
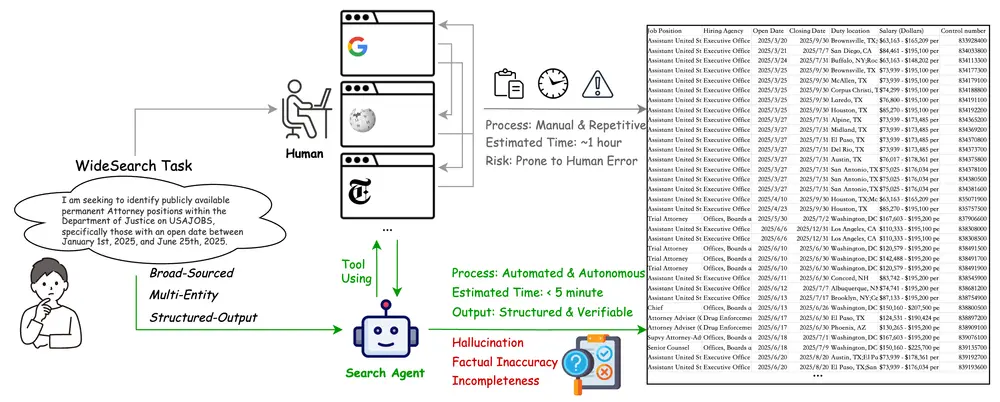
在信息过载的时代,获取“更多”并不等于“更有效”。真正制约效率的,往往不是找不到某个具体答案,而是面对海量目标时的系统性整理能力——比如,为一个行业筛选出上百家公司数据,或从成千上万条招聘信息中精准匹配个人条件。
这类任务本身不复杂,但规模庞大、重复性强,极易成为生产力瓶颈。为了衡量AI智能体是否能胜任此类工作,字节跳动Seed团队推出了一个新的基准测试框架:WideSearch。
- 项目主页:https://widesearch-seed.github.io
- GitHub:https://github.com/ByteDance-Seed/WideSearch
- 数据:https://huggingface.co/datasets/ByteDance-Seed/WideSearch
它不是另一个问答系统评测,而是专门用于评估智能体在大规模、广度导向的信息收集任务中的表现。它的出现,填补了当前智能体评估体系中一个重要空白。
为什么需要WideSearch?
现有的主流评估框架多聚焦于“深度”任务:
- DeepSearch:解决“找不到关键信息”的问题;
- DeepResearch:关注“能否写出高质量报告”。
而现实中的另一类需求长期被忽视:“我能做,但事情太多”。
这类任务的核心挑战不是推理难度,而是覆盖全面性、执行一致性和结果结构化能力。例如:
- 金融分析师要列出过去三年营收增长超过20%的中国新能源企业;
- 招聘顾问需汇总北美地区所有开放的远程数据科学家岗位及其薪资范围。
这些任务需要系统性地搜索、筛选、验证并结构化输出数百条记录。人工完成耗时费力,自动化则面临新风险:遗漏、误判、幻觉、格式错乱。
因此,必须有一个专门的基准来评估智能体在这一类任务上的可靠性与完整性。WideSearch应运而生。
WideSearch的设计理念:从“深挖”到“广收”
WideSearch定义了一种新的任务范式——宽上下文信息收集(wide-context information collection)。其核心目标是:
让智能体在开放网络环境中,自主完成大规模、多来源、结构化的信息聚合。
与传统搜索不同,它强调:
- 系统性覆盖:不是回答一个问题,而是穷尽符合条件的所有实例;
- 结构化输出:结果必须组织为预定义表格,而非自由文本;
- 可验证性:每一条数据都需能回溯至公开来源。
为此,团队提出了六大设计原则,确保基准的科学性与实用性:
| 原则 | 说明 |
|---|---|
| 高搜索量与广度 | 任务涉及大量独立数据点,需广泛检索 |
| 时间与环境不变性 | 答案不随时间频繁变化,便于复现 |
| 客观可验证性 | 每个事实有明确真值,支持一致性评分 |
| 公开可访问性 | 所需信息可通过通用搜索引擎获取 |
| 依赖外部工具 | 仅靠模型参数知识无法解决,必须调用搜索等工具 |
| 场景多样性 | 覆盖18个行业领域,提升泛化能力 |
如何构建和评估?
