模型的训练过程加州大学伯克利分校和清华大学的研究人员推出新技术“Immiscible Diffusion(不可混合扩散)”,它旨在加速扩散模型的训练过程。扩散模型是一类在图像生成领域取得显著进展的模型,但它们的训练...新技术# Immiscible Diffusion# 扩散模型2年前09520
StreamMultiDiffusion:实时交互式图像生成和编辑的工具来自韩国首尔国立大学的团队发布新应用StreamMultiDiffusion,这是一种用于实时交互式图像生成和编辑的工具,这是将之前已发布的技术 MultiDiffusion + StreamDiff...新技术# StreamMultiDiffusion# 实时生图2年前09520
双语文本到图像生成模型Taiyi-Diffusion-XL,支持中文提示词IDEA 研究院是由沈向洋创立,他们在2021年11月22日宣布启动“封神榜”大模型开源体系。“封神榜”是由 IDEA-CCNL 的工程师、研究人员、实习生团队共同维护的一项长期开源计划。项目基于Ap...新技术# SDXL# Taiyi-Diffusion-XL# 中文提示词2年前09510
专为人体图像动画设计的大规模高质量数据集HumanVid:结合了精心挑选的真实世界数据和合成数据香港中文大学和上海人工智能实验室的研究人员推出HumanVid,它旨在揭开用于生成逼真人物视频动画的训练数据的神秘面纱。HumanVid是首个为人物图像动画量身定制的大规模、高质量的数据集,它结合了精...新技术# HumanVid2年前09490
一维(1D)标记化技术TiTok:用极少的标记(tokens)来表示和生成高分辨率图像字节跳动和慕尼黑工业大学的研究人员推出新型图像表示方法TiTok,它通过一种新颖的一维(1D)标记化技术,用极少的标记(tokens)来表示和生成高分辨率图像。这种方法与传统的二维(2D)图像标记化方...新技术# TiTok# 一维标记化2年前09460