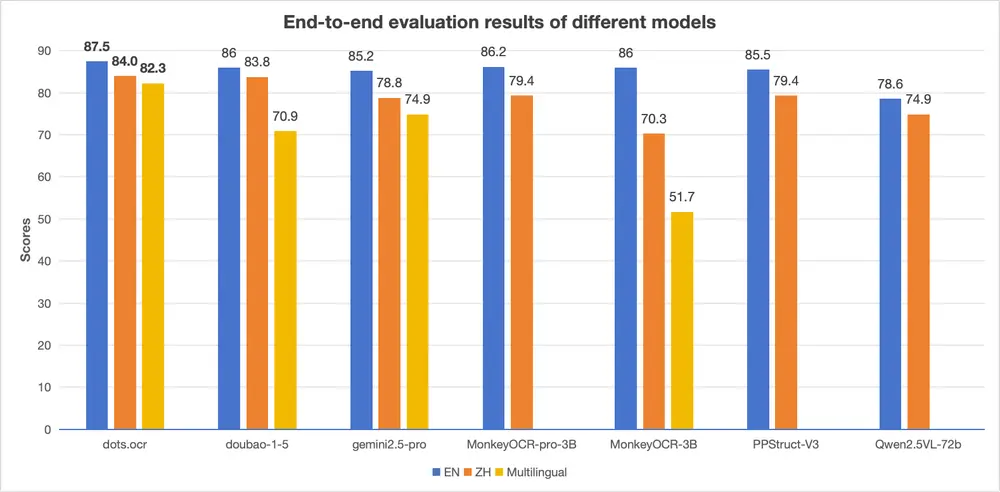
小红书 hi lab 推出 dots.ocr:一个更高效、更统一的文档解析方案小红书 hi lab 团队近期发布了一款名为 dots.ocr 的多语言文档解析模型。它不是传统OCR工具的简单升级,而是一次架构层面的重构——将布局检测与内容识别统一在一个视觉-语言模型(VLM)中...多模态模型# dots.ocr# 小红书8个月前01,1340
小红书推出图像生成模型StoryMaker:不仅能保持面部一致性,还能保持服装、发型和身体的一致性,从而通过一系列图像促进故事的创作小红书推出图像生成模型StoryMaker,它专门设计用于在文本到图像的生成过程中保持人物的一致性。这种一致性不仅限于人物的面部特征,还包括服装、发型和身体特征。通过这种方式,StoryMaker能够...图像模型# StoryMaker# 小红书1年前05290
小红书开源 FireRedChat:一个完整、可控的全双工语音交互系统在智能助手和客户服务场景中,用户希望与AI的对话像人与人交流一样自然——可以随时插话、打断、继续,而系统能即时响应。要实现这种体验,需要真正的全双工语音交互能力。 然而,现有方案存在明显短板: 端到端...语音模型# FireRedChat# 小红书6个月前04300
小红书 Hi Lab 发布 1420 亿参数 MoE 大模型 dots.llm1:推理仅激活 140 亿参数,性能媲美 Qwen2.5-72B小红书 Hi Lab 团队近日正式开源了其自研大规模 MoE 文本大模型 dots.llm1,该模型总参数量高达 1420 亿(142B),但在每次推理时仅激活 140 亿(14B)参数,实现了高效能...大语言模型# dots.llm1# 小红书10个月前03980
小红书 hi lab 开源首个视觉-语言模型:dots.vlm1小红书 hi lab 团队正式发布 dots.vlm1 ——这是“dots”模型家族中的首款视觉-语言模型(VLM),标志着其在多模态理解方向上的重要突破。 GitHub:https://github...多模态模型# dots.vlm1# 小红书8个月前03710
FireRedTTS-2:面向长对话场景的流式多说话人语音合成系统在播客制作、智能客服和实时对话系统中,自然流畅的多说话人语音合成是一项关键能力。然而,当前主流的对话式TTS(Text-to-Speech)技术普遍存在几个核心问题: 需要预先提供完整对话文本,无法支...语音模型# FireRedTTS-2# 小红书7个月前02230
图像编辑模型FireRed-Image-Edit:小红书团队出品,让图片编辑像说话一样简单小红书智能创作基础技术团队正式推出 FireRed-Image-Edit——一款通用图像编辑模型,凭借原生编辑架构、精准指令遵循能力,在广泛场景下实现高保真、视觉一致的编辑效果,既打破了专业修图的门槛...图像模型# FireRed-Image-Edit# 图像编辑模型# 小红书2个月前02170
小红书开源FireRed-Image-Edit 1.1:引入智能体工作流,支持 10+ 元素融合与专业级人像精修小红书智能创作基础技术团队正式推出 FireRed-Image-Edit-1.1。作为前代通用图像编辑模型的升级版,1.1 版本在保留强大编辑能力的基础上,重点攻克了身份一致性、多图像复杂控制及领域专...图像模型# FireRed-Image-Edit 1.1# 小红书4周前0950
使用 Nano Banana Pro 制作 Instagram 与小红书风格的 3D 弹出效果图片以下为两套高度结构化的提示词模板,专为 Nano Banana Pro 设计,用于生成具有“破框而出”3D 效果的社交媒体风格图像。每套均包含构图、UI 元素、人物姿态、光影与质感等关键维度,确保输出...提示词# Instagram# Nano Banana Pro# 小红书2个月前0400