针对DiT模型的深度修剪方法TinyFusion:通过端到端学习去除冗余层,以减少模型的参数量和提高推理效率新加坡国立大学的研究人员推出一个针对DiT模型的深度修剪方法TinyFusion,旨在通过端到端学习去除冗余层,以减少模型的参数量和提高推理效率。DiT架构在图像生成领域展现出了卓越的能力,但通常伴随...新技术# DiT模型# TinyFusion1年前02780
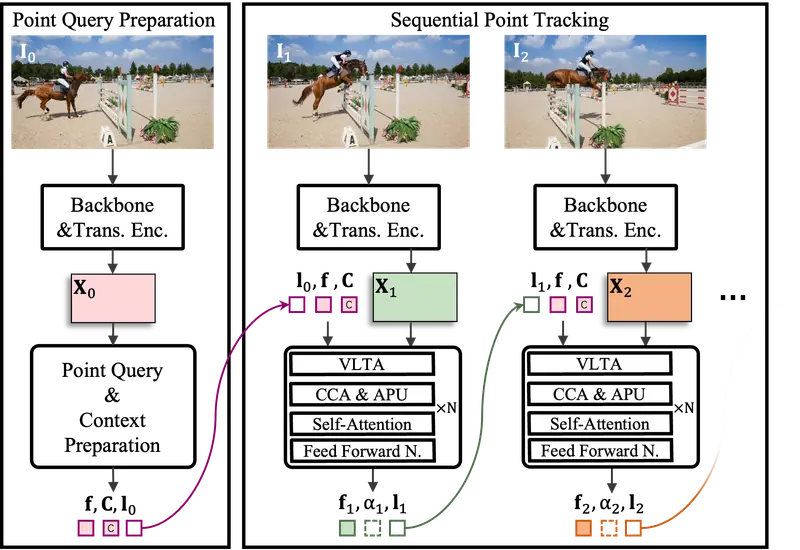
先进跟踪系统TAPTRv3:用于在长视频中跟踪任意点IDEA Research、华南理工大学、清华大学和香港科技大学的研究人员推出先进跟踪系统TAPTRv3,它专门设计用于在长视频中跟踪任意点。TAPTRv3是建立在TAPTRv2基础上的,主要目标是提...新技术# TAPTRv31年前02980
PSHuman:利用多视角扩散模型先验的3D人体建模新框架真实感3D人体建模在虚拟现实、增强现实、电影制作、游戏开发和医疗等领域具有广泛的应用。尽管单目全身重建方法取得了显著进展,但它们通常依赖于前视图和/或预测的后视图,这导致了由于问题的病态性质和复杂的自...新技术# 3D人体建模# PSHuman1年前03140
可控人类图像生成的新框架BootComp:特别适用于包含多个参考服装的情况韩国科学技术研究院和OMNIOUS.AI的研究人员提出了BootComp——一种用于可控人类图像生成的新框架,特别适用于包含多个参考服装的情况。这一创新解决了训练数据获取的主要瓶颈,即为每个人类主体收...新技术# BootComp1年前02970
