字节跳动推出AnimateDiff-Lightning模型:根据文本描述生成视频,还可以视频转视频字节跳动推出了AnimateDiff-Lightning模型,能够更快地根据文本描述生成视频,比起原来的AnimateDiff模型,速度提升十倍以上。 模型地址:https://huggingface...视频模型# AnimateDiff-Lightning# 字节跳动1年前06470
字节跳动推出基于音频驱动人物肖像新框架Loopy:专门用于生成与音频同步的逼真人像视频字节跳动和浙江大学的研究人员推出新型人工智能模型Loopy,它专门用于生成与音频同步的逼真人像视频。Loopy的核心特点是完全基于音频信号来驱动人像动作,而不需要额外的空间信号来辅助控制动作,这使得生...新技术# Loopy# 人物# 字节跳动2年前06420
字节跳动推出文生图模型SDXL-Lightning:基于SDXL1.0基础模型提炼SDXL-Lightning是由字节跳动发布的一款速度极快的文生图模型,它采用新型扩散模型蒸馏方法,优化扩散模型,能在短时间内高效生成分辨率为1024像素的高品质图像。 模型地址:https://hu...新技术# SDXL-Lightning# SDXL1.0# 字节跳动2年前06230
字节跳动推出新颖视频合成方法Boximator:可控制画面范围及运动方向字节跳动发布了一种新颖视频合成方法Boximator,主要用于生成具有丰富和精细运动控制的高质量视频。Boximator引入了两种约束类型:硬边框(hard box)和软边框(soft box),允许...新技术# Boximator# 字节跳动# 视频合成2年前06160
字节跳动推出 USO:统一风格与主体生成模型,开源全方案赋能创作字节跳动智能创作实验室UXO项目组近期发布了UXO家族的新成员——USO(统一风格-主体优化定制模型)。这款模型打破了现有技术中“风格驱动”与“主体驱动”生成相互孤立的困境,能在单一框架下自由组合任意...图像模型# USO# 字节跳动# 统一风格与主体生成模型7个月前05990
字节推出TextToon:在实时环境中将真人的头像转换成卡通化的形象罗切斯特大学和字节跳动的研究人员推出TextToon,它能够在实时环境中将真人的头像转换成卡通化的形象。就像魔法一样,这项技术可以把你从视频中的头像变成你想要的任何卡通风格,比如美国漫画风格、皮克斯动...新技术# TextToon# 字节跳动1年前05920
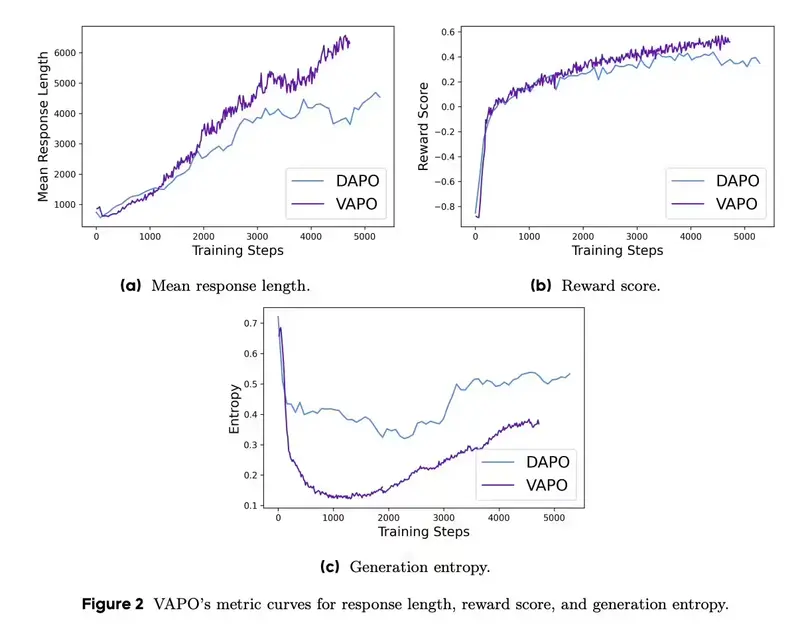
字节跳动推出VAPO框架:让大语言模型在复杂推理任务中更高效字节跳动Seed研究团队发布了一项名为 VAPO 的强化学习训练框架。这一框架专为提升大语言模型(LLM)在复杂、冗长任务中的推理能力而设计,特别是在数学推理和长链推理(Long Chain-of-T...新技术# VAPO# 大语言模型# 字节跳动12个月前05880
字节跳动推出专注于提升多模态理解与推理能力的视觉-语言基础模型Seed1.5-VL字节跳动正式推出 Seed1.5-VL,这是一款专注于提升多模态理解与推理能力的视觉-语言基础模型。Seed1.5-VL 不仅在视觉和视频理解任务中表现出色,还在智能体相关任务及复杂推理挑战中展现了卓...多模态模型# Seed1.5-VL# 字节跳动# 视觉-语言基础模型11个月前05300
字节跳动推出基于修正流Transformer 架构的新型图像和视频生成模型家族Goku香港大学和字节跳动的研究人员推出新型图像和视频生成模型家族Goku,它基于修正流Transformer 架构,实现了行业领先的图像和视频联合生成性能。Goku 的目标是通过高质量的视觉内容生成,推动媒...视频模型# Goku# 字节跳动# 视频生成1年前05080
字节跳动Seed团队发布WideSearch:首个面向大规模信息收集的智能体评估基准在信息过载的时代,获取“更多”并不等于“更有效”。真正制约效率的,往往不是找不到某个具体答案,而是面对海量目标时的系统性整理能力——比如,为一个行业筛选出上百家公司数据,或从成千上万条招聘信息中精准匹...新技术# WideSearch# 字节跳动# 智能体评估基准8个月前04960
字节跳动与浙大联合发布轻量高效TTS模型MegaTTS3字节跳动和浙江大学的研究人员推出的一款轻量级TTS模型:MegaTTS3,0.45B,高质量语音克隆,支持中英文以及中英文混合,支持口音强度控制,后面会支持更细粒度的发音和时长调整。 GitHub:h...语音模型# MegaTTS3# TTS模型# 字节跳动1年前04840
字节跳动 & 复旦大学联合提出智能海报生成新框架 DreamPoster在 AI 生成图像(AIGC)领域,海报设计一直是极具挑战性的任务之一。它不仅要求模型理解文本描述,还需要兼顾视觉美感、排版逻辑和品牌一致性。近日,字节跳动与复旦大学的研究团队联合提出了一种新的文本...图像模型# DreamPoster# 字节跳动# 海报设计9个月前04470