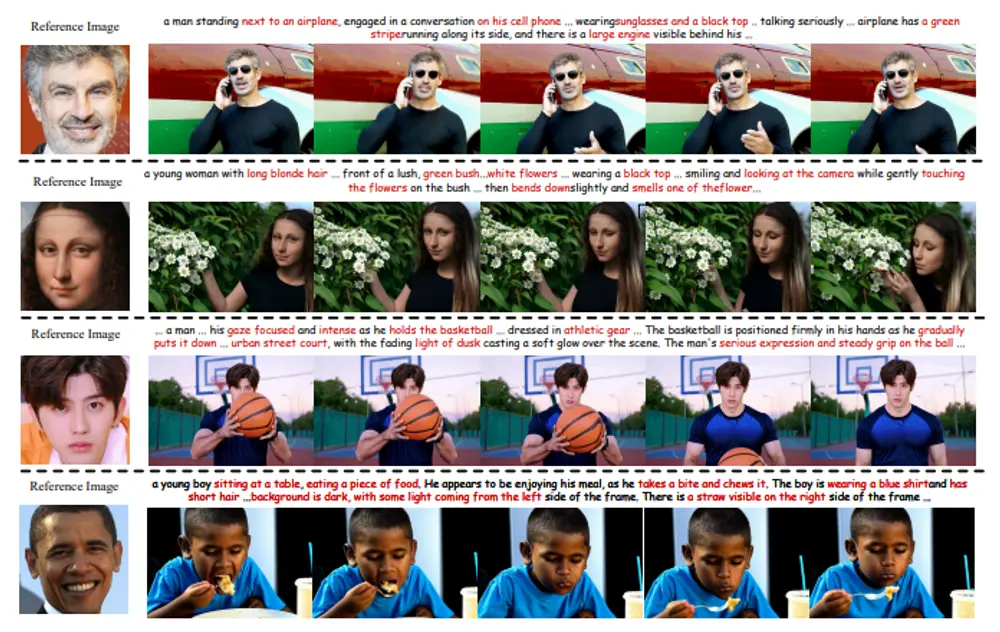
ConsisID:无调优可控的身份保持文本到视频生成身份保持的文本到视频(IPT2V)生成旨在创建具有一致人类身份的高保真视频,这是视频生成领域的重要任务之一。然而,生成模型在这一方面仍然面临诸多挑战。北京大学、鹏城实验室、罗切斯特大学和新加坡国立大学...新技术# ConsisID1年前03170
SageAttention2:适用于即插即用推理加速的精确4位注意力机制尽管线性层的量化技术已经广泛应用于深度学习模型中,但在加速注意力机制方面的应用仍然有限。为了提高注意力计算的效率并保持高精度,清华大学的研究团队提出了 SageAttention2,这是一个基于低精度...新技术# SageAttention2# 推理加速1年前03170
Self-Forcing++:一种无需长视频训练即可生成高质量长视频的新方法近年来,扩散模型在图像和短片视频生成方面取得了突破性进展。然而,当扩展到长视频生成(如数十秒甚至数分钟)时,现有方法普遍面临一个核心问题:质量随长度增加而显著下降。 这主要源于两个限制: 计算成本高...新技术# Self Forcing# 字节跳动5个月前03160
新型3D感知视频扩散方法DaS:实现对视频生成过程的多样化和精确控制香港科技大学、浙江大学、香港大学、南洋理工大学、武汉大学和德克萨斯农工大学的研究人员推出新型3D感知视频扩散方法“Diffusion as Shader(DaS)”,旨在实现对视频生成过程的多样化和精...新技术# DaS# 视频生成1年前03150
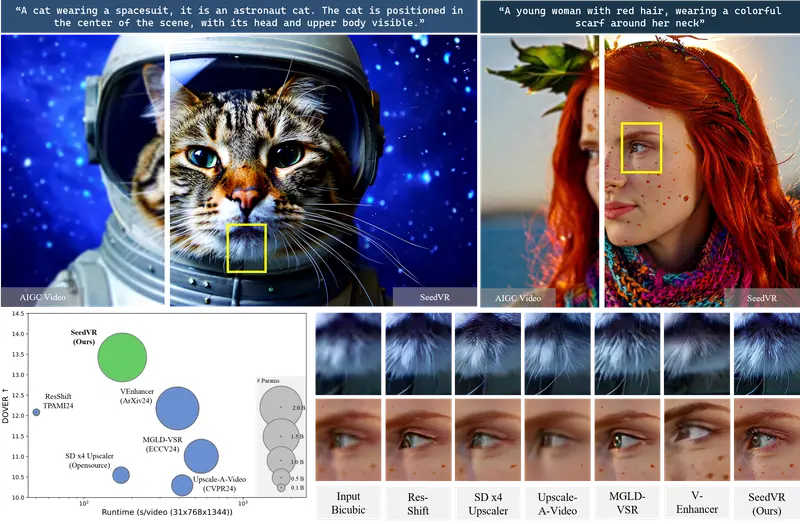
