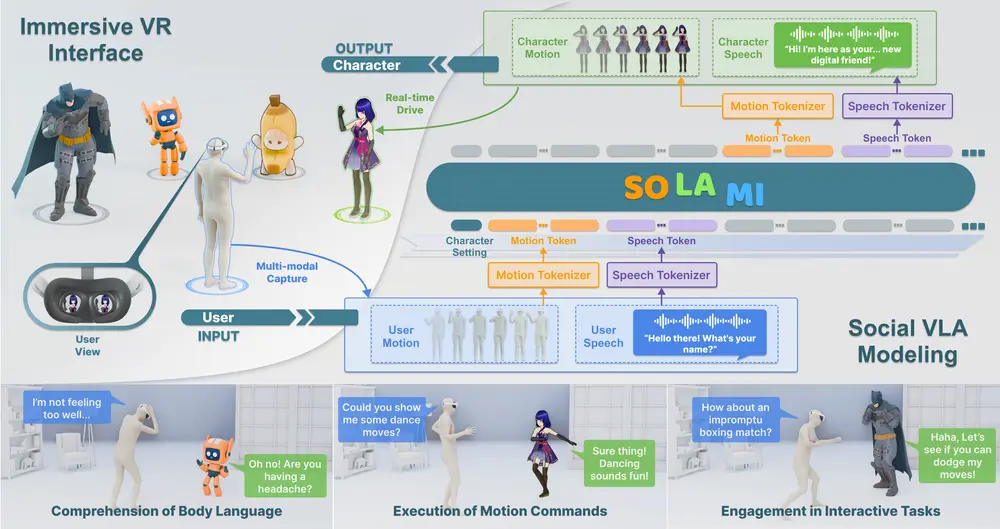
SOLAMI:为3D自主角色提供社交智能,使其能够感知、理解和与人类进行交互。人类是社会性动物,赋予3D自主角色类似的社会智能,使其能够感知、理解和与人类互动,是一个开放且基础的问题。商汤科技研究院和南洋理工大学的研究人员提出了SOLAMI,这是第一个端到端的社交视觉-语言-动...新技术# SOLAMI1年前02670
SPOTLIGHT:通过扩散模型实现对虚拟对象插入图像时的光影控制拉瓦尔大学、Depix Technologies和芝加哥丰田技术学院的研究人员推出SPOTLIGHT,它用于通过扩散模型实现对虚拟对象插入图像时的光影控制。这种方法的核心在于,通过指定对象的期望阴影...新技术# SPOTLIGHT1年前02890
无需额外训练的缓存策略TeaCache:加速视频扩散模型的推理过程,同时保持生成视频的视觉质量扩散模型(DMs)作为视频生成的基本骨干,因其顺序去噪的性质而面临低推理速度的挑战。尽管先前的方法通过在均匀选择的时间步长上缓存和重用模型输出来加速模型,但这种策略忽略了模型输出在不同时间步长上的差异...新技术# TeaCache# 缓存策略1年前04850
新型采样引导方法STG:提升视频扩散模型生成质量扩散模型(DMs)近年来在生成高质量图像、视频和3D内容方面取得了显著进展。然而,现有的采样引导技术如分类器引导(CFG)虽然提高了生成内容的质量,但也带来了多样性和运动性的下降。自动引导方法虽然缓解...新技术# STG1年前02920
