高质量、人工奖励数据集HumanEdit:专为指令引导的图像编辑而设计天工AI、新加坡国立大学、北京大学和南洋理工大学的研究人员推出高质量、人工奖励数据集HumanEdit,专为指令引导的图像编辑而设计。该数据集通过开放式语言指令实现精确和多样化的图像操作,旨在解决现有...新技术# HumanEdit1年前02890
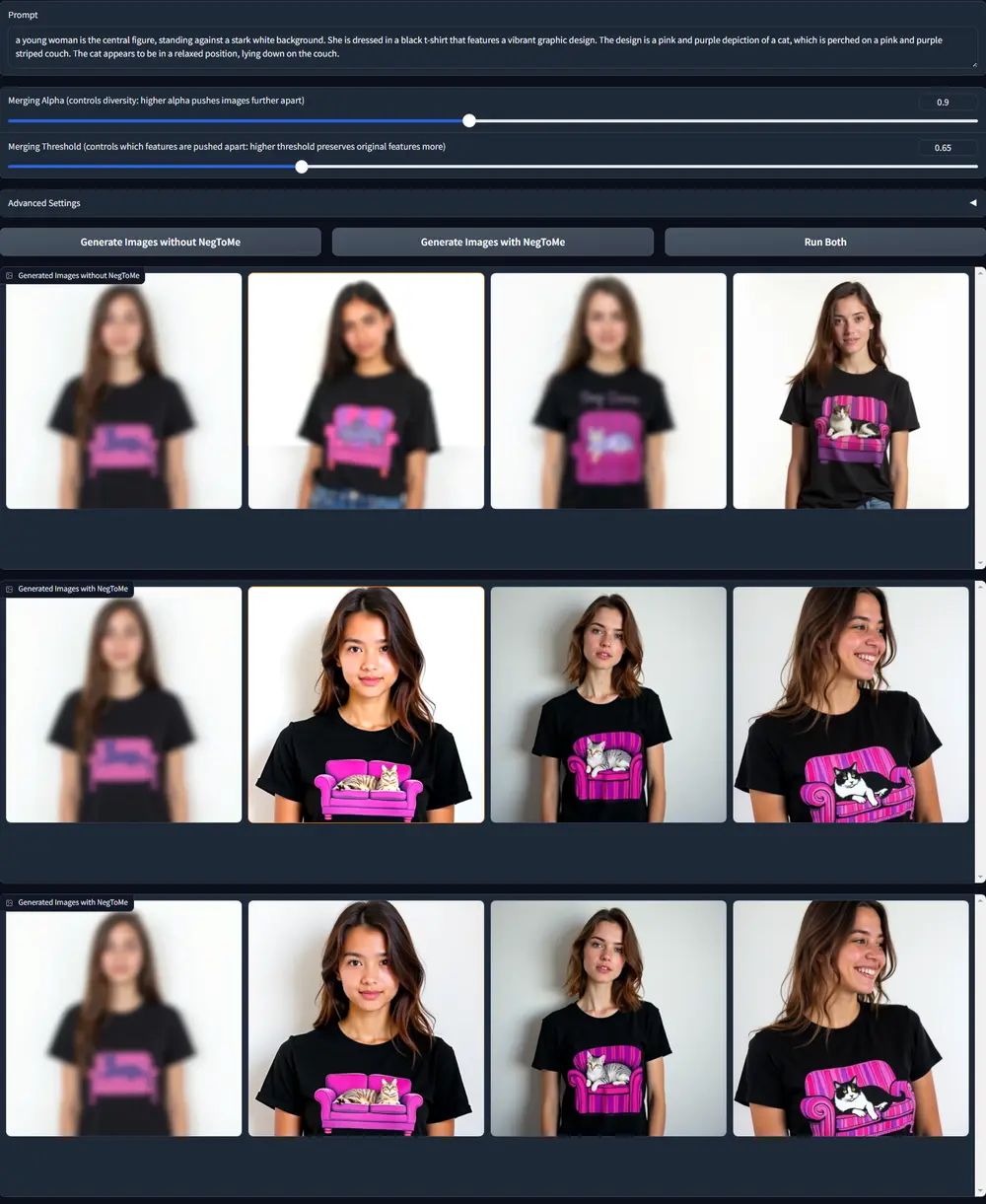
基于视觉特征的对抗性引导方法NegToMe:利用参考图像或其他批次图像的视觉特征,而非仅依赖文本提示,来更有效地排除不希望的视觉元素华盛顿大学、澳大利亚国立大学和艾伦人工智能研究所的研究人员提出了一种新的对抗性引导方法——负标记合并(Negative Token Merging, NegToMe)。该方法旨在通过直接利用参考图像或...新技术# NegToMe# 负标记合并1年前02790
实时交互式3D场景生成的创新框架WonderWorld:能够以低延迟的方式指定场景内容和布局,并实时查看创建的场景MIT和斯坦福的研究人员联合推出了WonderWorld,这是一个用于交互式3D场景生成的创新框架。它使用户能够以低延迟的方式指定场景内容和布局,并实时查看创建的场景。WonderWorld的主要目标...新技术# 3D场景# WonderWorld1年前02510