基于扩散模型的人类视频生成框架AnchorCrafter:用于创建高保真度的主播风格产品推广视频。自动生成锚点风格的产品推广视频在在线商务、广告和消费者互动中展现出巨大的潜力。然而,尽管姿态引导的人类视频生成技术取得了显著进展,这一任务仍然充满挑战。特别是将人-物交互(Human-Object I...新技术# AnchorCrafter# 视频生成1年前03030
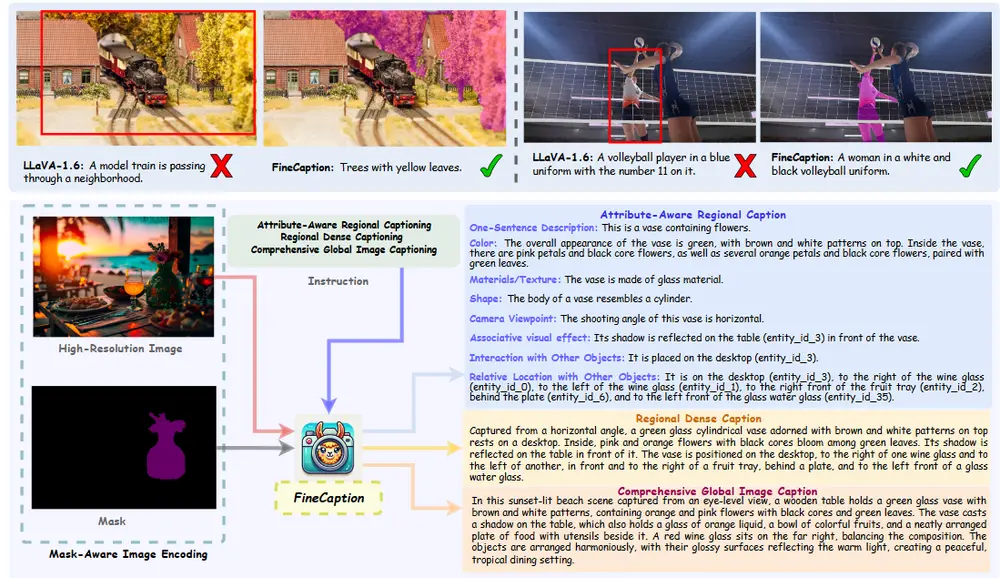
视觉-语言模型FINECAPTION:专注于在任意位置和任意粒度级别上进行组合式图像描述随着大型视觉语言模型(VLMs)的出现,多模态任务的发展取得了显著进展。这些模型在图像和视频字幕、视觉问答以及跨模态检索等应用中展现了强大的推理能力。然而,尽管VLMs具有卓越的表现,它们在细粒度图像...新技术# FINECAPTION# 视觉-语言模型1年前03150
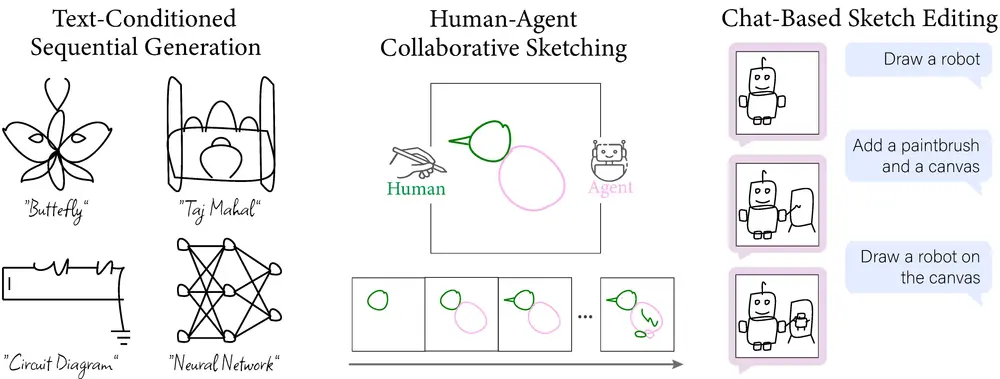
语言驱动的顺序草图生成方法SketchAgent:让用户通过动态、对话式的交互来创建、修改和细化草图MIT和斯坦福大学的研究人员推出一种语言驱动的顺序草图生成方法SketchAgent,能够让用户通过动态、对话式的交互来创建、修改和细化草图。例如,你想要生成一个关于“蝴蝶”的草图。你可以给Sketc...新技术# SketchAgent# 草图1年前03380
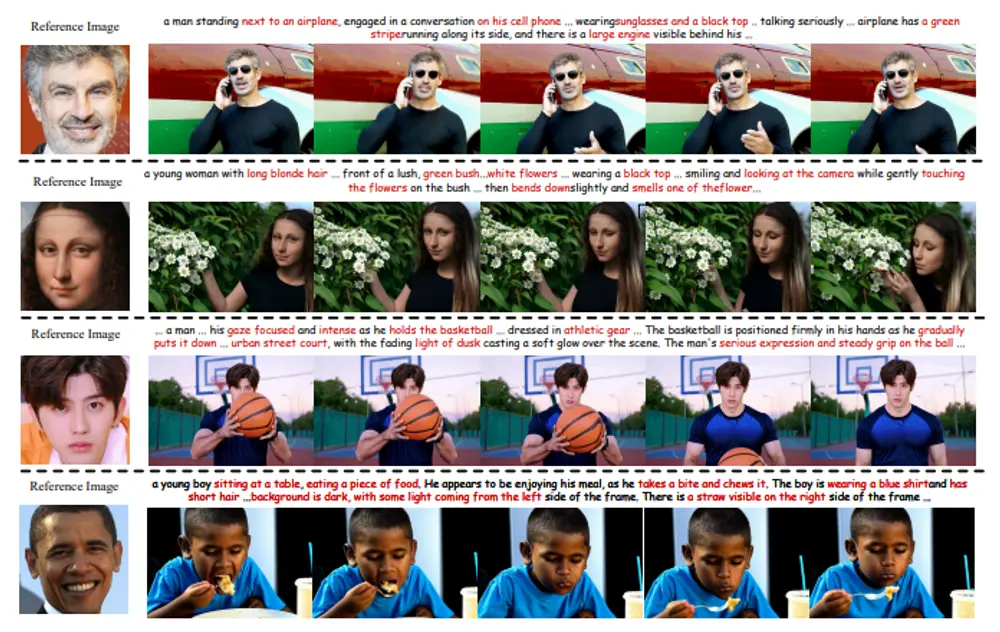
ConsisID:无调优可控的身份保持文本到视频生成身份保持的文本到视频(IPT2V)生成旨在创建具有一致人类身份的高保真视频,这是视频生成领域的重要任务之一。然而,生成模型在这一方面仍然面临诸多挑战。北京大学、鹏城实验室、罗切斯特大学和新加坡国立大学...新技术# ConsisID1年前02850
