PSHuman:利用多视角扩散模型先验的3D人体建模新框架真实感3D人体建模在虚拟现实、增强现实、电影制作、游戏开发和医疗等领域具有广泛的应用。尽管单目全身重建方法取得了显著进展,但它们通常依赖于前视图和/或预测的后视图,这导致了由于问题的病态性质和复杂的自...新技术# 3D人体建模# PSHuman1年前03240
3D高效框架Make-It-Animatable:将任意3D人物模型快速制作成可用于动画的角色中国科学技术大学和腾讯的研究人员推出高效框架Make-It-Animatable,它用于将任意3D人物模型快速制作成可用于动画的角色。这个框架能够在不到一秒钟的时间内,无论3D模型的形状和姿势如何,都...新技术# 3D# Make-It-Animatable1年前03240
ViewExtrapolator:于在新视角合成领域中进行新视角外推南洋理工大学和中国科学院大学的研究人员推出一个名为ViewExtrapolator的新方法,它用于在新视角合成(novel view synthesis, NVS)领域中进行新视角外推(novel v...新技术# ViewExtrapolator1年前03240
文生图模型SnapGen:能够在移动平台上生成高分辨率和高品质的图像现有的文本到图像(T2I)扩散模型虽然在生成高质量图像方面表现出色,但面临着几个关键挑战: 模型尺寸大:许多先进的T2I模型包含数十亿个参数,导致存储和部署成本高昂。 运行时间慢:生成高分辨率图像通常...新技术# SnapGen# 文生图模型1年前03230
原生FP4训练框架 Quartet:通过在低精度( FP4)下进行高效的端到端训练,显著提升大语言模型(LLMs)的训练效率和性能ISTA和苏黎世联邦理工学院的研究人员推出原生FP4训练框架 Quartet,通过在低精度( FP4)下进行高效的端到端训练,显著提升大语言模型(LLMs)的训练效率和性能,二之前DeepSeek R...新技术# FP4训练框架# Quartet10个月前03210
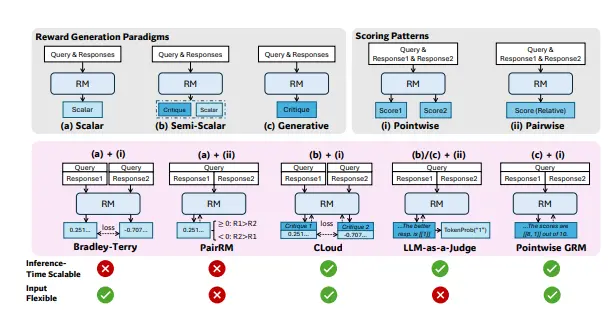
通过推理计算来提高通用奖励建模(RM)的推理时间可扩展性强化学习(RL)在大语言模型(LLM)的后续训练中已被广泛应用,尤其是在提升模型的推理能力方面。然而,如何在各种领域中为LLM获得准确的奖励信号,仍然是一个关键挑战。 论文:https://arxiv...新技术# DeepSeek# 奖励建模# 清华大学12个月前03210
Track4Gen:用于视频生成的空间感知视频生成器Adobe 研究中心、韩国科学技术院和伦敦大学学院的研究人员推出Track4Gen,这是一个用于视频生成的空间感知视频生成器,它结合了视频扩散损失和跨帧点跟踪,提供了对扩散特征的空间监督,以增强视...新技术# Track4Gen1年前03210
腾讯推出新型视频分词器Divot:统一视频的理解和生成近年来,大语言模型(LLMs)在图像理解和生成方面取得了显著进展,尤其是在将图像编码为离散标记并结合LLMs进行多模态任务时。然而,将这一成功扩展到视频领域面临着更大的挑战,因为视频不仅包含空间信息...新技术# Divot# 视频分词器1年前03210
Motion Prompting框架:通过动轨迹控制视频生成Google DeepMind、密歇根大学和布朗大学的研究人员推出一个名为“Motion Prompting”的框架,它用于控制视频生成中的动作轨迹。该框架通过使用运动轨迹作为条件信号,来生成具有特定...新技术# Motion Prompting# 运动轨迹控1年前03210
先进跟踪系统TAPTRv3:用于在长视频中跟踪任意点IDEA Research、华南理工大学、清华大学和香港科技大学的研究人员推出先进跟踪系统TAPTRv3,它专门设计用于在长视频中跟踪任意点。TAPTRv3是建立在TAPTRv2基础上的,主要目标是提...新技术# TAPTRv31年前03200
基于图像扩散先验的深度修复模型DepthLab:从单张图像中生成完整的3D场景香港大学、香港科技大学、蚂蚁集团、阿尔托大学和通义实验室的研究人员推出DepthLab ,它是一个基于图像扩散先验的深度修复模型,用于从单张图像中生成完整的3D场景。DepthLab旨在解决深度数据中...新技术# 3D场景# DepthLab# 深度修复模型1年前03180
零一万物推出Presto:专为生成长达15秒的高质量视频而设计的新型扩散模型零一万物团队隆重推出Presto——一款专为生成长达15秒的高质量视频而设计的新型扩散模型。Presto旨在克服长时间视频生成中保持场景多样性和一致性的挑战,通过引入分段交叉注意力(Segmented...新技术# Presto# 零一万物1年前03170