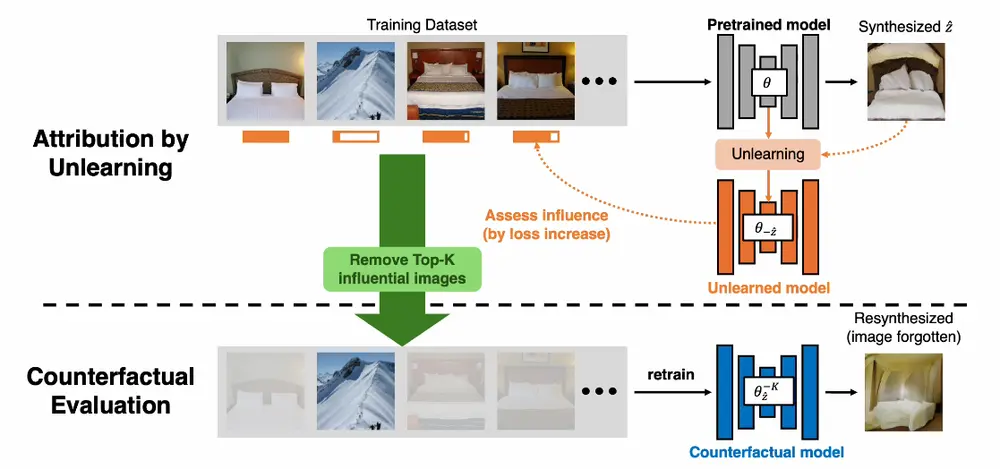
文本到图像模型的数据归因:识别在生成新图像过程中最具影响力的训练图像卡内基梅隆大学、Adobe 研究和加州大学伯克利分校的研究人员发布论文,论文的主题是关于文本到图像模型的数据归因(Data Attribution for Text-to-Image Models...新技术# 文生图模型1年前02810
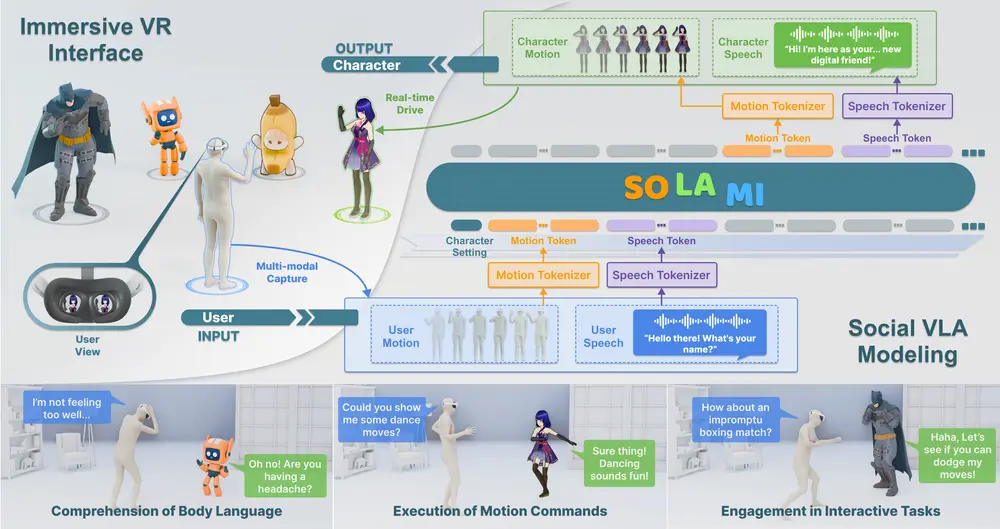
SOLAMI:为3D自主角色提供社交智能,使其能够感知、理解和与人类进行交互。人类是社会性动物,赋予3D自主角色类似的社会智能,使其能够感知、理解和与人类互动,是一个开放且基础的问题。商汤科技研究院和南洋理工大学的研究人员提出了SOLAMI,这是第一个端到端的社交视觉-语言-动...新技术# SOLAMI1年前02670
SPOTLIGHT:通过扩散模型实现对虚拟对象插入图像时的光影控制拉瓦尔大学、Depix Technologies和芝加哥丰田技术学院的研究人员推出SPOTLIGHT,它用于通过扩散模型实现对虚拟对象插入图像时的光影控制。这种方法的核心在于,通过指定对象的期望阴影...新技术# SPOTLIGHT1年前02890
