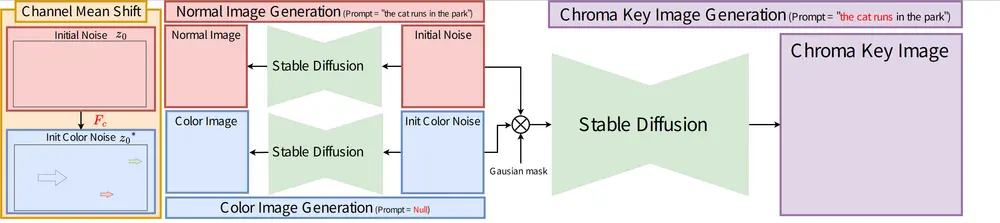
TKG-DM:无需微调,让扩散模型精准生成色键背景图像当前扩散模型已能生成高真实感、高文本忠实度的图像,但主流大规模文本到图像模型(如 Stable Diffusion)面临一大局限——难以生成“前景对象置于色键背景”的图像,若要分离前景与背景元素,往往...新技术# TKG-DM5个月前01280
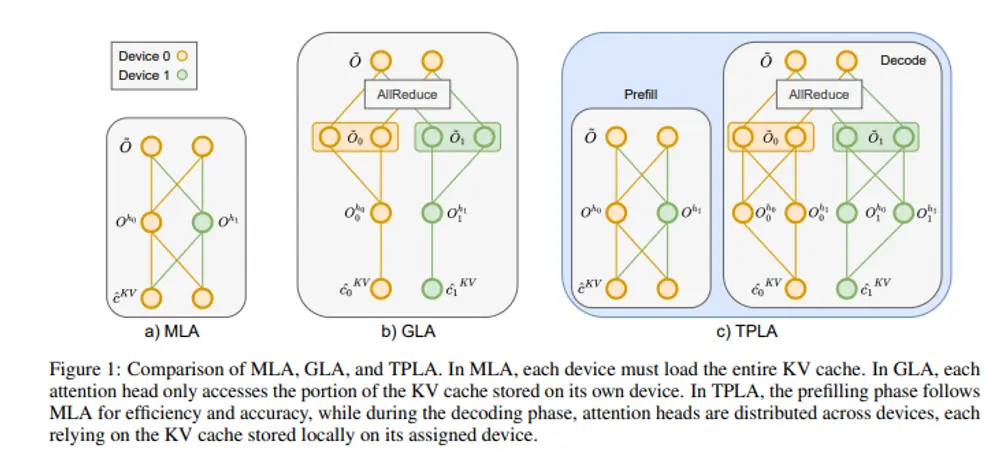
TransMLA 框架 + TPLA 机制:解决 GQA 模型迁移痛点,大幅提升 LLM 推理效率由北京大学人工智能研究院、北京通用人工智能研究院与腾讯优图实验室联合提出的新方法 TransMLA,为大模型推理效率的提升提供了一条实用路径。该方法能够将已广泛部署的 GQA(Grouped Quer...新技术# TPLA 机制# TransMLA5个月前01500
XQUANT:通过低比特量化和KV缓存重物质化来显著降低大语言模型推理过程中的内存消耗加州大学伯克利分校、FuriosaAI、ICSI和劳伦斯伯克利国家实验室的研究人员推出一种名为XQUANT的技术,通过低比特量化和KV缓存重物质化来显著降低大语言模型(LLM)推理过程中的内存消耗。X...新技术# KV缓存# XQUANT5个月前01800
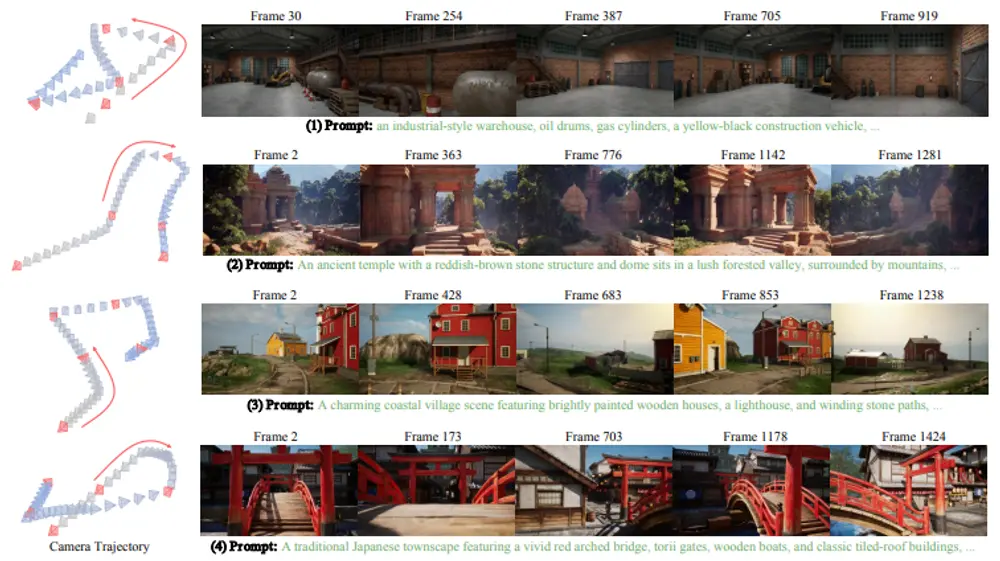
港大、浙大联合快手提出Context-as-Memory:解决交互式长视频生成的场景一致性难题香港大学、浙江大学与快手可灵团队的研究人员,针对当前交互式长视频生成中“场景易断裂、历史上下文难复用”的痛点,提出 Context-as-Memory(上下文即记忆) 方法。该方法通过将历史帧直接作为...新技术# Context-as-Memory# 场景一致性5个月前02410
