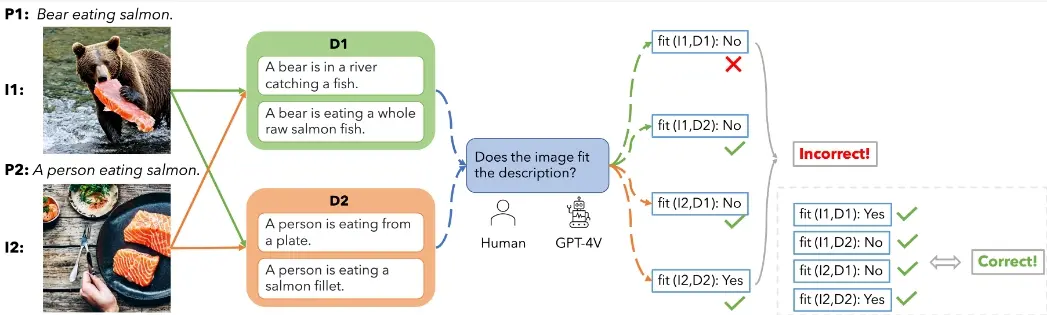
基于提示、针对文生图模型的新型剪枝方法APTP:减少文生图模型在计算资源受限的环境中部署时的计算负担,同时保持模型性能马里兰大学和佛罗里达州立大学推出一种针对文生图模型的新型剪枝方法APTP(Adaptive Prompt-Tailored Pruning,自适应提示定制剪枝),这是一种专门为文生图模型设计的、基于提...新技术# APTP# 剪枝方法# 文生图模型2年前06290
字节跳动推出文生图模型SDXL-Lightning:基于SDXL1.0基础模型提炼SDXL-Lightning是由字节跳动发布的一款速度极快的文生图模型,它采用新型扩散模型蒸馏方法,优化扩散模型,能在短时间内高效生成分辨率为1024像素的高品质图像。 模型地址:https://hu...新技术# SDXL-Lightning# SDXL1.0# 字节跳动2年前06230
人类偏好优化技术NCPPO:改善文生图模型,使其生成的图像更加符合人类的偏好俄罗斯国家研究型高等经济大学的研究人员推出新方法NCPPO,它用于改善文本到图像的扩散模型(Diffusion Models),使其生成的图像更加符合人类的偏好。扩散模型是一种生成模型,它们通过逐步去...新技术# NCPPO# 人类偏好# 文生图模型2年前06040
Bounded Attention:解决文生图模型在生成包含多个主题(subjects)的图像时遇到的挑战来自特拉维夫大学和Snap的研究人员推出Bounded Attention,它旨在解决文生图模型在生成包含多个主题(subjects)的图像时遇到的挑战。这些模型通常难以准确地捕捉到复杂输入提示中的意...新技术# Bounded Attention# 多主题# 文生图模型2年前05820
新型文生图模型YaART:利用人类反馈的强化学习与人类偏好进行对齐来自俄罗斯Yandex、斯科尔科沃科学技术学院、莫斯科国立大学和高等经济学院的研究团队推出新型的、适用于生产环境的文本到图像级联扩散模型YaART(Yet Another Art Rendering ...图像模型# YaART# 文生图模型1年前05810
基准测试CommonsensenT2I:用于评估文生图模型(T2I)生成符合现实生活常识的图像的能力宾夕法尼亚大学和加州大学圣塔芭芭拉分校的研究人员推出基准测试CommonsensenT2I,用于评估文生图模型(T2I)生成符合现实生活常识的图像的能力。简单来说,就是研究这些模型是否能够根据文字描述...新技术# CommonsensenT2I# 基准测试# 文生图模型2年前05720
