新型图像编辑方法FluxSpace:基于修正流变换器(如Flux)来实现文本引导的图像编辑校正流模型(如 Flux)在图像生成中已成为主导方法,展示了高质量图像合成的卓越能力。然而,尽管它们在视觉生成中表现出色,校正流模型在图像的解耦编辑方面往往表现不佳。这一限制阻碍了在不影响图像无关部分...新技术# FLUX# FluxSpace# 图像编辑1年前03250
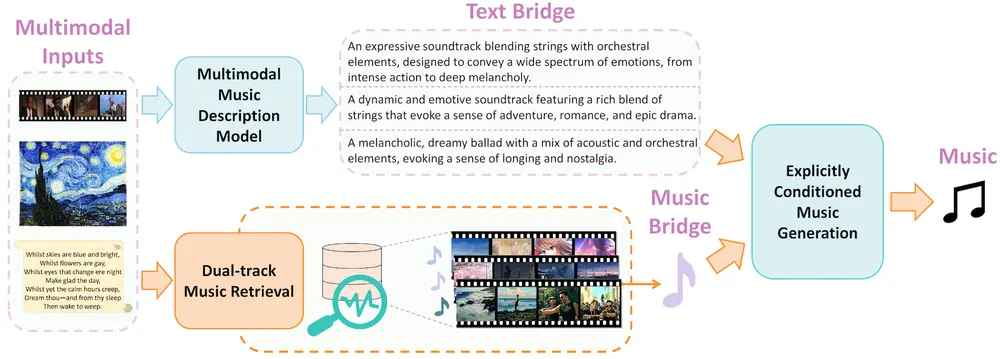
多模态音乐生成系统VMB:够从多种输入模态(如文本、图像和视频)中生成音乐多模态音乐生成旨在从多种输入模态(如文本、视频和图像)中生成音乐。尽管现有方法通过使用通用嵌入空间进行多模态融合,在其他任务中表现出色,但在多模态音乐生成中仍面临以下挑战: 数据稀缺:高质量的多模态音...新技术# VMB# 音乐生成1年前03030
ObjectMate:能够在无需微调的情况下,实现对象插入和主题驱动的图像生成对象插入和主体驱动生成是计算机视觉中的两个重要任务,旨在将给定的对象合成到由图像或文本指定的场景中。具体来说: 对象插入:将一个对象无缝地插入到目标场景中,要求合成后的图像在姿态、光照等方面看起来逼真...新技术# ObjectMate# 图像编辑1年前04040
无需微调的推理范式FreeScale:通过 尺度融合 实现更高分辨率的图片生成视觉扩散模型(Diffusion Models)在图像和视频生成领域取得了显著进展,但由于缺乏高分辨率数据和计算资源的限制,它们通常只能在有限的分辨率下进行训练。这阻碍了其生成高保真图像或视频的能力...新技术# FreeScale1年前02630
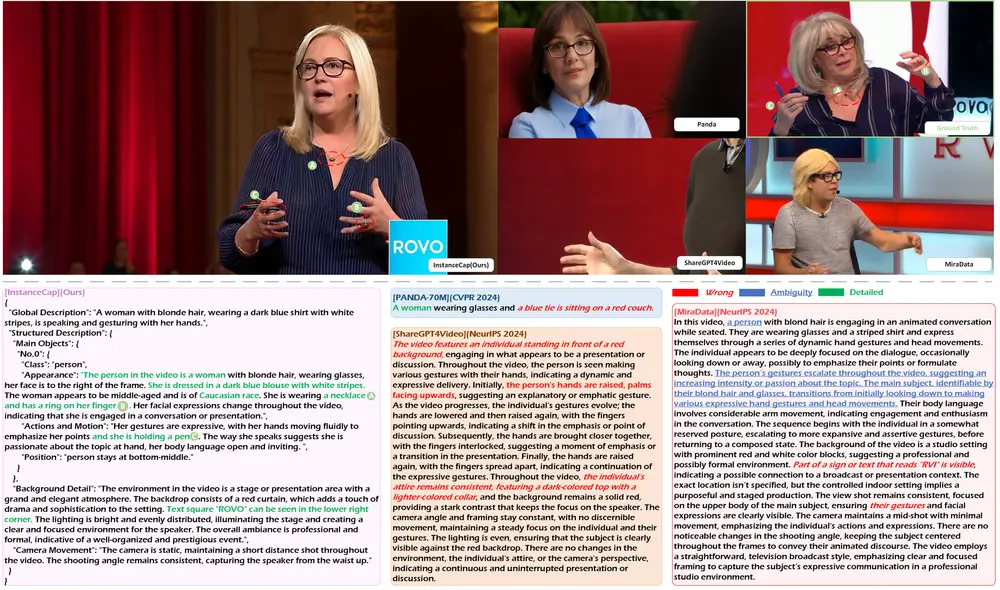