视频修复模型SeedVR:处理任意长度和分辨率的真实世界视频修复任务南洋理工大学和字节跳动的研究团队提出了 SeedVR,旨在解决通用视频恢复(video restoration,VR)中面临的挑战,即如何在处理未知退化的真实世界视频时,有效地恢复高质量视频并保持时间...新技术# SeedVR# 视频修复模型1年前03150
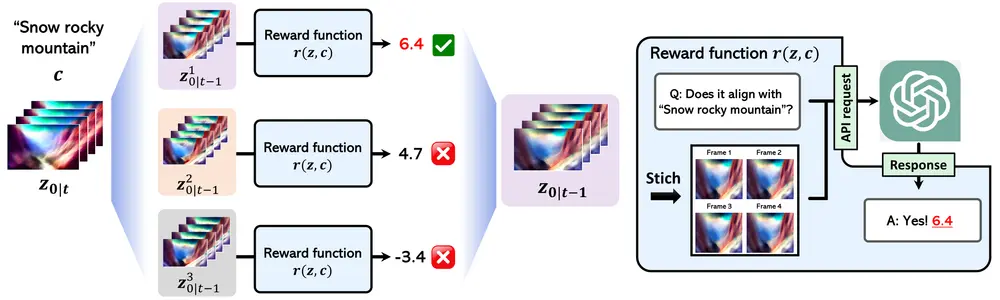
Free^2Guide:无梯度框架提升文本到视频(T2V)生成中的文本对齐扩散模型在文本到图像(T2I)和文本到视频(T2V)合成等生成任务中取得了显著成果。然而,在T2V生成中,实现准确的文本对齐仍然是一个具有挑战性的问题,尤其是在处理帧间复杂的时序依赖性时。现有的基于强...新技术# Free^2Guide# 视频生成1年前03150
索尼与韩国科学技术院联合推出 DesignLab:一种全新的AI驱动幻灯片优化框架对大多数人而言,制作一份美观、专业、信息清晰的演示文稿是一项令人头疼的任务。 排版混乱、配色突兀、字体不协调——这些问题并非源于内容不足,而是设计决策的复杂性超出了非专业人士的能力范围。 尽管已有不少...新技术# DesignLab# PPT8个月前03130
高通AI研究院推出专为移动设备优化的视频编辑模型MoViE:能够在手机上实现每秒12帧的快速视频编辑高通AI研究院推出一个专为移动设备优化的视频编辑模型MoViE,能够在手机上实现每秒12帧的快速视频编辑。MoViE通过一系列优化,使得在移动设备上进行视频编辑变得可行,这些优化包括架构优化、轻量级自...新技术# MoViE# 视频编辑模型# 高通1年前03130