RollingDepth:将单图像深度估计转化为高效的视频深度估计随着大型基础模型的发展和合成训练数据的广泛应用,单图像深度估计技术取得了显著进展,这重新激发了研究者对视频深度估计的兴趣。然而,直接将单图像深度估计器应用于视频每一帧的方法存在明显缺陷,如时间连续性忽...新技术# RollingDepth# 视频深度1年前02880
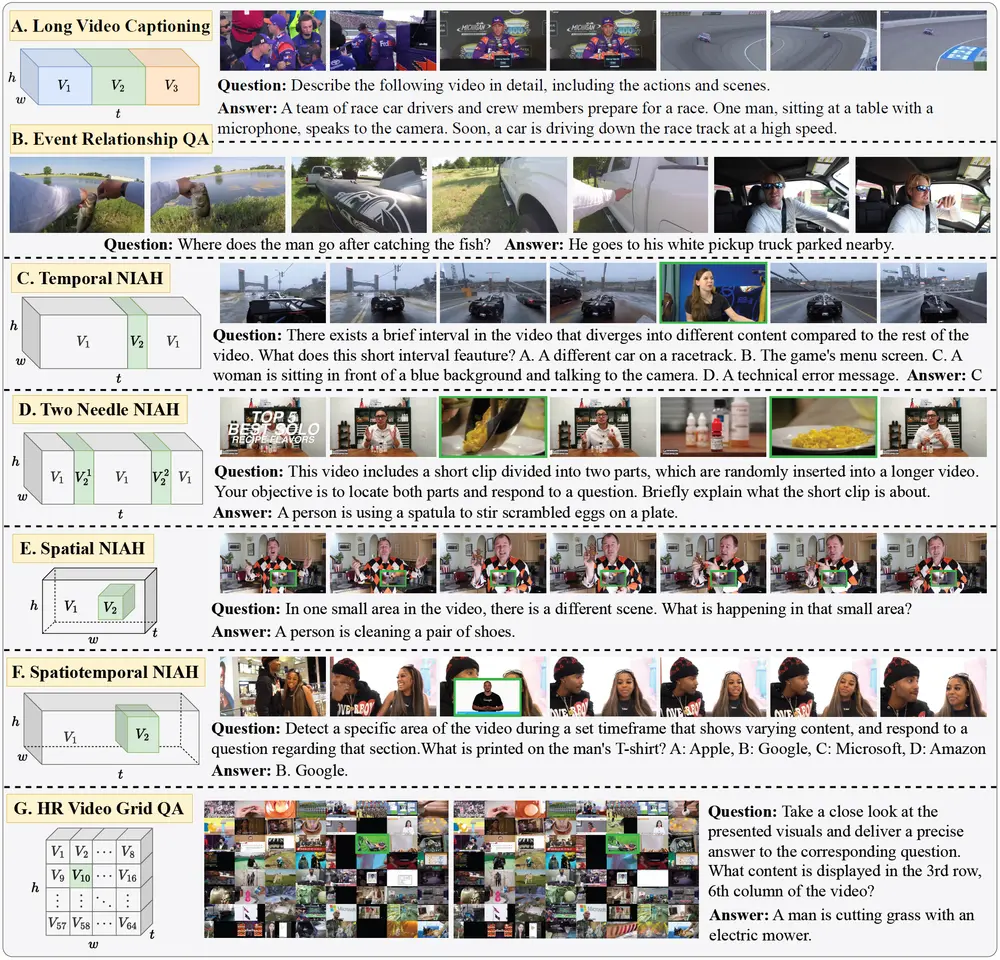
VISTA框架:通过视频时空增强技术,提升对长时和高分辨率视频的理解能力滑铁卢大学、矢量研究所和零一万物的研究人员推出VISTA框架,旨在通过视频时空增强技术,提升对长时和高分辨率视频的理解能力。VISTA通过从现有的视频-字幕数据集中合成长时和高分辨率视频指令对,以增强...新技术# VISTA1年前02720
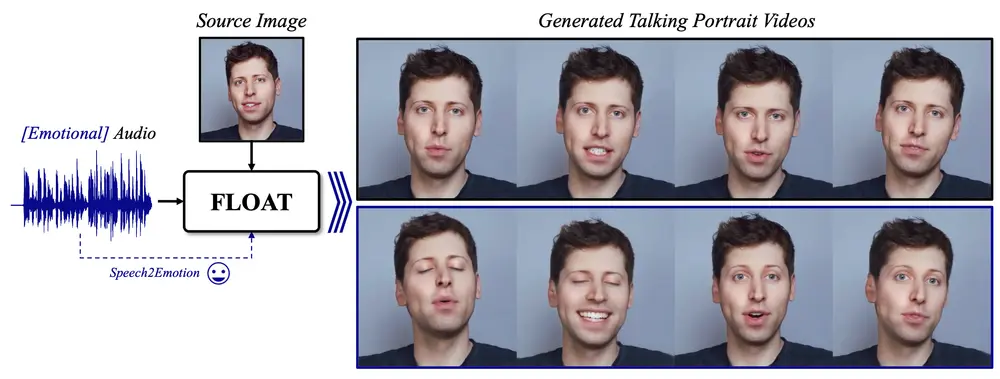
新型音频驱动的肖像视频生成方法FLOAT:基于流匹配生成模型,能够在给定单一源图像和音频的情况下生成具有自然说话动作的肖像视频DeepBrain和韩国科学技术院人工智能研究生院的研究人员推出新型音频驱动的肖像视频生成方法FLOAT,它基于流匹配生成模型,能够在给定单一源图像和音频的情况下生成具有自然说话动作的肖像视频。FLO...新技术# FLOAT# 肖像视频1年前02470
FlowChef:利用矢量场动力学的统一受控图像生成框架扩散模型(DMs)在照片真实感图像生成、图像编辑和逆问题解决方面取得了显著进展,这主要归功于无分类器引导和图像反演技术。然而,校正流模型(RFMs)在这类任务中的潜力尚未得到充分开发。现有的基于DM的...新技术# FlowChef# 图像生成框架1年前03070