实例感知结构化字幕框架InstanceCap:实现实例级 和 细粒度 的视频字幕生成,显著提升了字幕与视频之间的一致性和保真度近年来,文本到视频生成技术取得了显著进展,但现有的视频字幕生成方法仍然存在一些问题: 细节不足:传统的视频字幕往往缺乏对视频中物体和场景的细粒度描述,导致生成的视频在细节上不够丰富。 幻觉现象:由于模...新技术# InstanceCap# 字幕1年前02980
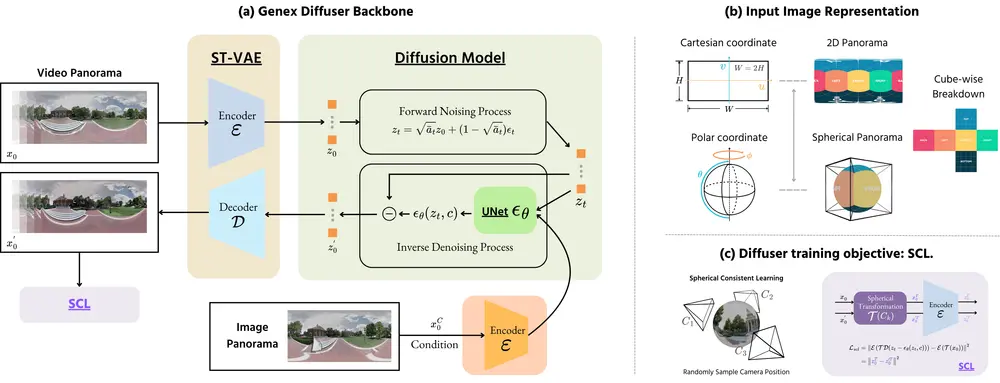
GenEx:从单张RGB图像生成一个可探索的3D一致性虚拟环境理解、导航和探索三维物理现实世界一直是人工智能(AI)领域的一个核心挑战。传统的方法通常依赖于传感器数据(如摄像头、激光雷达等)来构建环境的即时感知,但这限制了代理在未见区域的预测能力和决策效率。为了...新技术# GenEx1年前02810
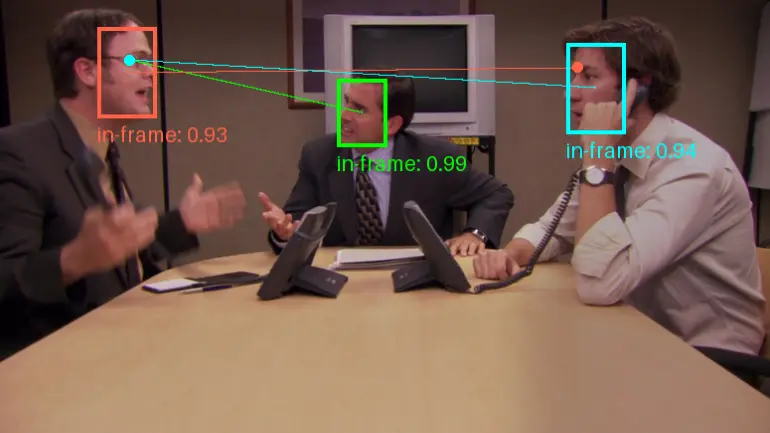
新型Transformer框架Gaze-LLE:用于估计人在场景中注视的目标位置佐治亚理工学院和伊利诺伊大学厄巴纳-香槟分校的研究人员推出新型Transformer框架,它用于估计人在场景中注视的目标位置。这项技术的核心在于预测一个人在观看什么,这需要对个体的外观和场景内容进行推...新技术# Gaze-LLE11个月前02700
Long Volumetric Video:高效地表示和渲染长时间的体积视频浙江大学、斯坦福大学和香港科技大学的研究人员发布论文,主题是关于如何高效地表示和渲染长时间的体积视频(Long Volumetric Video)。体积视频是一种能够从多个视角捕捉动态场景并提供自由视...新技术# EasyVolcap# longvolcap# 体积视频1年前03690