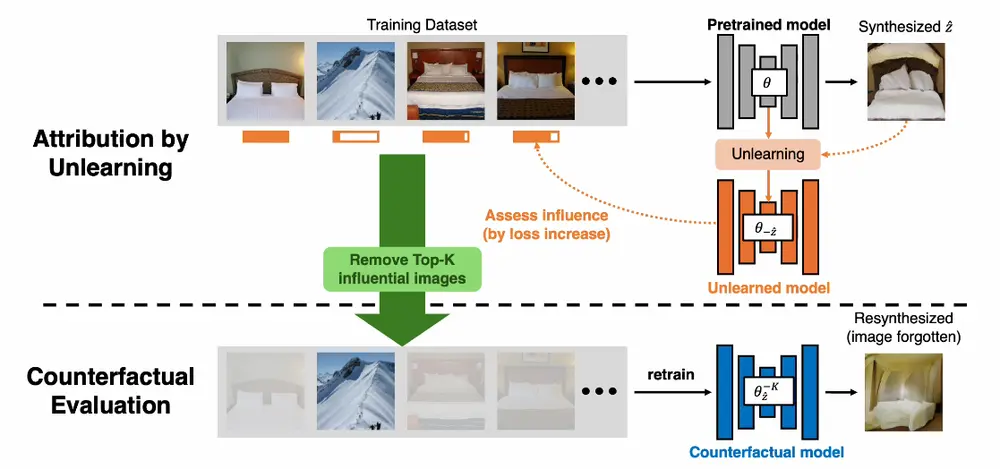
文本到图像模型的数据归因:识别在生成新图像过程中最具影响力的训练图像卡内基梅隆大学、Adobe 研究和加州大学伯克利分校的研究人员发布论文,论文的主题是关于文本到图像模型的数据归因(Data Attribution for Text-to-Image Models...新技术# 文生图模型1年前03130
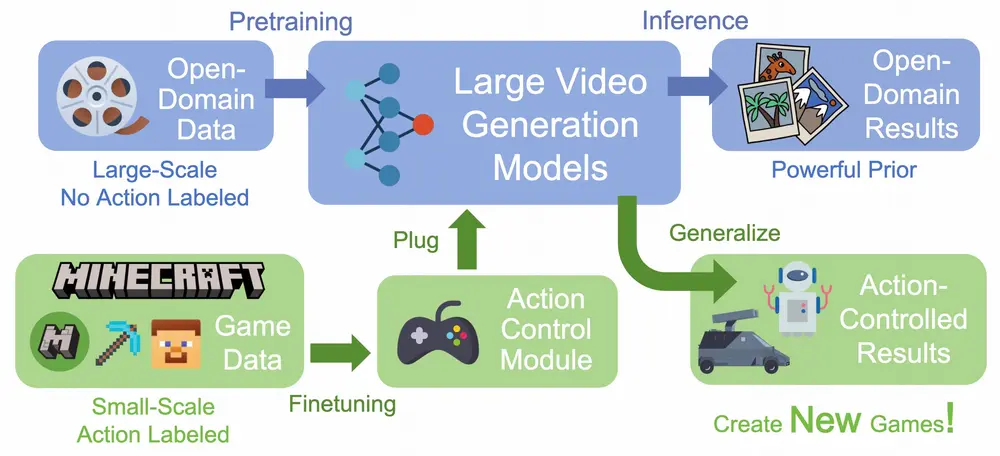
GameFactory框架:通过生成式交互视频来创建全新的游戏香港大学和快手科技的研究人员推出GameFactory框架,旨在通过生成式交互视频来创建全新的游戏。该框架利用预训练的视频扩散模型(video diffusion models),结合少量的第一人称游...新技术# GameFactory# 快手1年前03120
CSpD:用于加速自回归图像生成模型的推理过程中国科学院大学、中国科学院自动化研究所和中国铁塔的研究人员介绍了一种名为“Continuous Speculative Decoding”(CSpD)的技术,用于加速自回归(Autoregressiv...新技术# CSpD# 推理加速1年前03120
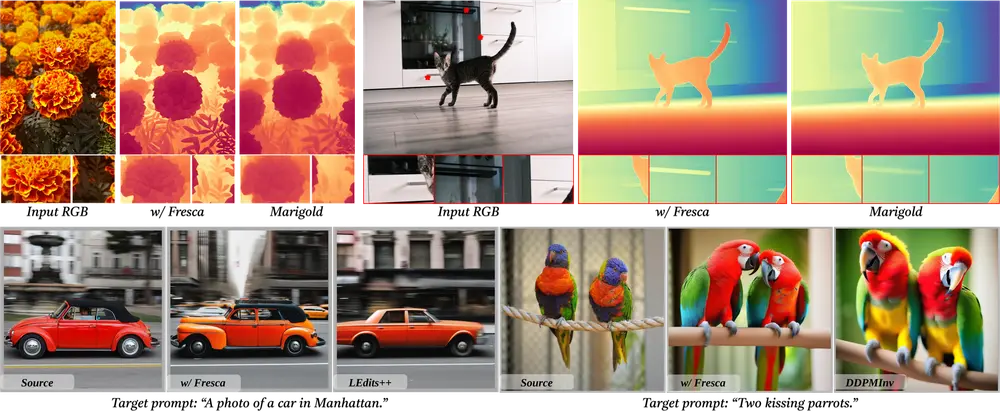
FreSca:用于增强扩散模型在图像编辑和图像理解任务中的性能罗切斯特大学、Netflix Eyeline Studios和德克萨斯大学达拉斯分校的研究人员推出 FreSca,用于增强扩散模型(Diffusion Models)在图像编辑和图像理解任务中的性能...新技术# FreSca# 图像理解# 图像编辑12个月前03110