StreamChat:增强大型多模态模型(LMMs)与流媒体视频内容的交互能力香港中文大学、英伟达、上海人工智能实验室、InnoHK和香港理工大学的研究人员推出新型方法StreamChat,它旨在增强大型多模态模型(LMMs)与流媒体视频内容的交互能力。在流媒体交互场景中,现有...新技术# StreamChat# 多模态模型1年前03080
视频风格化方法StyleMaster:能够对视频进行艺术化生成和风格转换香港科技大学和快手的研究人员推出视频风格化方法StyleMaster,它能够对视频进行艺术化生成和风格转换。StyleMaster通过结合全局和局部的风格表示,实现了对视频内容的风格化处理,同时保持了...新技术# StyleMaster# 视频风格化1年前02880
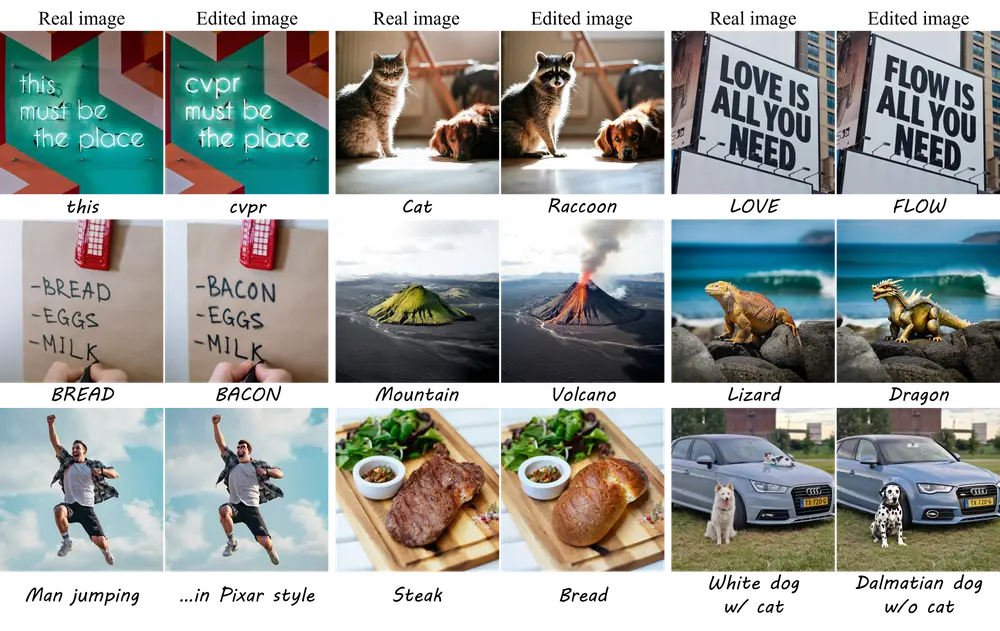
基于预训练流模型的新型文本驱动图像编辑方法FlowEdit:适用于SD3和Flux模型使用预训练的文本到图像(T2I)扩散或流模型编辑真实图像是一项具有挑战性的任务。传统的方法通常涉及将目标图像反转为对应的噪声图,然后根据新的文本提示重新生成图像。然而,仅靠反转变换往往无法获得满意的结...新技术# FlowEdit# 图像编辑1年前03360
