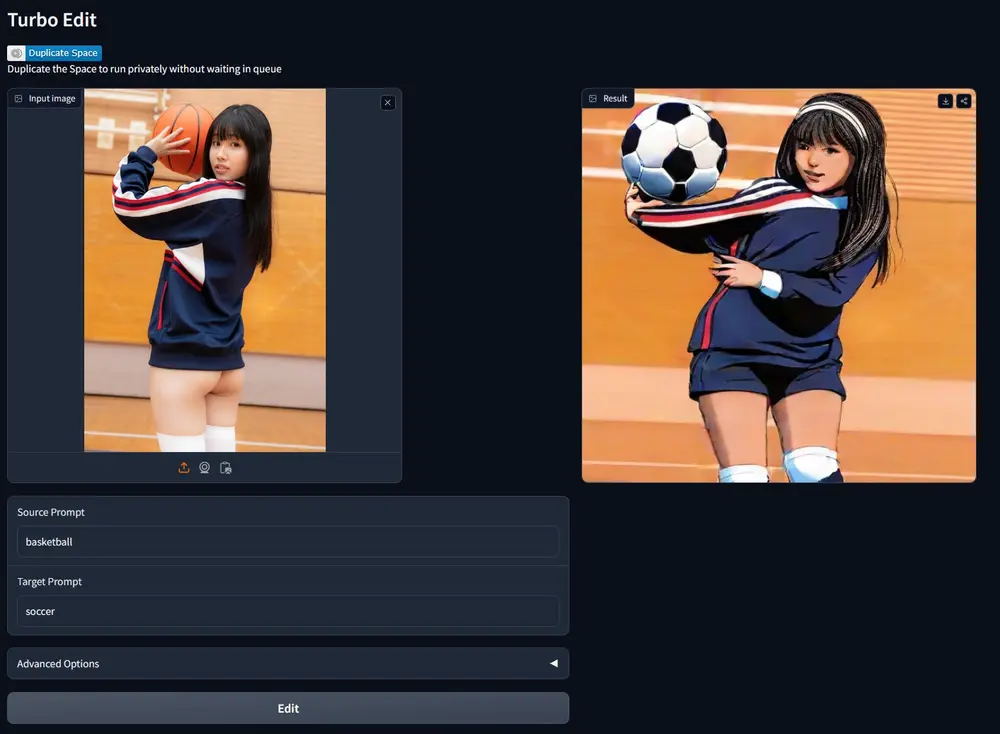
Adobe推出全新图像编辑方法TurboEdit:实现基于文本的即时图像编辑Adobe Research推出了一种全新的图像编辑方法TurboEdit,它能够实现基于文本的即时图像编辑,它利用了所谓的"少步骤扩散模型"(few-step diffusion models),在...新技术# TurboEdit# 图像编辑2年前05470
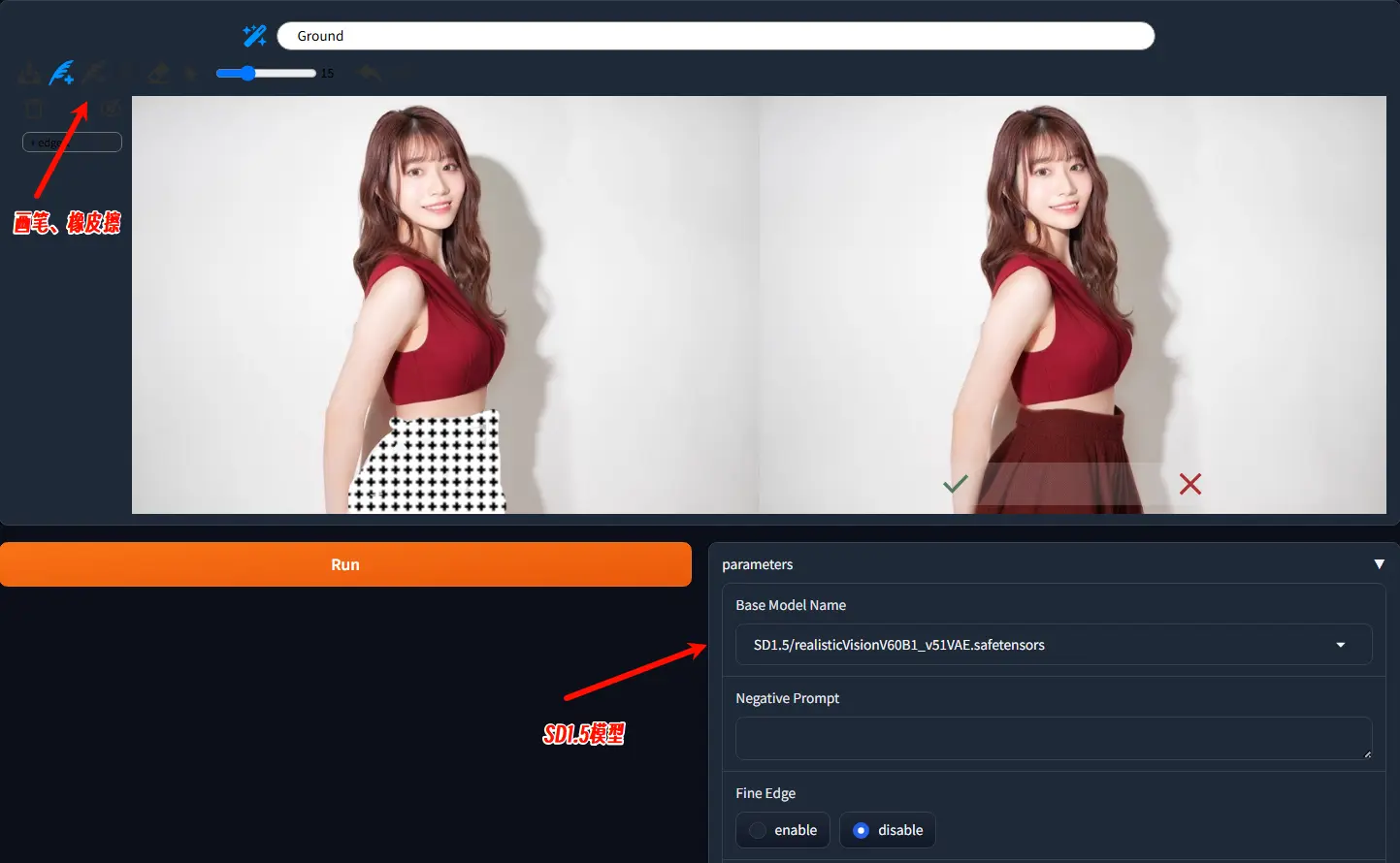
基于SD1.5模型的智能交互式图像编辑系统MagicQuill香港科技大学、蚂蚁集团、浙江大学和香港大学的研究人员推出智能交互式图像编辑系统MagicQuill,该系统基于扩散模型(SD1.5模型)构建,允许用户通过三种直观的笔触:添加(add)、减去(subt...工具# MagicQuill# SD1.5模型# 图像编辑1年前05430
阶跃星辰发布 NextStep-1:140 亿参数自回归模型,用“连续令牌”重塑图像生成在图像生成领域,自回归模型长期被视作“文本专家,视觉弱项”——它们擅长逐词生成语言,却难以像扩散模型那样精细构建图像。而如今,阶跃星辰(StepFun)正试图打破这一边界。 GitHub:https...图像模型# NextStep-1# 图像生成# 图像编辑8个月前05350
新型图像编辑工具StyleFeatureEditor:结合了AI的最新进展,使用户能够以前所未有的细节级别和灵活性来编辑图像俄罗斯高等经济大学、AIRI和德国不来梅建筑大学的研究人员推出新型图像编辑工具StyleFeatureEditor,它是基于一种名为StyleGAN的生成对抗网络(GAN)的。StyleGAN是一种特...新技术# StyleFeatureEditor# 图像编辑2年前05220
