高度一致且可控制运动的图像动画生成方法Cinemo:将一张静态图片转换成一段视频,并且在转换过程中保持图片原有的细节信息莫纳什大学、上海人工智能实验室和南京邮电大学的研究人员推出Cinemo,它是一种用于图像动画化(也称为图像到视频生成,I2V)的新型方法。简单来说,Cinemo能够将一张静态图片转换成一段视频,并且在...新技术# Cinemo# 图像动画1年前06200
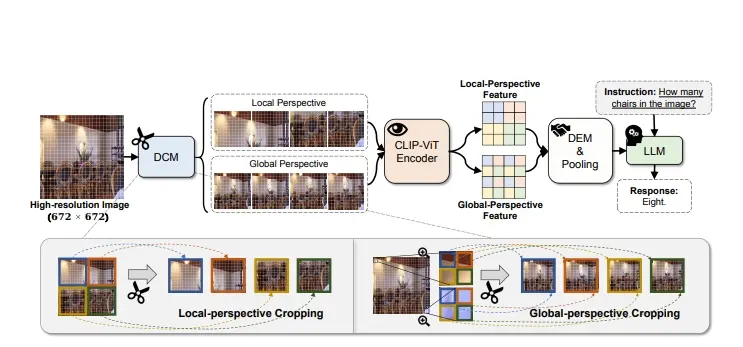
新型多模态大语言模型INF-LLaVA:专门设计用于处理高分辨率图像,以提高模型对视觉和语言信息的理解能力厦门大学的研究人员推出新型多模态大语言模型INF-LLaVA,它专门设计用于处理高分辨率图像,以提高模型对视觉和语言信息的理解能力。在人工智能领域,处理高分辨率图像一直是一个挑战,因为这些图像包含的细...新技术# INF-LLaVA# 多模态大语言模型1年前06200
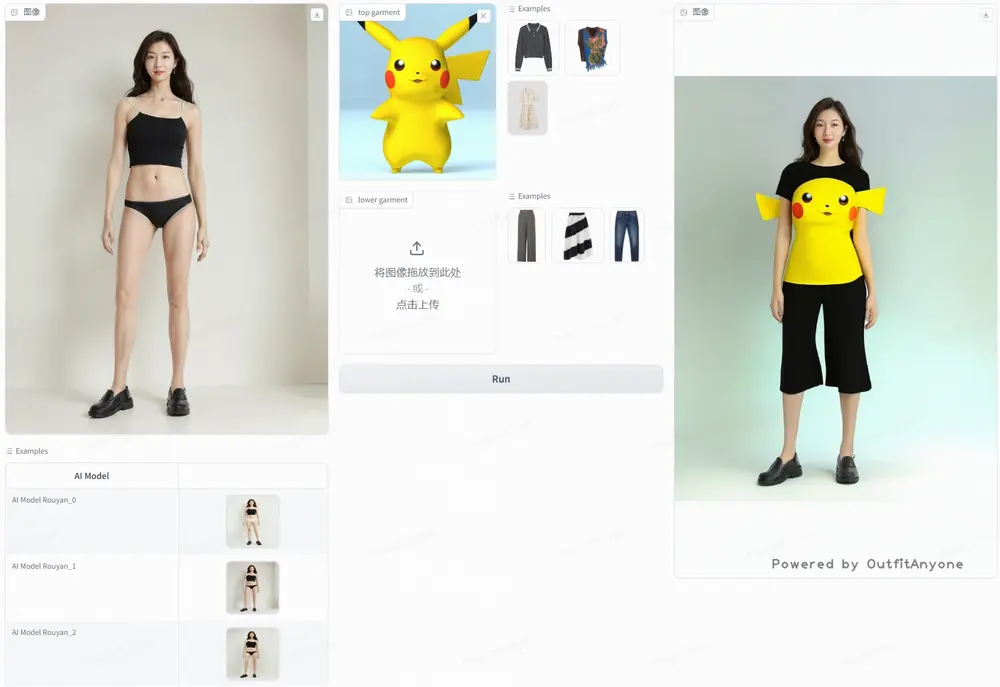
基于扩散模型的2D虚拟试穿框架OutfitAnyone:通过上传自己的照片和想要试穿的衣服图片,就能在线看到衣服穿在自己身上的样子阿里巴巴和中国科学技术大学的研究人员推出新的虚拟试穿技术OutfitAnyone,它是一个基于扩散模型的2D虚拟试穿框架。Outfit Anyone 通过利用双流条件扩散模型解决了这些局限性,使其能够...新技术# OutfitAnyone# 虚拟试穿1年前05070
新型视频生成框架MovieDreamer:专门用于制作长篇视频内容,比如电影浙江大学和阿里巴巴的研究人员推出新型视频生成框架MovieDreamer,专门用于制作长篇视频内容,比如电影。与传统的短时视频生成技术不同,MovieDreamer能够处理复杂的叙事结构和情节发展,同...新技术# MovieDreamer# 视频生成框架1年前08800
