高效、可扩展框架CtrLoRA:结合了基础 ControlNet 和条件特定 LoRAs 的可控图像生成框架来自中国科学院计算技术研究所和中国科学院大学的研究人员推出一种用于可控图像生成的高效、可扩展框架CtrLoRA,这是一个结合了基础 ControlNet 和条件特定 LoRAs 的可控图像生成框架。简...图像模型# ControlNe# CtrLoRA# LoRAs12个月前03870
Stability AI推出其最新的图像生成模型系列Stable Diffusion 3.5(SD3.5):更具可定制性和多功能性,同时在性能上也有所提升在经历了一系列由技术故障和许可变更引发的争议后,Stability AI宣布了其最新的图像生成模型系列—Stable Diffusion 3.5(SD3.5),新的Stable Diffusion 3...图像模型# SD3.5# Stability AI# Stable Diffusion 3.512个月前04630
混合自回归变换器HART:高效生成高分辨率图像现有的自回归(AR)视觉生成模型在生成高分辨率图像时面临两大挑战:离散分词器的图像重建质量较差,以及生成1024px图像的训练成本过高。为了解决这些问题,麻省理工学院、英伟达和清华大学的研究人员提出了...图像模型# HART# 混合自回归变换器12个月前03920
MagicTailor框架:让用户对生成的图像中的特定视觉元素进行精确控制近年来,文本到图像(T2I)扩散模型取得了显著进展,能够从简单的文本提示中生成高质量的图像。然而,这些模型在精确控制特定视觉概念生成方面仍然面临挑战。现有的方法可以通过参考图像学习复制给定的概念,但缺...图像模型# MagicTailor# 图像定制12个月前05600