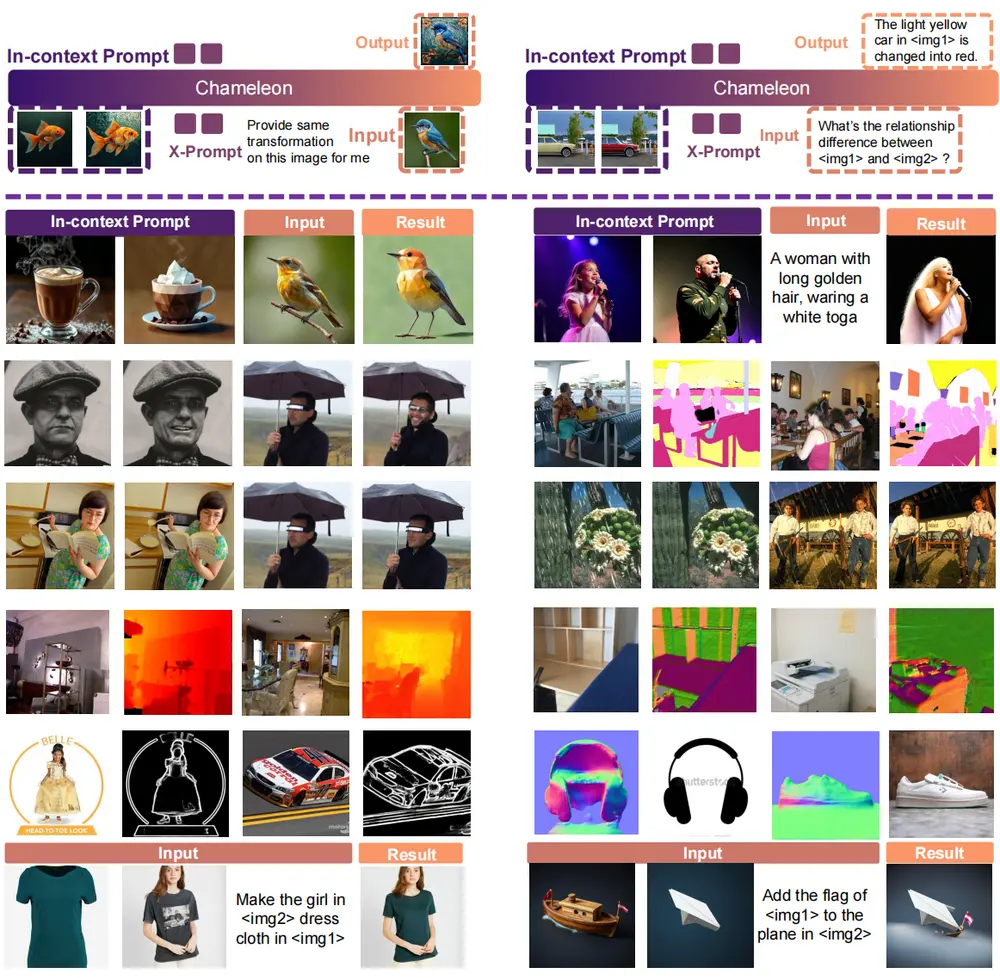
新型自回归视觉语言基础模型X-Prompt:实现通用的上下文内图像生成随着大语言模型(LLMs)在自然语言处理领域的广泛应用,基于LLMs的自动回归视觉语言模型(VLMs)在文本到图像生成方面也取得了显著进展。然而,上下文学习——即通过少量示例来指导模型执行特定任务的能...新技术# X-Prompt1年前02440
轻量级的新型视频对象分割和跟踪模型EfficientTAM随着视频对象分割(VOS)和跟踪任务的日益复杂,现有的强大工具如SAM 2虽然在准确性和功能上表现出色,但其高计算复杂性限制了其在移动设备等资源受限环境中的应用。为了解决这一问题,Meta和南洋理工大...新技术# EfficientTAM# 视频对象分割# 跟踪模型1年前02480
零一万物推出Presto:专为生成长达15秒的高质量视频而设计的新型扩散模型零一万物团队隆重推出Presto——一款专为生成长达15秒的高质量视频而设计的新型扩散模型。Presto旨在克服长时间视频生成中保持场景多样性和一致性的挑战,通过引入分段交叉注意力(Segmented...新技术# Presto# 零一万物1年前02780
新型自编码器WF-VAE:为提高潜在视频扩散模型中视频变分自编码器的性能而设计北大-兔展AIGC联合实验室推出新型自编码器WF-VAE,此编码器与开源视频生成项目Open-Sora Plan相关,它是为了提高潜在视频扩散模型(Latent Video Diffusion Mod...新技术# WF-VAE# 自编码器1年前02840