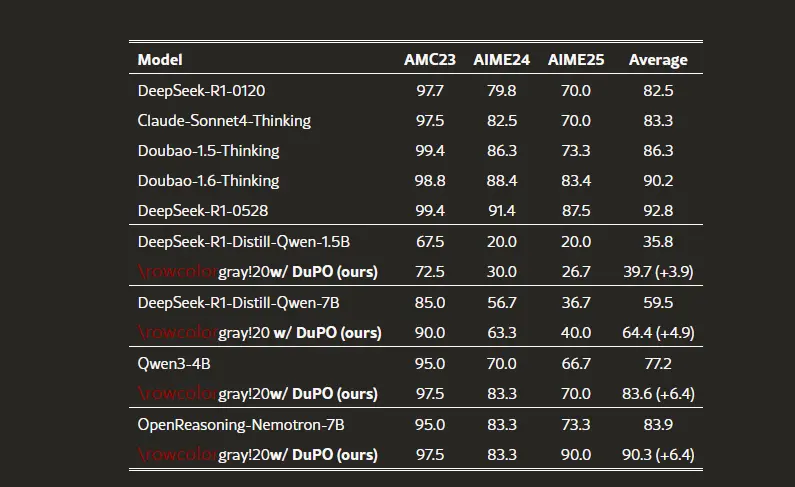
DuPO框架:通过双学习和偏好优化的方法,使大语言模型能够在没有标注数据的情况下进行自我验证和优化字节跳动Seed团队和南京大学的研究人员推出DuPO框架,它通过双学习(dual learning)和偏好优化(preference optimization)的方法,使大语言模型(LLMs)能够在没...新技术# DuPO框架# 大语言模型5个月前01710
北卡教堂山分校新研究:GPT-5、Gemini-2.5-Pro等顶级多模态大语言模型,竟难区分图像90°与270°旋转北卡罗来纳大学教堂山分校的研究团队,针对多模态大语言模型(MLLMs)的空间视觉推理能力展开专项测试——聚焦“图像旋转角度识别”任务(判断图像是否旋转0°、90°、180°、270°)。 GitHub...新技术# RotBench# 多模态大语言模型# 空间视觉推理能力5个月前01460
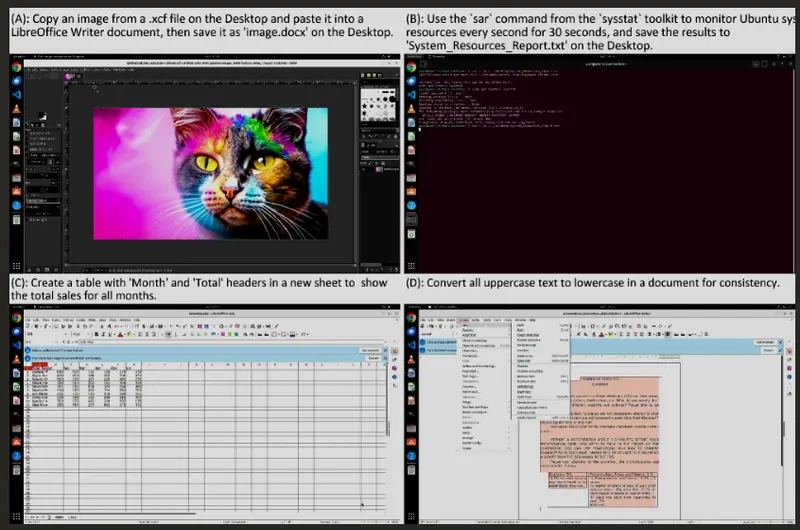
自动化桌面任务设计的框架COMPUTERRL:通过强化学习提升计算机桌面智能代理的操作能力清华大学、智谱AI和中国科学院大学的研究人员推出一个名为 COMPUTERRL 的框架,通过强化学习(Reinforcement Learning, RL)提升计算机桌面智能代理(agents)的操作...新技术# COMPUTERRL5个月前01620
TLB-VFI:让视频帧插值更高效,时序信息与速度兼得视频帧插值(VFI)是计算机视觉领域的关键任务——它能根据两个连续帧(过去帧(I_0)、未来帧(I_1))生成中间帧(I_n),让视频播放更流畅、压缩更高效。但现有方法始终面临“两难”:基于图像的扩散...新技术# TLB-VFI# 视频帧插5个月前01990