强调了结构化注释的使用!用于训练复杂图像-文本模型的大规模数据集LAION-SG浙江大学、江南大学、北京大学、阿里巴巴集团和蚂蚁集团的研究人员推出一个用于训练复杂图像-文本模型的大规模数据集LAION-SG,特别强调了结构化注释的使用。LAION-SG通过提供场景图(Scene ...新技术# LAION-SG# 数据集1年前03050
多视角视频生成新技术SynCamMaster:能够从不同的视点生成同步的、一致性高的动态场景视频浙江大学、快手科技、清华大学和香港中文大学的研究人员推出一种用于多视角视频生成的技术SynCamMaster,能够从不同的视点生成同步的、一致性高的动态场景视频。这项技术特别适用于虚拟拍摄等应用,它通...新技术# SynCamMaster# 多视角视频1年前03670
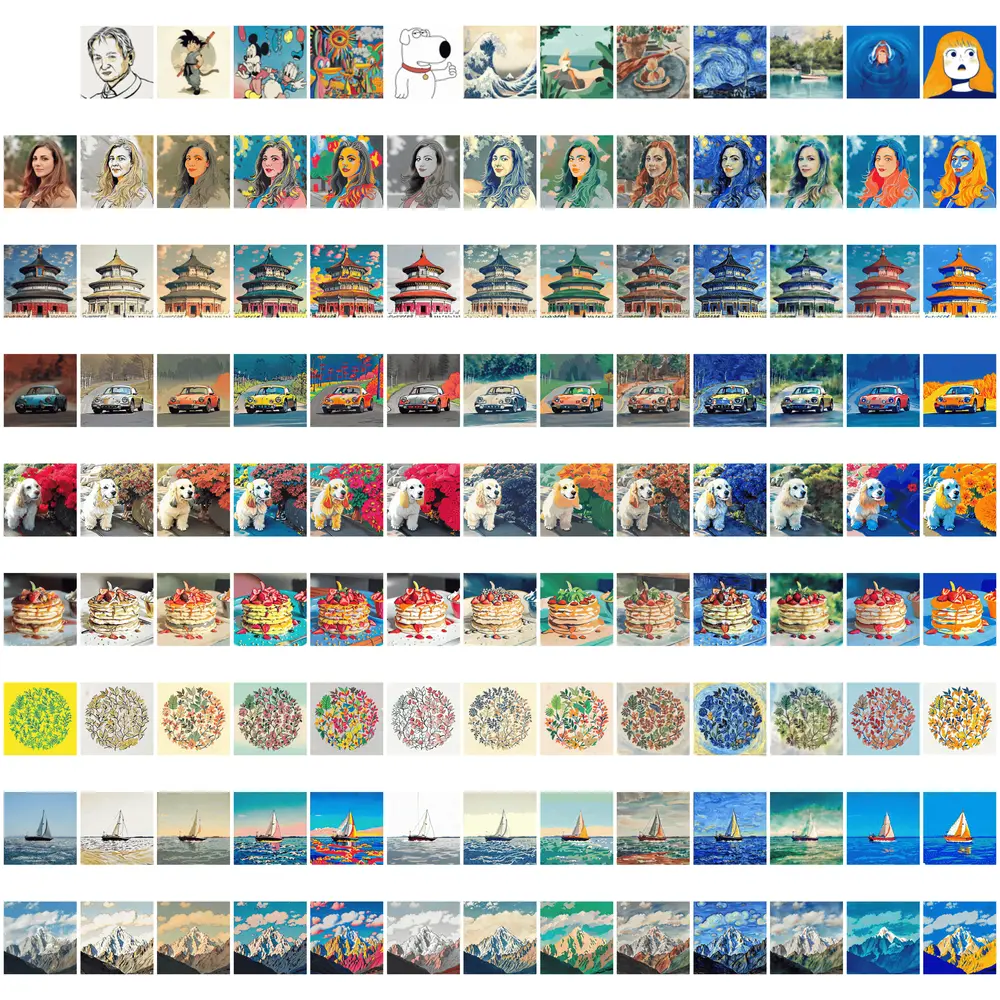
用于组合式文生图新框架GraPE:将复杂的多步生成任务分解为三个独立的步骤文本到图像(T2I)生成任务的目标是从文本提示生成逼真的图像。尽管扩散模型在这一领域取得了显著进展,但现有方法在处理复杂的多步推理和组合性提示时仍面临挑战。特别是,当文本提示包含多个对象及其属性之间的...新技术# GraPE# 文生图1年前03320
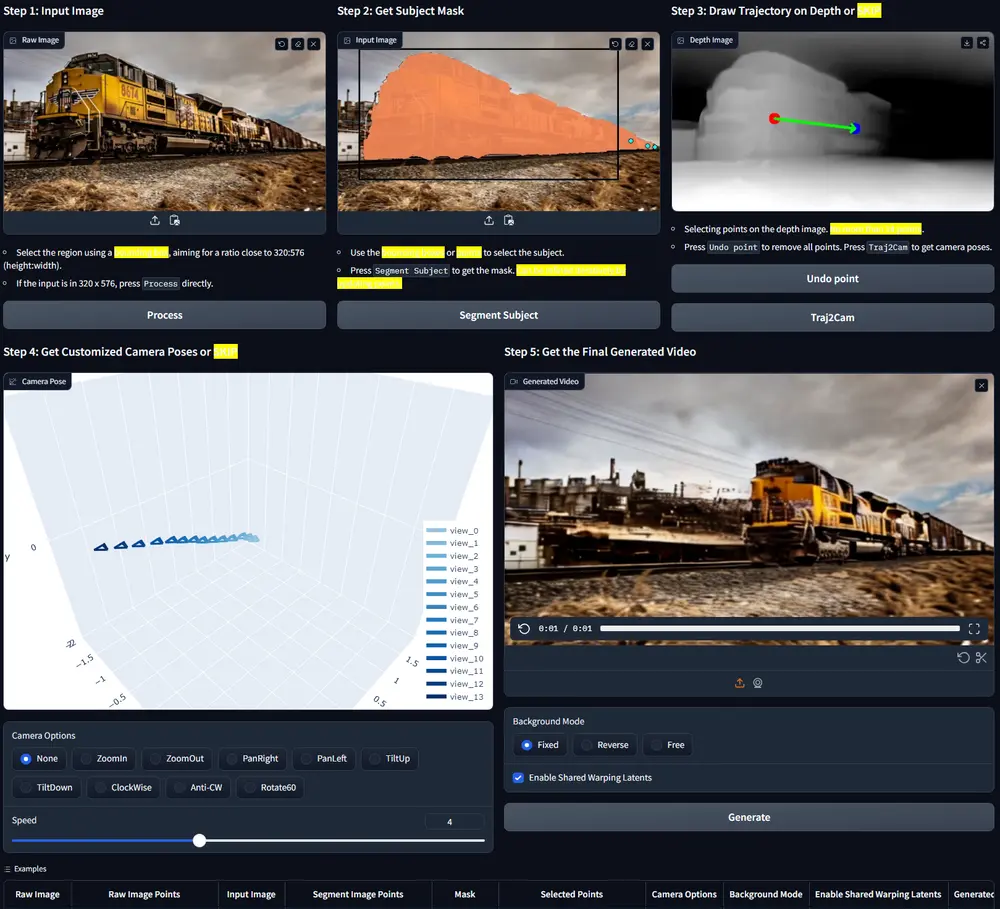