用于保护个人肖像图像免受恶意生成编辑的新技术FaceLock随着扩散模型的迅速发展,生成图像编辑变得更加普及,这不仅促进了创意表达,也引发了严重的伦理问题。特别是对人类肖像的恶意编辑,如深度伪造(deepfake)技术,威胁到了个人隐私和身份安全。为了应对这一...新技术# FaceLock1年前02570
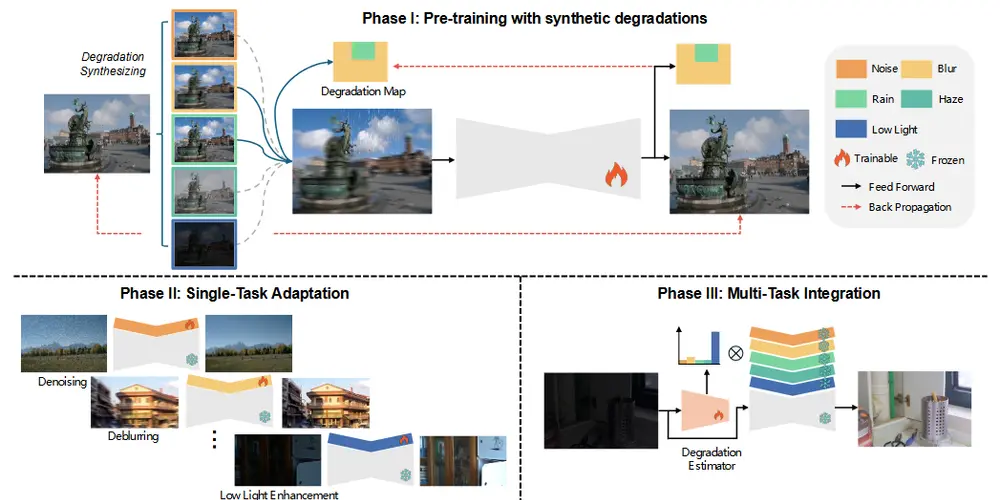
图像修复模型ABAIR:在从受到未知退化影响的输入图像中恢复出高质量的图像在图像处理领域,盲目的全功能图像恢复(Blind All-in-One Image Restoration, BAIR)旨在从未知失真退化的输入中恢复高质量的图像。然而,传统方法在训练阶段需要预先定义...新技术# ABAIR模型1年前02680
Omegance:用于控制基于扩散模型合成中细节粒度(granularity)的单一参数方法南洋理工大学额研究人员推出Omegance,它是一种用于控制基于扩散模型合成中细节粒度(granularity)的单一参数方法。Omegance通过在扩散模型的反向去噪步骤中引入一个参数ω(omega...新技术# Omegance1年前02630
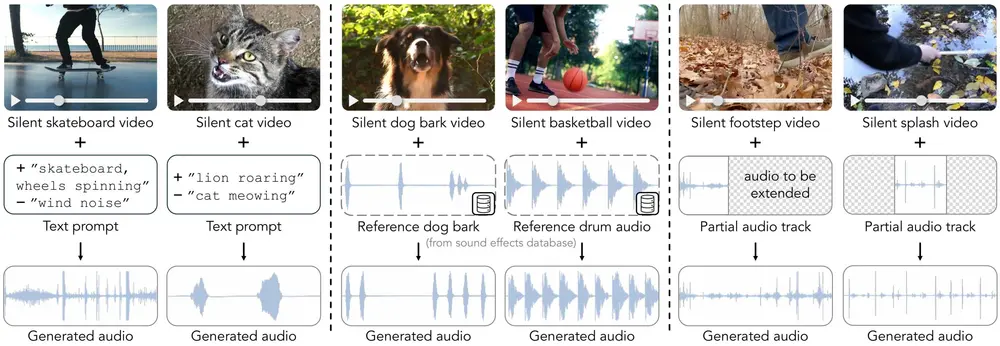
视频引导音效生成模型MultiFoley:根据多种模态的控制信号(包括文本、音频和视频)来生成与视频同步的声音效果在影视制作、游戏开发和多媒体内容创作中,为视频添加恰当的音效是提升观众体验的重要环节。然而,创造既符合视觉场景又具有艺术感的音效往往需要耗费大量时间和专业技能。为了应对这一挑战,密歇根大学与Adobe...新技术# MultiFoley# 视频引导音效生成模型1年前02830