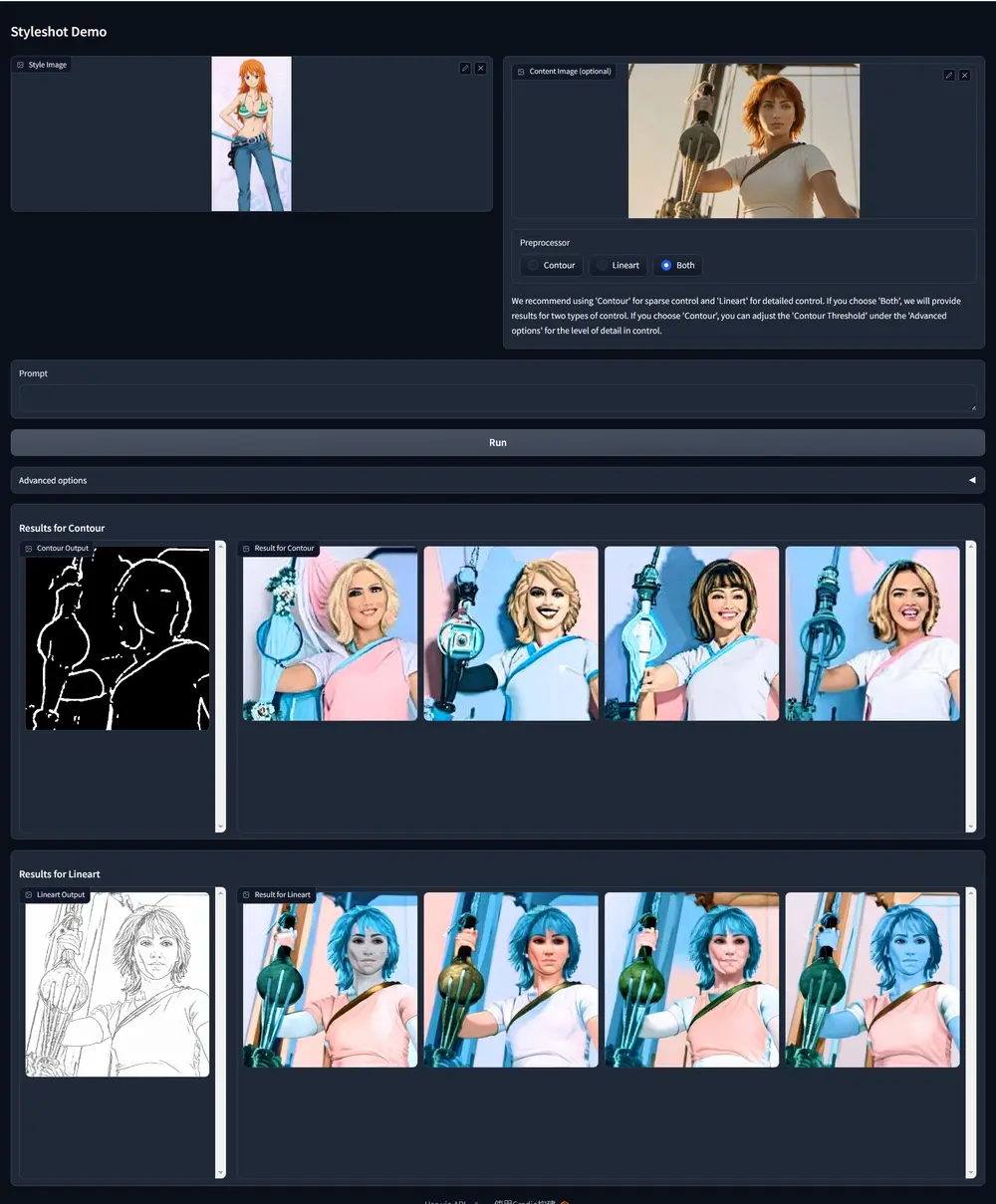
新型图像风格转换方法StyleShot:能够将任何图片转换成我们想要的几乎任何风格同济大学和上海人工智能实验室的研究人员推出新型图像风格转换方法StyleShot,StyleShot能够将任何图片转换成我们想要的几乎任何风格,比如3D、平面、抽象或者精细风格,而且转换过程中不需要在...新技术# StyleShot# 图像风格转换1年前05590
影眸科技推出新型大型3D生成模型CLAY:帮助人们将脑海中的创意轻松转化为精细的三维数字结构上海科技大学、影眸科技和华中科技大学的研究人员推出新型大型3D生成模型CLAY,它的主要任务是帮助人们将脑海中的创意轻松转化为精细的三维数字结构。就像孩子们用黏土塑造出各种形状的物体一样,CLAY能够...新技术# 3D生成模型# CLAY# 影眸科技1年前01,0300
虚拟试衣系统IMAGDressing-v1:帮助用户在线上购物时,更真实地预览服装在不同人身上的效果南京理工大学、华为、 腾讯人工智能实验室和南京大学的研究人员推出可定制的虚拟试衣系统IMAGDressing-v1,这个系统可以帮助用户在线上购物时,更真实地预览服装在不同人身上的效果。IMAGDre...新技术# IMAGDressing-v1# 虚拟穿搭# 虚拟试衣1年前08420
参照音频-视觉分割RefAVS:依据融合了多模态提示(包括音频和视觉描述)的自然语言表达,对视觉场景中的目标物进行分割中国人民大学、北京邮电大学和上海人工智能实验室的研究人员推出RefAVS(参照音频-视觉分割),依据融合了多模态提示(包括音频和视觉描述)的自然语言表达,对视觉场景中的目标物进行分割。研究团队还创建了...新技术# RefAVS# 参照音频-视觉分割1年前06370