Meta开源的人体动作生成模型Meta Motivo:生成符合物理规律的复杂的全身动作Meta Motivo 是一个创新的行为基础模型,旨在通过一种新的无监督强化学习(RL)算法——前向-后向表示与条件策略正则化(FB-CPR),来控制复杂虚拟人形代理的运动。该模型能够在测试时通过提示...新技术# Meta Motivo1年前03280
FireFlow:用于快速反转和编辑图像语义内容,提高图像生成和编辑的效率和准确性尽管带有蒸馏的校正流(ReFlows)为快速采样提供了一种有前景的方法,但其快速反演过程——即将图像转换回结构化噪声以进行恢复和后续编辑——仍然面临挑战。具体来说,传统的ReFlow方法在反演过程中可...新技术# FireFlow# 图像生成1年前03460
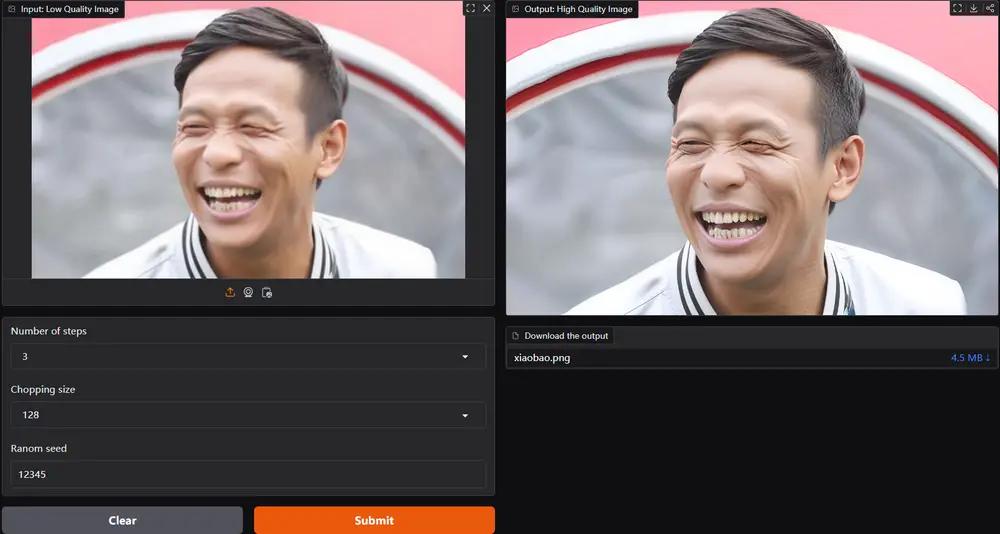
图像超分辨率技术InvSR:基于扩散反转(Diffusion Inversion)来提高图像的分辨率南洋理工大学(NTU)S-Lab提出了一种新的图像超分辨率(Super-Resolution, SR)技术——InvSR,旨在利用大型预训练扩散模型中封装的丰富图像先验来提高SR性能。传统的超分辨率方...新技术# InvSR# 图像超分辨率1年前03640
多概念图像生成方法LoRACLR:在单一模型中合并多个特定概念(如人物、物体或艺术风格)并生成多概念图像近年来,文本到图像定制技术的进步使得个性化图像的高保真、内容丰富的生成成为可能,允许特定概念在各种场景中出现。然而,当前的方法在结合多个个性化模型时面临挑战,常常导致属性纠缠(即不同概念之间的混淆)或...新技术# LoRACLR# 多概念图像1年前02630