基于文本的编辑框架TurboEdit:能够使用极少的几步就能基于文本指令编辑真实图片特拉维夫大学的研究人员推出一种流行的基于文本的编辑框架TurboEdit,它能够使用极少的几步就能基于文本指令编辑真实图片。这种技术利用了所谓的“扩散模型”(diffusion models),这是一...新技术# TurboEdit# 图像编辑# 编辑框架2年前04800
ObjectMate:能够在无需微调的情况下,实现对象插入和主题驱动的图像生成对象插入和主体驱动生成是计算机视觉中的两个重要任务,旨在将给定的对象合成到由图像或文本指定的场景中。具体来说: 对象插入:将一个对象无缝地插入到目标场景中,要求合成后的图像在姿态、光照等方面看起来逼真...新技术# ObjectMate# 图像编辑1年前04770
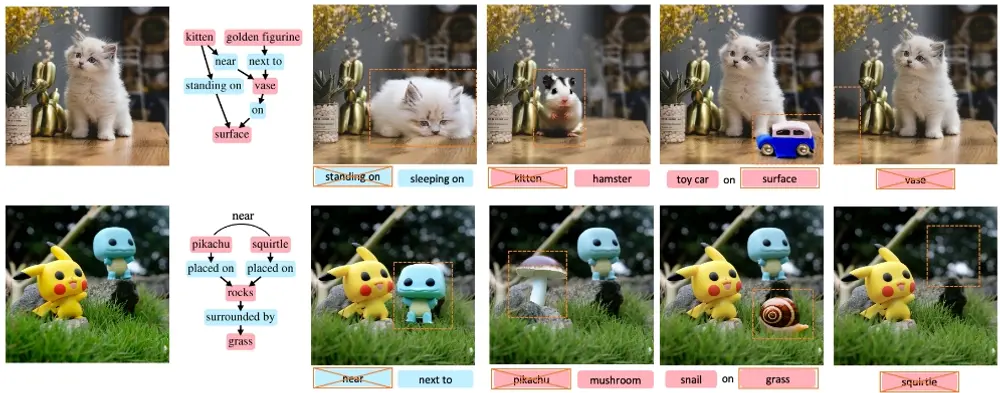
结合了大语言模型与文生图模型的新框架SGEdit:用于基于场景图的精确和灵活的图像编辑场景图提供了一种结构化、层次化的图像表示方式,其中节点和边分别代表图像中的对象及其相互关系。这种方式不仅能够帮助用户更直观地理解图像内容,还能作为图像编辑的有效接口,极大提升了编辑工作的准确性和灵活性...新技术# SGEdit# 图像编辑# 大语言模型1年前04680
图像编辑方法Click2Mask:通过简单的点击来实现对图片的局部编辑,而不需要复杂的遮罩或详细的描述耶路撒冷希伯来大学的研究人员推出图像编辑方法Click2Mask,它能够让用户通过简单的点击来实现对图片的局部编辑,而不需要复杂的遮罩或详细的描述。总的来说,Click2Mask提供了一种直观且高效的...新技术# Click2Mask# 图像编辑2年前04630