无需额外训练的缓存策略TeaCache:加速视频扩散模型的推理过程,同时保持生成视频的视觉质量扩散模型(DMs)作为视频生成的基本骨干,因其顺序去噪的性质而面临低推理速度的挑战。尽管先前的方法通过在均匀选择的时间步长上缓存和重用模型输出来加速模型,但这种策略忽略了模型输出在不同时间步长上的差异...新技术# TeaCache# 缓存策略12个月前04630
新型采样引导方法STG:提升视频扩散模型生成质量扩散模型(DMs)近年来在生成高质量图像、视频和3D内容方面取得了显著进展。然而,现有的采样引导技术如分类器引导(CFG)虽然提高了生成内容的质量,但也带来了多样性和运动性的下降。自动引导方法虽然缓解...新技术# STG1年前02920
RollingDepth:将单图像深度估计转化为高效的视频深度估计随着大型基础模型的发展和合成训练数据的广泛应用,单图像深度估计技术取得了显著进展,这重新激发了研究者对视频深度估计的兴趣。然而,直接将单图像深度估计器应用于视频每一帧的方法存在明显缺陷,如时间连续性忽...新技术# RollingDepth# 视频深度1年前02880
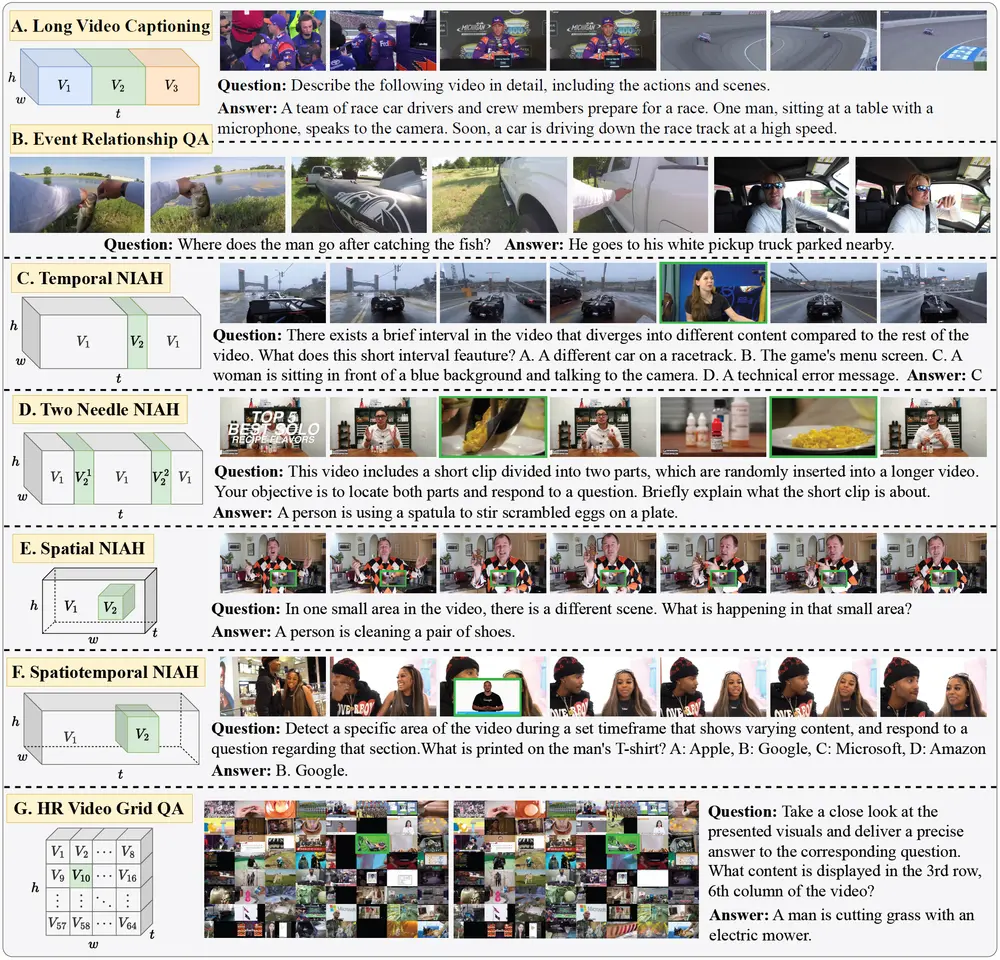