文字处理能力出众!Playground推出最新文生图模型Playground v3Playground 推出了Playground v3(PGv3),这是Playground最新的文本到图像模型,在多个测试基准上达到了最先进的(SoTA)性能,在图形设计能力上表现出色,并引入了新的...图像模型# Playground v3# 文生图模型12个月前04410
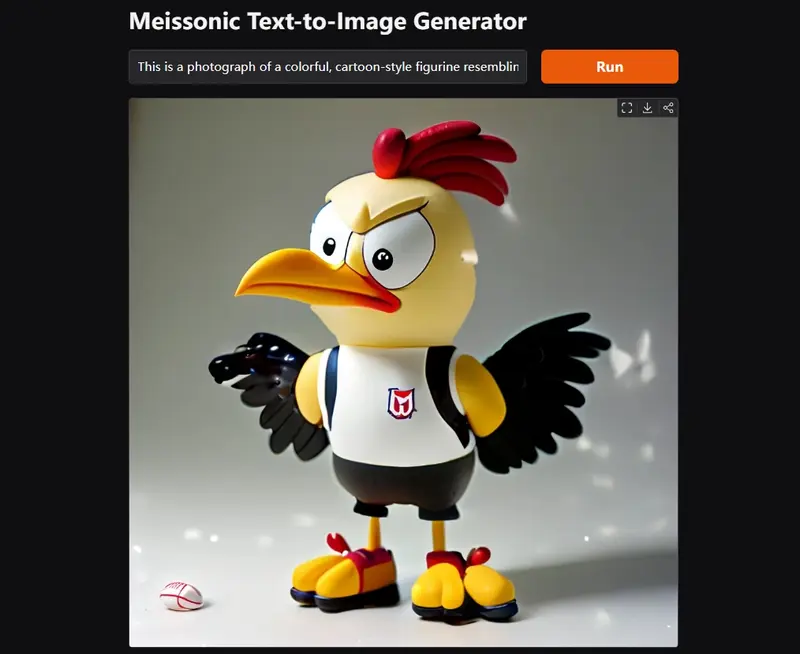
非自回归 MIM 文生图合成模型Meissonic:生成高质量、高分辨率的图像随着大语言模型(LLMs)在自然语言处理任务中的显著进步,研究人员开始探索类似的文本到图像合成方法。与此同时,扩散模型已经成为视觉生成的主流方法。然而,由于语言和视觉任务之间存在显著的操作差异,开发统...图像模型# Meissonic# 文生图合成模型12个月前03860
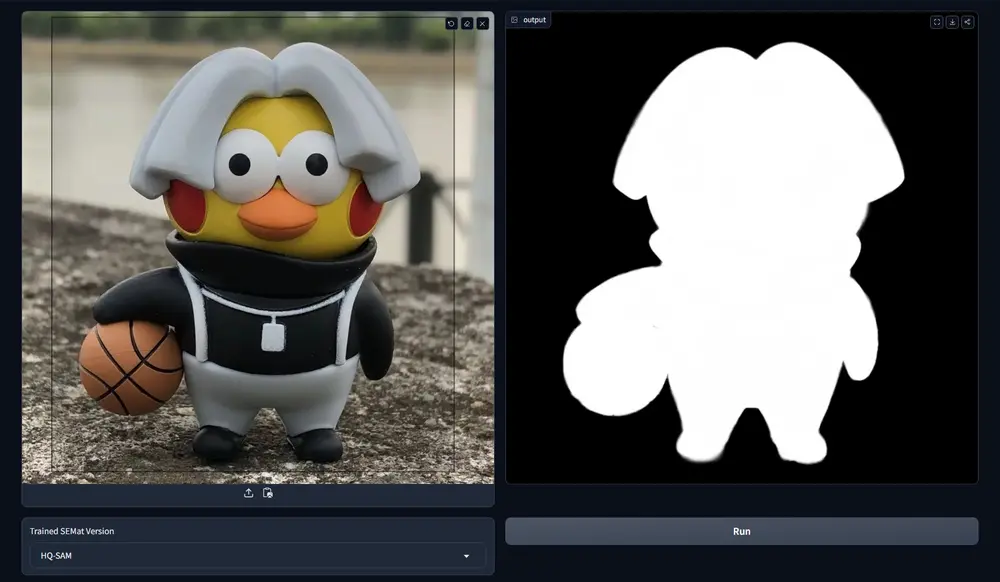
新型图像抠图方法SEMat:能够在复杂的自然场景中实现更精确的前景对象抠图近年来,交互式分割模型(如 SAM)在图像分割任务中取得了显著进展。然而,这些模型在应用于交互式抠图任务时面临挑战,尤其是在处理复杂和遮挡场景时。现有的方法通常在合成数据上训练模型,但这些模型难以泛化...图像模型# SEMat# 图像抠图12个月前06240
新型文生图框架SANA:能够高效地生成高达4096×4096分辨率的高清晰度图像英伟达、麻省理工学院和清华大学的研究人员推出新型文本到图像生成框架SANA,它能够高效地生成高达4096×4096分辨率的高清晰度图像。SANA的核心优势在于它不仅生成的图像质量高,而且与文本的匹配度...图像模型# SANA# 文生图框架12个月前07790