SliderSpace:自动分解文生图模型的视觉能力,将其转化为简单的滑块控件,使用户能够更直观地控制生成结果扩散模型(Diffusion Models)在生成高质量图像方面表现出色,但其生成过程的黑箱性质限制了用户的控制能力。为了增强扩散模型的可控性和可解释性,来自美国东北大学和 Adobe Researc...图像模型# Adobe Research# SliderSpace# 东北大学1年前05700
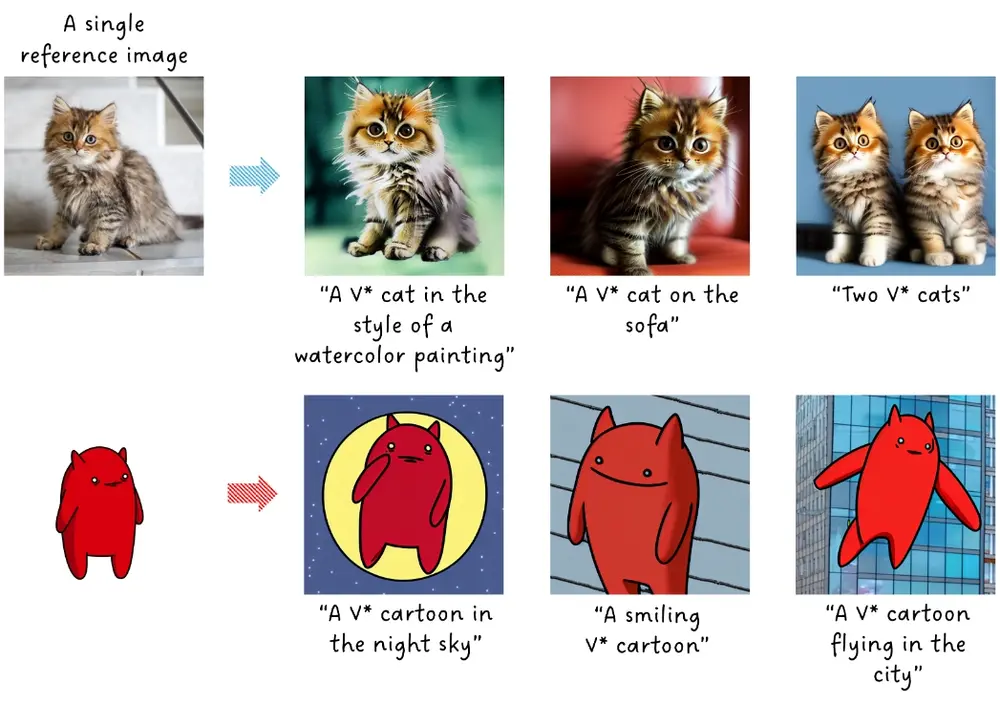
针对文生图模型的一次性个性化定制技术TextBoost:使用单个参考图像,通过微调文本编码器,来生成与文本提示相匹配的定制化图像韩国科学技术院推出一种针对文本到图像模型的一次性个性化定制技术TextBoost,这种方法使用单个参考图像,通过微调文本编码器,来生成与文本提示相匹配的定制化图像。例如,你想要通过一段描述来生成一张图...新技术# TextBoost# 个性化定制# 文生图模型2年前05650
新型文生图模型CountGen:根据文本提示准确地生成指定数量的对象巴伊兰大学、英伟达和特拉维夫大学的研究人员推出新型文生图模型CountGen,它能够根据文本提示准确地生成指定数量的对象。在以往的技术中,尽管文本到图像的扩散模型取得了巨大成功,但它们在控制生成图像中...新技术# CountGen# 文生图模型2年前05250
苹果推出基于最优传输理论的通用框架ACT:用于控制大型生成模型的生成过程大型生成模型(如大语言模型LLMs和文本到图像扩散模型T2Is)的能力不断增强,但其日益广泛的部署也引发了对可靠性和安全性的担忧。为了解决这些问题,研究人员提出了通过引导模型激活来控制模型生成的方法...新技术# ACT# 大语言模型# 文生图模型1年前05070
EvolveDirector 框架:通过使用公开可用的资源来训练一个能够与高级文生图模型相媲美的模型近年来,生成模型在生成高质量图像方面取得了显著进展,但大多数模型依赖于专有的高质量数据集,并且有些模型保留了其参数,只提供可访问的应用程序编程接口(APIs)。这限制了这些模型在下游任务中的应用。为了...新技术# EvolveDirector# 文生图模型1年前04890
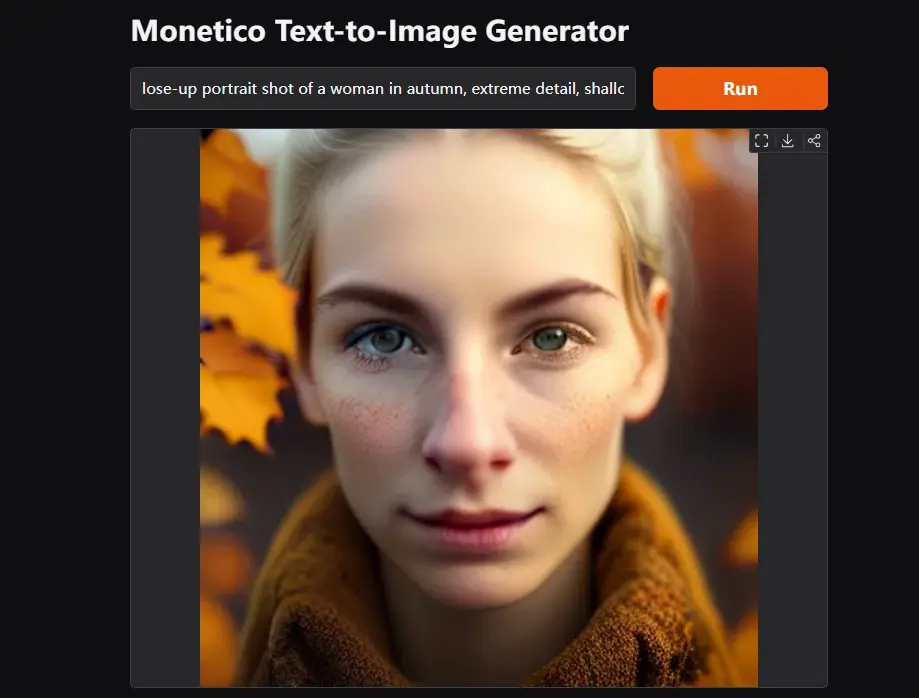
Collov Labs推出非自回归掩码图像建模的文本到图像合成模型MoneticoCollov Labs 最近在8块H100 GPU上训练了一周时间,推出了新的非自回归掩码图像建模的文本到图像合成模型——Monetico。这款模型能够生成高分辨率图像,并且被设计为在消费级显卡上高效...图像模型# Monetico# 文生图模型1年前04840