VISTA框架:通过视频时空增强技术,提升对长时和高分辨率视频的理解能力滑铁卢大学、矢量研究所和零一万物的研究人员推出VISTA框架,旨在通过视频时空增强技术,提升对长时和高分辨率视频的理解能力。VISTA通过从现有的视频-字幕数据集中合成长时和高分辨率视频指令对,以增强...新技术# VISTA1年前02720
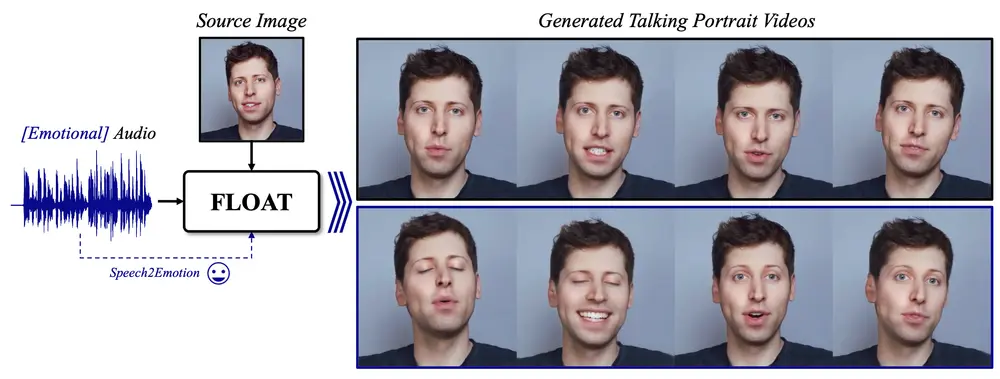
新型音频驱动的肖像视频生成方法FLOAT:基于流匹配生成模型,能够在给定单一源图像和音频的情况下生成具有自然说话动作的肖像视频DeepBrain和韩国科学技术院人工智能研究生院的研究人员推出新型音频驱动的肖像视频生成方法FLOAT,它基于流匹配生成模型,能够在给定单一源图像和音频的情况下生成具有自然说话动作的肖像视频。FLO...新技术# FLOAT# 肖像视频1年前02470
FlowChef:利用矢量场动力学的统一受控图像生成框架扩散模型(DMs)在照片真实感图像生成、图像编辑和逆问题解决方面取得了显著进展,这主要归功于无分类器引导和图像反演技术。然而,校正流模型(RFMs)在这类任务中的潜力尚未得到充分开发。现有的基于DM的...新技术# FlowChef# 图像生成框架1年前03020