ObjCtrl-2.5D:用于图像到视频(I2V)生成中的训练无关对象控制技术图像到视频(I2V)生成任务的目标是从单张图像生成一段连贯的视频,通常涉及对目标对象进行空间移动或变形。现有的方法大多依赖于2D轨迹来表示对象的运动,这虽然简单但存在局限性: 无法捕捉用户意图:2D轨...新技术# ObjCtrl-2.5D# 图生视频1年前03080
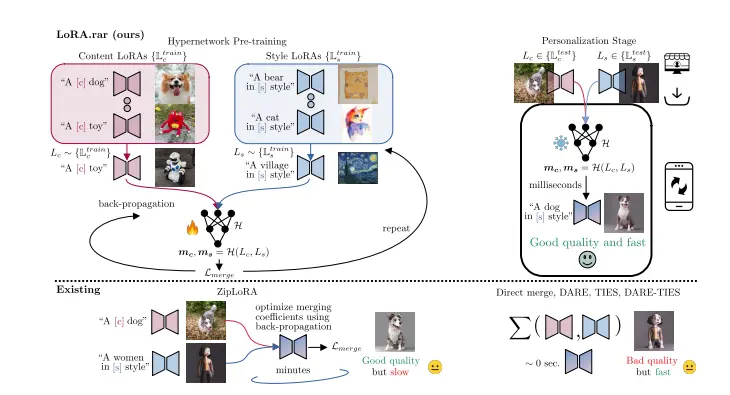
用于主题-风格条件图像生成新技术LoRA.rar:通过使用超网络(hypernetworks)来学习合并内容和风格的LoRAs,从而实现个性化图像的快速生成三星和帕多瓦大学的研究人员推出一种用于主题-风格条件图像生成技术LoRA.rar,通过使用超网络(hypernetworks)来学习合并内容(subject)和风格(style)的低秩适应参数(LoR...新技术# LoRA.rar1年前02600
专为DiT架构模型设计的运动转移方法DiTFlow牛津大学、Snap和MBZUAI的研究人员介绍了一种名为DiTFlow的方法,它是一种专为DiT架构模型设计的运动转移方法。DiTFlow通过分析参考视频,提取出一种名为注意力运动流(Attentio...新技术# DiTFlow# DiT模型1年前03850