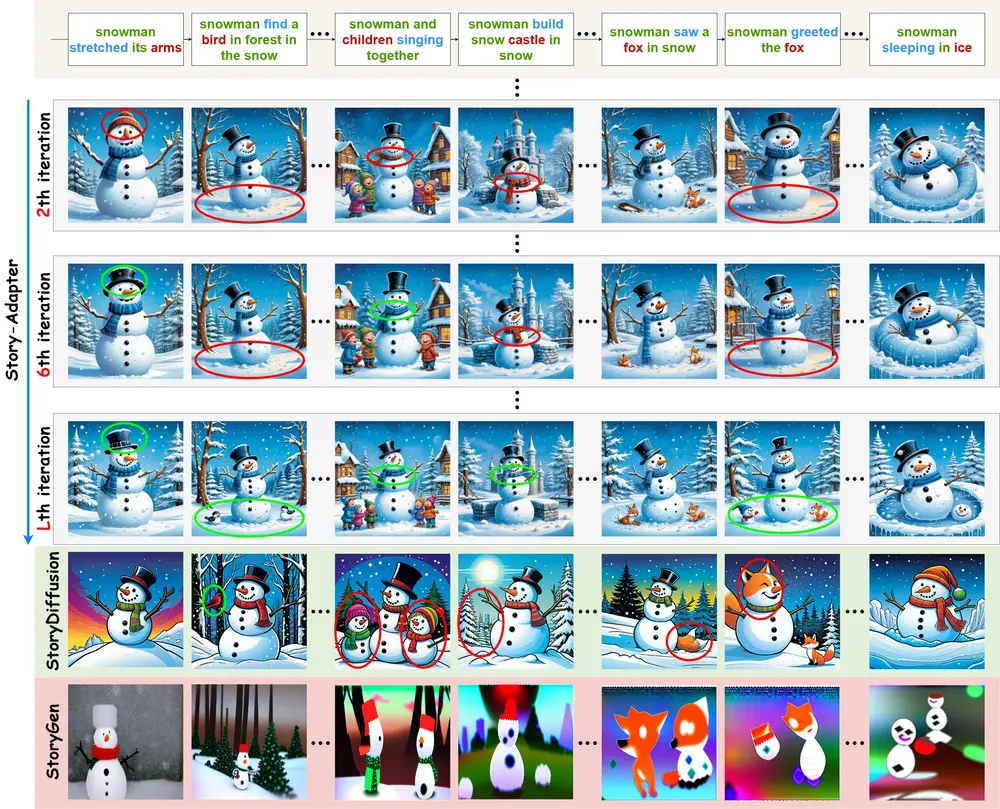
用于长篇故事视觉化的迭代框架Story-Adapter:根据长篇故事的文字描述生成一系列既连贯又具有丰富细节的图像加州大学圣克鲁斯分校、杭州电子科技大学和新加坡理工学院的研究人员推出一个用于长篇故事视觉化的迭代框架Story-Adapter,Story-Adapter能够根据长篇故事的文字描述生成一系列既连贯又具...图像模型# Story-Adapter# 长篇故事视觉化12个月前09280
IterComp:为了解决文本到图像生成中的复杂和组合问题而设计的新框架清华大学、北京大学、LibAI Lab、中国科学技术大学、牛津大学和普林斯顿大学的研究人员推出AI绘画新框架IterComp,它是为了解决文本到图像生成中的复杂和组合问题而设计的。简单来说,就是当你给...图像模型# IterComp# 文本到图像12个月前06600
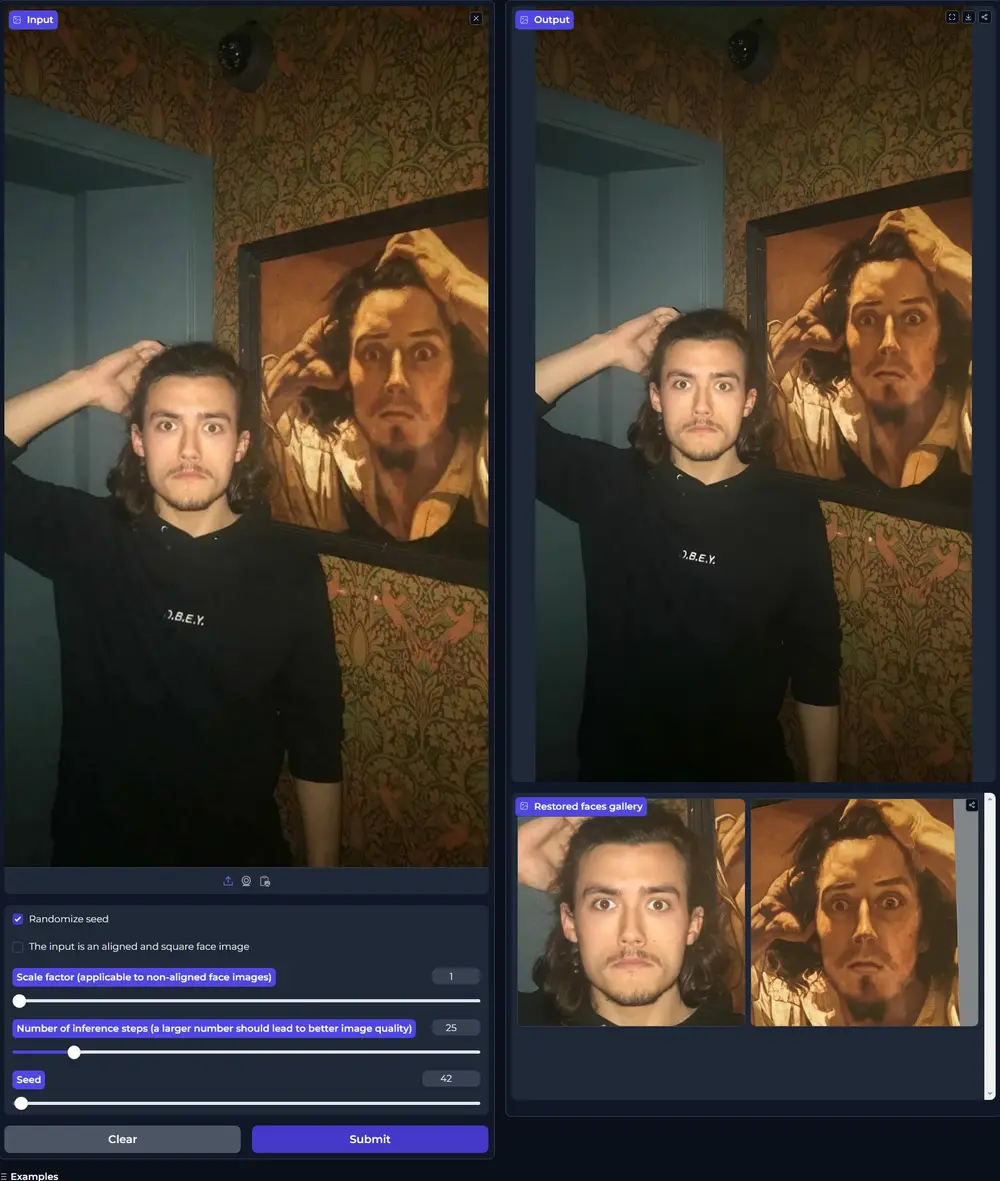
图像恢复算法PMRF:改善从损坏的图像中恢复出高质量、逼真图像以色列理工学院的研究人员推出图像恢复算法PMRF(Posterior-Mean Rectified Flow,后验均值校正流),这个算法的目标是改善从损坏的图像中恢复出高质量、逼真图像的方法。具体来说...图像模型# PMRF# 图像恢复算法12个月前06440
Momo XL:基于SDXL的动漫风格模型Momo XL 是一个基于 Stable Diffusion XL (SDXL) 的动漫风格模型,经过微调后,能够生成具有详细和生动美学的优质动漫风格图像。这款模型专为艺术家和动漫爱好者设计,提供了多...图像模型# Momo XL# SDXL# 动漫风格12个月前04980