针对姿势引导的人像图像动画技术TCAN:让图片中的人物根据某个动作序列(比如一个视频)来做出相应的动作韩国科学技术院和Naver的研究人员推出一种针对姿势引导的人像图像动画技术TCAN,该技术能有效抵抗姿态估计错误,并在时间维度上保持连贯。这是一个关于如何让静态图片中的人体动作起来的研究,具体来说,就...新技术# TCAN# 人像图像动画1年前06490
视频增强技术Noise Calibration(噪声校准):使用预训练的视频扩散模型来改善视频质量,同时确保原始视频的内容保持不变大连理工大学和腾讯AI实验室的研究人员推出视频增强技术“Noise Calibration(噪声校准)”,它使用预训练的视频扩散模型来改善视频质量,同时确保原始视频的内容保持不变。该技术通过少量迭代步...新技术# Noise Calibration# 噪声校准# 视频增强技术1年前07540
E2GAN:用于图像到图像翻译的高效训练和推理的生成对抗网络(GAN)模型Snap和东北大学的研究人员推出E2GAN,这是一种用于图像到图像翻译的高效训练和推理的生成对抗网络(GAN)模型。简单来说,E2GAN的目标是让计算机能够通过学习大量图像数据,快速生成或编辑出符合特...新技术# E2GAN# 生成对抗网络(GAN)模型1年前04840
视频流翻译方法Live2Diff:专为直播视频转换设计的时间单向注意力视频扩散模型上海人工智能实验室、马克斯普朗克信息研究所和南洋理工大学的研究人员推出视频流翻译方法Live2Diff(LIVE2DIFF),它利用了单向注意力机制在视频扩散模型中,专门为直播视频流设计。这种方法的核...新技术# Live2Diff# 直播1年前08110