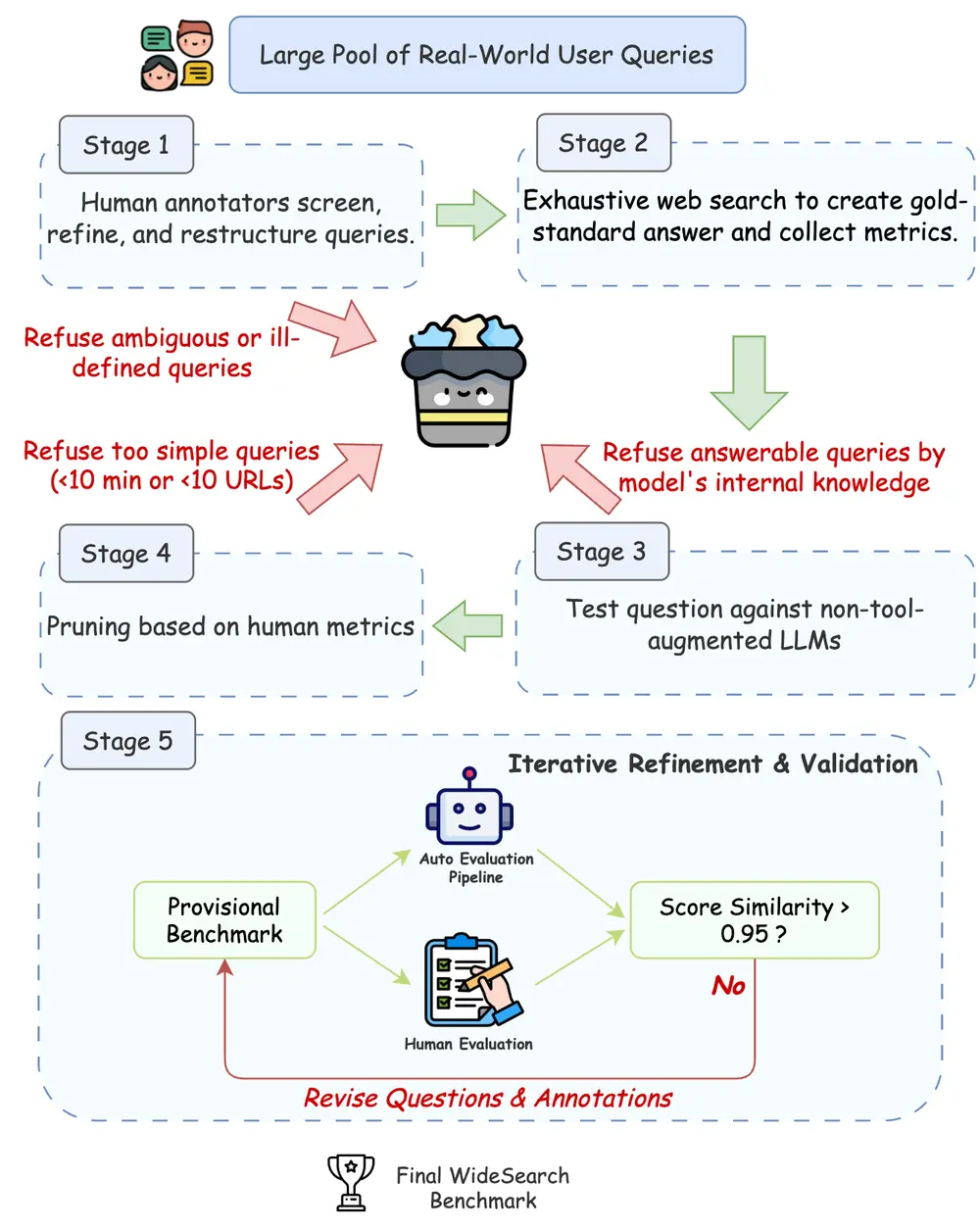
1. 数据集构建:五阶段质量控制
WideSearch包含200个手工构建的问题,中英文各100题,涵盖金融、科技、医疗、教育等多个领域。每个问题都经过严格的五阶段流程:
- 问题筛选:基于真实用户查询场景设计;
- 金标准标注:人工收集完整答案并建立基准表;
- 参数知识过滤:排除可通过模型内部知识直接回答的问题;
- 难度评估:确保任务确实需要外部检索;
- 迭代验证:多轮交叉核验,保证准确性和一致性。
2. 任务形式:查询 + 表格架构
每个任务由两部分组成:
- 一条自然语言指令(如:“列出全球市值前十的半导体公司”)
- 一个预设的表格结构(含字段如公司名、国家、市值、成立年份等)
智能体需通过调用搜索工具,在互联网中查找信息,并填充表格。
3. 自动化评估流程
评估分为三步:
- 表格对齐:将智能体输出的表格与标准答案进行行匹配;
- 单元格验证:逐项检查内容正确性,结合规则与LLM判断语义等价;
- 混合评分:使用规则处理数值、日期等确定性内容,LLM处理名称变体、单位转换等模糊匹配。
该流程兼顾效率与精度,支持大规模自动化评测。
关键评估指标
为全面衡量智能体表现,WideSearch采用三个层级的指标:
| 指标 | 含义 | 用途 |
|---|---|---|
| 成功率(SR) | 输出与标准答案完全一致的比例 | 衡量端到端可靠性 |
| 行级F1分数 | 正确且完整行的比例 | 评估整体记录完整性 |
| 项级F1分数 | 单元格级别的精确率与召回率 | 分析细粒度准确性 |
此外,报告策略也区分两种能力:
- Avg@N:N次运行的平均得分,反映稳定性;
- Pass@N / Max@N:N次中的最佳表现,体现峰值潜力。
实验结果:智能体仍有明显差距
团队测试了多种主流单代理与多代理系统,并对部分商业AI产品进行了端到端网页交互测试。同时还邀请人类参与者完成20个随机抽样任务。
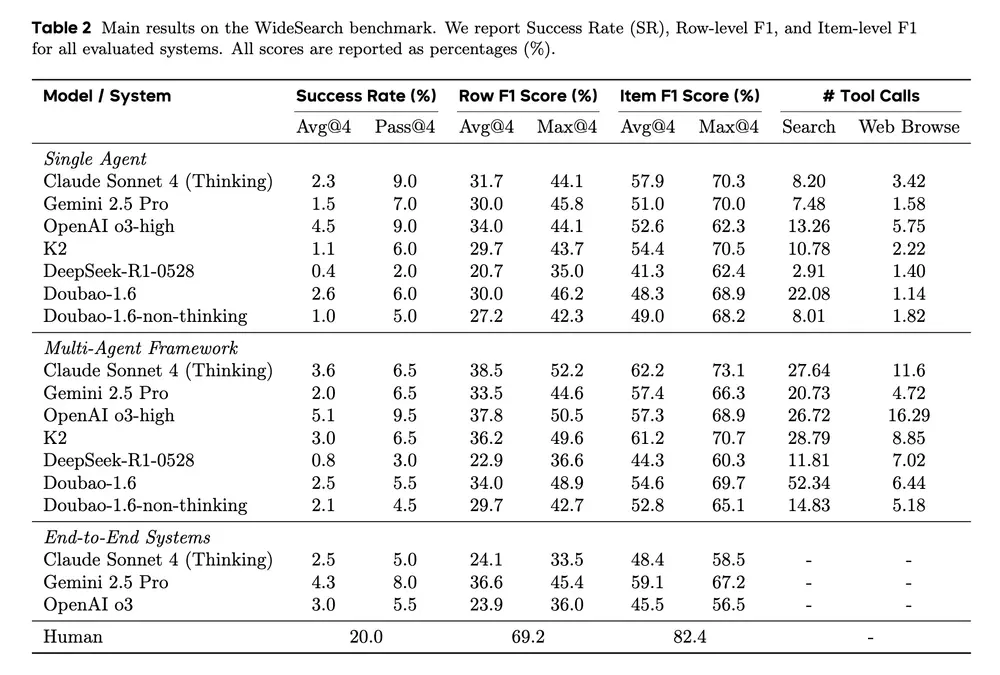
主要发现如下:
- 智能体整体成功率接近0%,表现最好的多代理框架也仅达到 5.1%;
- 在项级F1上,最优系统约为 60%,距离实用仍有差距;
- 人类专家在充分时间下可达近100%准确率,但单次尝试的成功率仅为20%,说明任务本身具有挑战性;
- 错误分析显示,智能体的主要短板在于:
- 查询分解不完整
- 缺乏反思与迭代机制
- 对检索结果的利用效率低
- 容易陷入局部覆盖或重复采集
这表明,当前智能体尚不具备成熟的“大规模信息组织”能力,尤其缺乏任务规划与自我修正机制。

意义与展望
WideSearch的意义不仅在于提供一个新基准,更在于推动智能体能力边界的重新定义。
当AI不再只是“回答问题”,而是“完成信息工程”时,我们需要新的衡量标准。WideSearch正是朝着这个方向迈出的关键一步。
未来,随着智能体架构的演进(如引入记忆机制、任务分解模块、验证反馈循环),我们有望看到在WideSearch上的显著提升。而这一进步,将直接转化为现实场景中的效率跃迁——无论是市场调研、竞品分析,还是政策追踪、人才搜寻。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











