
近年来,大语言模型(LLMs)在图像理解和生成方面取得了显著进展,尤其是在将图像编码为离散标记并结合LLMs进行多模态任务时。然而,将这一成功扩展到视频领域面临着更大的挑战,因为视频不仅包含空间信息,还涉及时间维度,需要捕捉复杂的时空动态。为了应对这一挑战,腾讯的研究人员提出了 Divot,一种基于扩散过程的视频标记器,旨在统一视频的理解和生成。
Divot利用扩散模型(Diffusion Models)进行自监督学习,以实现视频内容的理解(Comprehension)和生成(Generation)。Divot的核心目标是创建一个能够捕捉视频的空间特征和时间动态的表示,这些表示可以作为大语言模型(LLMs)的输入,进而解码成真实的视频片段。例如,给定一个简短的文本提示如“一个人在公园跑步”,Divot能够理解这个提示,并生成一个与之匹配的视频,展示一个人在公园跑步的场景。这个过程涉及到从文本到视频的转换,包括理解文本内容并生成相应的视频内容。

核心问题与解决方案
1. 视频的时空特性捕捉
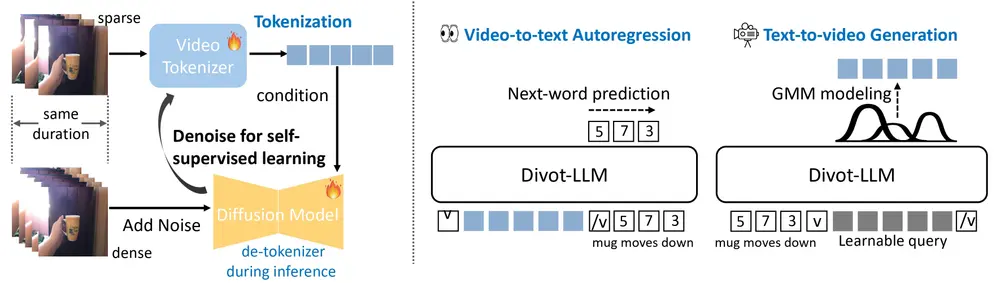
视频数据具有时空双重特性,即每一帧包含空间信息,而帧与帧之间的顺序则构成了时间信息。传统的视频表示学习方法往往难以同时捕捉这两种特性,导致生成的视频缺乏连贯性或真实性。Divot 的核心创新在于利用 扩散过程 进行自监督的视频表示学习,从而有效地捕捉视频的时空信息。
- 扩散过程:扩散模型通过逐步向数据中添加噪声,并学习如何从噪声中恢复原始数据。在视频场景中,扩散模型可以学习如何从噪声中重建视频片段,这要求模型必须理解视频的时空结构。通过这种方式,Divot 能够生成稳健的视频表示,这些表示不仅包含了每帧的空间特征,还捕捉了帧与帧之间的时序关系。
2. 视频标记器的设计
Divot 作为一种视频标记器,其目标是将视频片段转换为离散的标记序列,类似于文本中的词汇。这些标记可以被 LLMs 处理,从而实现视频的理解和生成。具体来说,Divot 的设计包括以下几个关键点:
- 自监督学习:Divot 通过扩散过程进行自监督学习,无需依赖大量的标注数据。它学会了如何将视频片段编码为离散的标记,并能够根据这些标记重建视频。这种自监督的方式使得 Divot 可以在大规模未标注的视频数据上进行训练,提高了模型的泛化能力。
- 时空一致性:Divot 的扩散过程不仅考虑了单帧的空间信息,还考虑了帧与帧之间的时序关系。通过这种方式,Divot 生成的标记能够保持视频的时空一致性,确保生成的视频片段在时间和空间上都是连贯的。
- 解码与生成:Divot 不仅是一个编码器,还可以作为解码器使用。通过条件扩散模型,Divot 可以根据给定的标记序列生成真实的视频片段。这种双向的能力使得 Divot 在视频理解和生成任务中都能发挥作用。
3. Divot-Vicuna:视频生成与理解的集成
基于 Divot 标记器,研究人员进一步提出了 Divot-Vicuna,这是一种结合了 LLMs 和视频生成的框架。Divot-Vicuna 通过以下方式实现了视频到文本和文本到视频的双向转换:
- 视频到文本:Divot-Vicuna 可以将视频片段编码为离散标记,并通过预训练的 LLMs 将这些标记解码为自然语言描述。这使得模型能够在观看视频后生成详细的叙事或总结,适用于视频字幕生成、视频摘要等任务。
- 文本到视频:Divot-Vicuna 还支持从文本描述生成视频。通过高斯混合模型(GMM)对连续值的 Divot 特征分布进行建模,Divot-Vicuna 可以根据给定的文本提示生成相应的视频片段。这种能力使得模型能够在给定一段文字描述的情况下,生成符合描述的视频内容,适用于视频创作、故事讲述等应用场景。
- 指令调整:为了提高 Divot-Vicuna 在特定任务上的表现,研究人员还对其进行了指令调整(instruction tuning)。经过调整后的 Divot-Vicuna 在视频讲故事任务中表现出色,能够生成交织的叙事和相应的视频片段,展示了其在创意内容生成方面的潜力。
实验结果与性能评估
研究人员在多个视频理解和生成基准上对 Divot 和 Divot-Vicuna 进行了评估,实验结果表明:
- 视频理解:Divot 在视频分类、动作识别等任务上表现出色,证明了其捕捉视频时空特性的能力。
- 视频生成:Divot-Vicuna 在文本到视频生成任务中达到了有竞争力的性能,生成的视频片段在质量和连贯性上都优于现有的方法。特别是在视频讲故事任务中,Divot-Vicuna 能够根据给定的文本提示生成符合逻辑的视频叙事,展示了其在创意内容生成方面的强大能力。
总结与未来工作
Divot 作为一种基于扩散过程的视频标记器,成功地捕捉了视频的时空特性,并为 LLMs 提供了有效的视频表示。在此基础上,Divot-Vicuna 通过结合 LLMs 和视频生成技术,实现了视频到文本和文本到视频的双向转换,并在多个基准上取得了优异的性能。未来的工作可以进一步探索如何将 Divot 应用于更多的视频理解和生成任务,例如视频编辑、视频检索等。此外,研究人员还可以尝试将 Divot 与其他多模态模型结合,进一步提升其在复杂任务中的表现。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