高通AI研究院推出专为移动设备优化的视频编辑模型MoViE:能够在手机上实现每秒12帧的快速视频编辑高通AI研究院推出一个专为移动设备优化的视频编辑模型MoViE,能够在手机上实现每秒12帧的快速视频编辑。MoViE通过一系列优化,使得在移动设备上进行视频编辑变得可行,这些优化包括架构优化、轻量级自...新技术# MoViE# 视频编辑模型# 高通1年前03130
高通AI研究院推出一个为移动设备优化的视频生成模型MobileVD高通AI研究院推出了一个为移动设备优化的视频生成模型Mobile Video Diffusion(MobileVD),该模型的目标是在保持生成视频的质量和控制力的同时,显著降低计算需求,使得在移动设备...新技术# MobileVD# 视频生成模型1年前04500
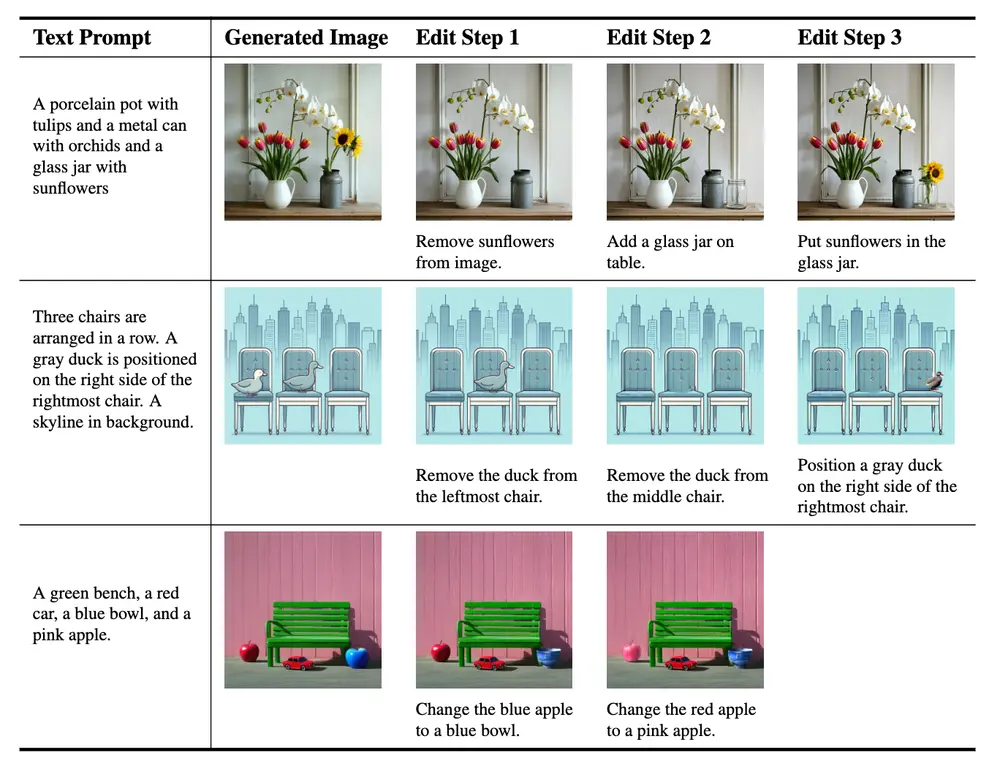
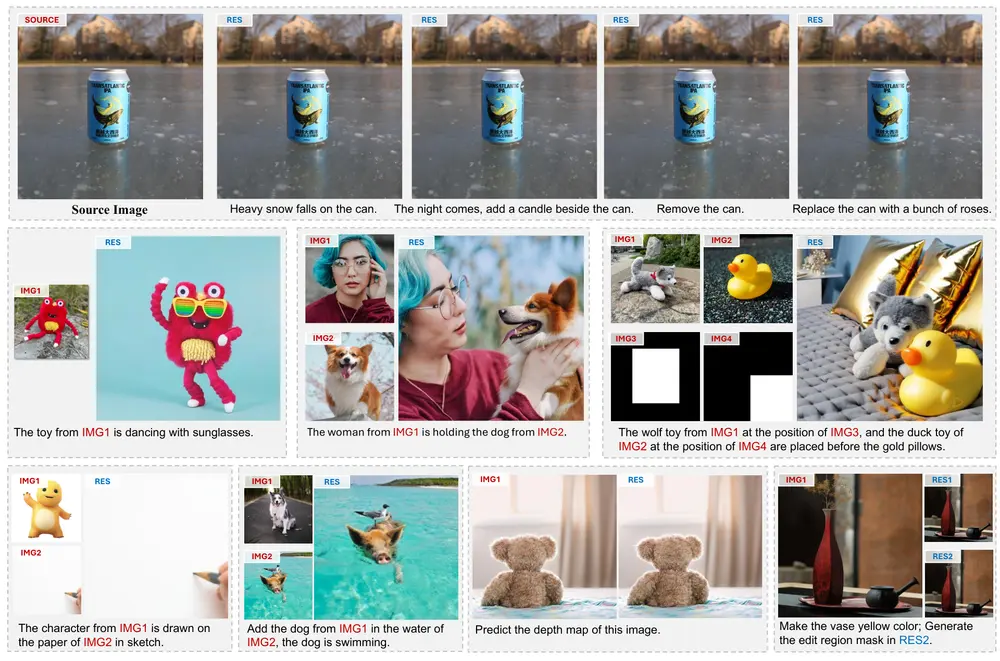
解决图像生成与编辑任务的统一框架UniReal图像生成和编辑任务在计算机视觉领域中具有广泛的应用,如图像合成、风格迁移、图像修复等。然而,现有的解决方案通常针对特定任务设计,缺乏一个统一的框架来处理多种图像级任务。香港大学和Adobe Resea...新技术# UniReal# 图像生成# 图像编辑1年前02980