图像编辑通用模型OMNI-EDIT:通过专家监督来构建,能够执行多种图像编辑任务指令引导的图像编辑方法通过在自动合成或手动标注的图像编辑对上训练扩散模型,展示了显著的潜力。然而,这些方法在实际应用中仍然存在明显的不足。滑铁卢大学和威斯康星大学麦迪逊分校的研究人员识别了导致这一差距...多模态模型# OMNI-EDIT# 图像编辑1年前04620
图像编辑框架InstantDrag:通过简单的拖拽操作来编辑图片,就像在手机上操作APP一样直观和快速首尔国立大学和浦项科技大学的研究人员推出图像编辑框架InstantDrag,它能够让用户通过简单的拖拽操作来编辑图片,就像在手机上操作APP一样直观和快速。例如,你有一张图片,你想要移动图片中的某个部...新技术# InstantDrag# 图像编辑2年前04620
统一视觉理解与生成框架UniWorld:支持 20+语义图片编辑任务北京大学深圳研究生院、鹏城实验室、兔展AI的研究人员推出统一视觉理解与生成框架UniWorld,它基于强大的视觉-语言模型和对比语义编码器,能够同时处理图像感知和图像操控任务。 GitHub:http...图像模型# UniWorld# 图像生成# 图像编辑10个月前04580
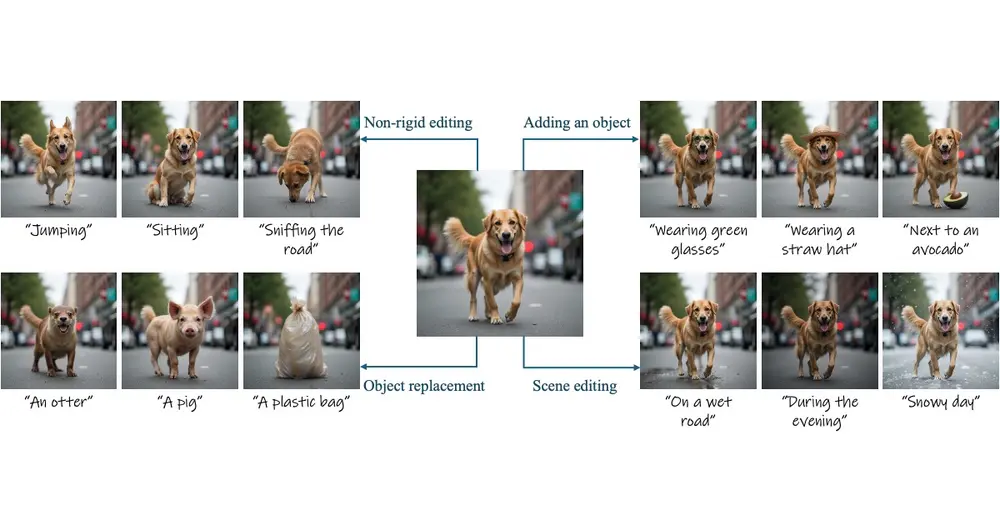
无需训练的图像编辑技术Stable Flow:执行各种类型的图像编辑操作,包括非刚性编辑、物体添加、物体替换和全局场景编辑Snap Research、耶路撒冷希伯来大学、特拉维夫大学和赖希曼大学的研究人员推出图像编辑方法Stable Flow,这是一种无需训练的图像编辑技术,能够执行各种类型的图像编辑操作,包括非刚性编辑...新技术# Stable Flow# 图像编辑1年前04050