图像和视频生成框架StoryDiffusion:能够生成一系列内容一致的图像和视频来自南开大学和字节跳动的研究人员推出一种新的图像和视频生成框架StoryDiffusion,这项技术的核心在于它能够生成一系列内容一致的图像和视频,这对于讲述一个故事或者展示一个连贯的场景来说非常重要...新技术# StoryDiffusion# 图像生成# 视频生成2年前08070
谷歌研究团队推出专为移动设备打造的文生图模型MobileDiffusion谷歌的研究团队推出了新的文生图模型MobileDiffusion,它能够在手机上几乎瞬间(亚秒级)生成高质量的图片。该模型在架构和采样技术方面进行广泛优化,在iPhone 15 Pro上,Mobile...新技术# MobileDiffusion# 安卓# 扩散模型2年前08050
视频增强技术Noise Calibration(噪声校准):使用预训练的视频扩散模型来改善视频质量,同时确保原始视频的内容保持不变大连理工大学和腾讯AI实验室的研究人员推出视频增强技术“Noise Calibration(噪声校准)”,它使用预训练的视频扩散模型来改善视频质量,同时确保原始视频的内容保持不变。该技术通过少量迭代步...新技术# Noise Calibration# 噪声校准# 视频增强技术2年前08020
Anaconda安装教程Anaconda是一个跨平台的集成开发环境,可在Windows、Linux和macOS等操作系统上运行。Anaconda提供了一个强大的包管理器,称为conda。conda可以轻松地安装、更新和管理各...教程# Anaconda# Python# 虚拟环境2年前08010
合成语言-视觉数据集StableSemantics:专注于自然图像中的语义表示卡内基·梅隆大学的研究人员推出合成语言-视觉数据集StableSemantics,它专注于自然图像中的语义表示。简单来说,这个数据集旨在帮助计算机视觉系统更好地理解图像中的场景和对象的语义含义。它涵盖...新技术# StableSemantics# 合成语言-视觉数据集2年前07990
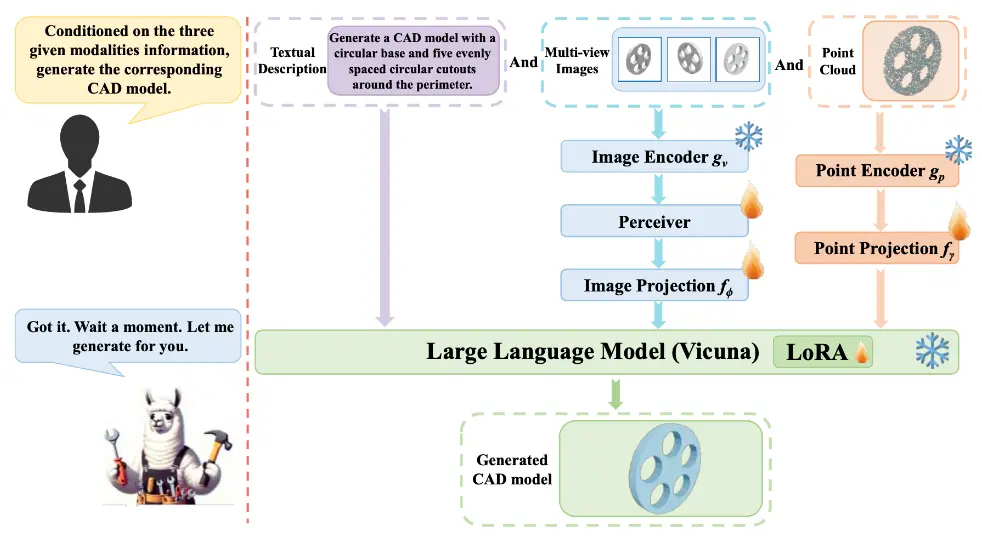
CAD-MLLM:实现一个统一的计算机辅助设计(CAD)模型生成系统上海科技大学、忆生科技、深度求索(DeepSeek-AI)和香港大学的研究人员推出一个名为“CAD-MLLM”的系统,它旨在实现一个统一的计算机辅助设计(CAD)模型生成系统。该系统能够根据用户的多种...新技术# CAD# CAD-MLLM1年前07980
视频合成模型后续调优方法ExVideo:提升模型生成视频的长度和质量华东师范大学和阿里巴巴的研究人员推出新型视频合成模型扩展方法ExVideo,这种方法旨在通过参数高效的方式对现有的视频合成模型(Stable Video Diffusion)进行后期调整(post-t...新技术# ExVideo# SVD模型2年前07980
Meta发布世界模型早期版本V-JEPA:无需人工标注或指导,自主学习视频中的视觉信息Meta今日推出V-JEPA(Video Joint-Embedding Predictive Architecture)模型,一种通过观看视频来教机器理解和模拟物理世界的方法,以迈向利用对世界的学习...新技术# Meta# V-JEPA# 世界模型2年前07980
图像超分辨率技术StableSR:将低分辨率的图像转换为高分辨率的图像StableSR是来自南洋理工大学S实验室的研究人员开发的图像超分辨率技术,它可以将低分辨率的图像转换为高分辨率的图像。简单来说,这项技术可以让你看到的图片变得更加清晰和详细。 我们可以用一个生活中的...新技术# StableSR# 超分辨率2年前07980
基于IMUs的面部捕捉系统IMUSIC:适用于多种场景,尤其是在视觉捕捉受限的情况下来自上海科技大学、灵秘科技、影眸科技和ElanTech的研究人员推出了一种创新面部捕捉系统IMUSIC,它基于惯性测量单元(IMUs)来捕捉面部表情,而不是依赖于传统的视觉输入。IMUSIC的设计旨在...新技术# IMUSIC# 影眸科技# 灵秘科技2年前07970
步态感知偏好优化SPO:改进SD模型的训练过程,使其生成的图像更符合人类的审美偏好来自澳大利亚国立大学、利物浦大学、东南大学和微软亚洲研究院的研究人员推出新技术Step-aware Preference Optimization(SPO,步态感知偏好优化),用于改进文本到图像的扩散...新技术# SD模型# SPO# 步态感知偏好优化2年前07960
图像高清修复技术SUPIR:将低质量图像提升到高质量水平来自中国科学院深圳先进技术学院、上海AI实验室、悉尼大学、香港理工大学、,腾讯PCG ARC实验室、香港中文大学的研究人员推出图像高清修复技术SUPIR(Scaling-UP Image Restor...新技术# SUPIR# 高清修复2年前07940