如何让图像生成模型“遗忘”一个概念?东北大学与MIT提出扩散模型概念擦除新方法随着图像生成模型(如Stable Diffusion、Flux等)在质量和可控性上的飞速进步,其潜在风险也日益凸显: 生成裸露或暴力内容 模仿特定艺术家风格引发版权争议 复现受保护的商标或人物形象 现...新技术# 图像生成模型# 概念擦除6个月前02070
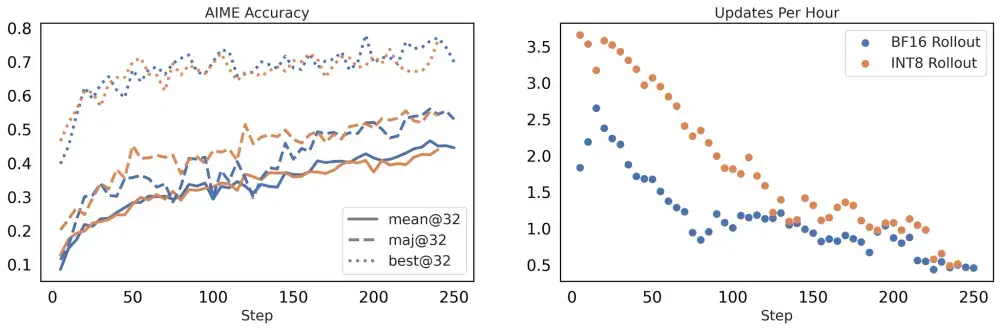
大模型 RL 加速新方案:FlashRL 实现无损量化 rollout在大模型强化学习(RL)训练中,rollout 生成是耗时最长的环节之一。以 DAPO-32B 为例,rollout 阶段占据了约 70% 的总训练时间。这一瓶颈使得整个训练流程效率低下,尤其在大规模...新技术# FlashRL6个月前03500
Echo-4o :通过利用 GPT-4o 生成的合成图像数据来提升多模态生成模型的性能上海人工智能实验室、中山大学、香港中文大学和北京大学的研究人员推出 Echo-4o 系统,通过利用 GPT-4o 生成的合成图像数据来提升多模态生成模型(如文本到图像生成、多参考图像生成等任务)的性能...新技术# Echo-4o# GPT-4o# 多模态生成模型6个月前02520
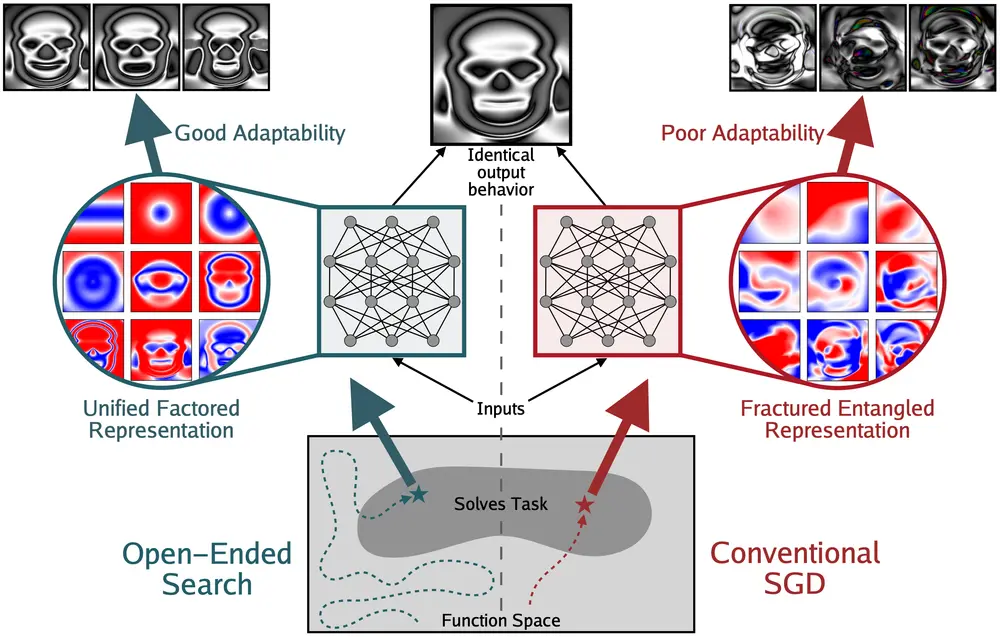
模型变强了,内部表示就更好了吗?MIT等提出“碎片化纠缠表示(FER)”假说当我们看到大模型在各种任务上不断刷新性能纪录时,一个隐含的信念常常浮现:性能提升 = 内部表示更优。这种观点被称为“表示乐观主义”(Representational Optimism)——即认为随着模...新技术# FER# 碎片化纠缠表示6个月前02730