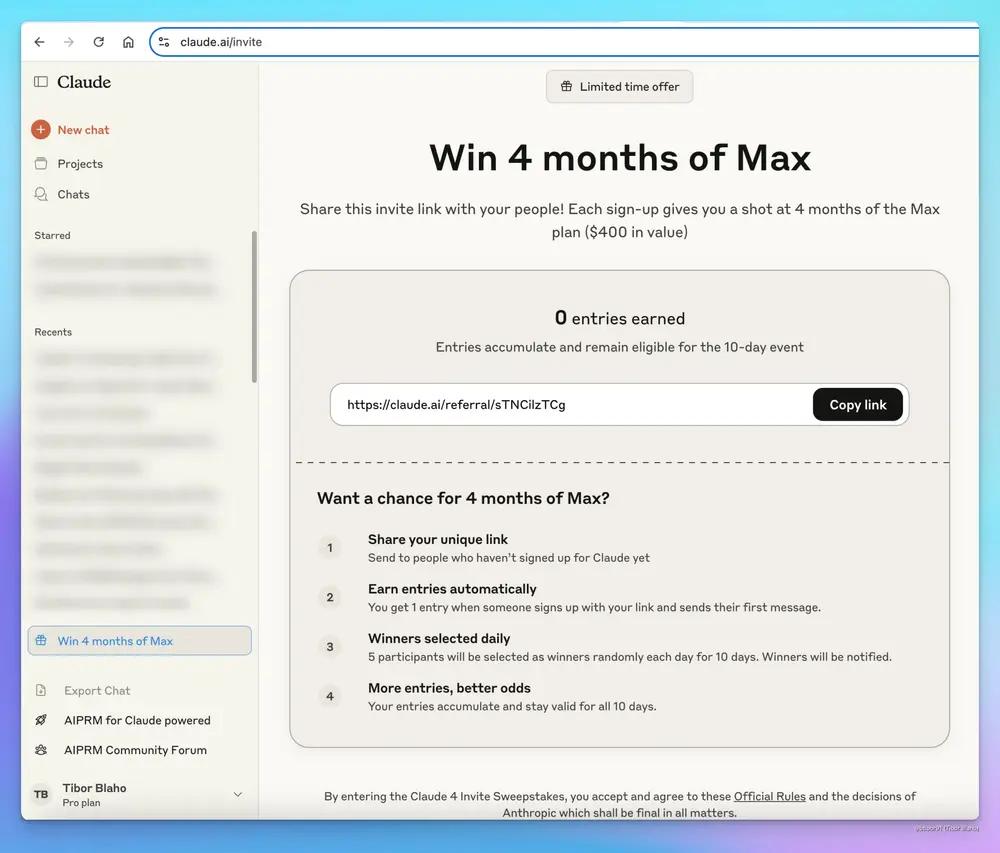
Claude Max 或将捆绑 Claude Code,Anthropic 加速推动开发者市场增长Anthropic 正在为其高端订阅计划Claude Max增加更多吸引力。根据内部测试横幅显示,Anthropic 可能会将Claude Code直接整合到 Max 计划中,而无需用户额外支付 AP...早报# Anthropic# Claude Code# Claude Max8个月前03140
PSHuman:利用多视角扩散模型先验的3D人体建模新框架真实感3D人体建模在虚拟现实、增强现实、电影制作、游戏开发和医疗等领域具有广泛的应用。尽管单目全身重建方法取得了显著进展,但它们通常依赖于前视图和/或预测的后视图,这导致了由于问题的病态性质和复杂的自...新技术# 3D人体建模# PSHuman1年前03140
3D高效框架Make-It-Animatable:将任意3D人物模型快速制作成可用于动画的角色中国科学技术大学和腾讯的研究人员推出高效框架Make-It-Animatable,它用于将任意3D人物模型快速制作成可用于动画的角色。这个框架能够在不到一秒钟的时间内,无论3D模型的形状和姿势如何,都...新技术# 3D# Make-It-Animatable1年前03140
字节跳动旗下AI编程工具Trae带来一系列令人瞩目的更新:聊天与构建器的融合、上下文能力的拓展等字节跳动旗下AI编程工具Trae带来一系列令人瞩目的更新,这些改进将极大地提升开发体验,重塑 AI 开发的未来。 1. 聊天与构建器的融合 Trae v1.3.0版本将聊天(Chat)和构建器(Bui...早报# Trae# 字节跳动8个月前03130
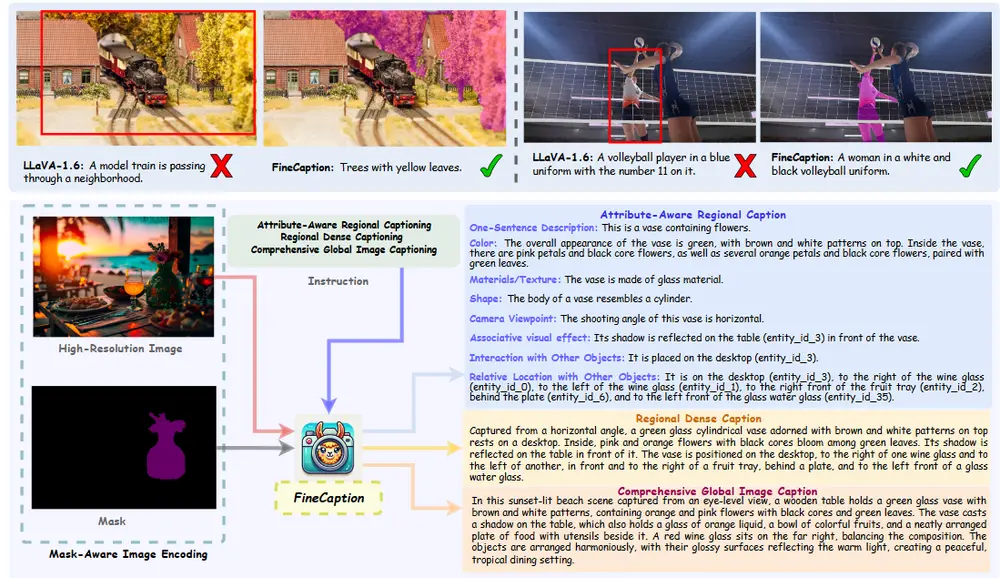
视觉-语言模型FINECAPTION:专注于在任意位置和任意粒度级别上进行组合式图像描述随着大型视觉语言模型(VLMs)的出现,多模态任务的发展取得了显著进展。这些模型在图像和视频字幕、视觉问答以及跨模态检索等应用中展现了强大的推理能力。然而,尽管VLMs具有卓越的表现,它们在细粒度图像...新技术# FINECAPTION# 视觉-语言模型1年前03130
SageAttention2:适用于即插即用推理加速的精确4位注意力机制尽管线性层的量化技术已经广泛应用于深度学习模型中,但在加速注意力机制方面的应用仍然有限。为了提高注意力计算的效率并保持高精度,清华大学的研究团队提出了 SageAttention2,这是一个基于低精度...新技术# SageAttention2# 推理加速1年前03130
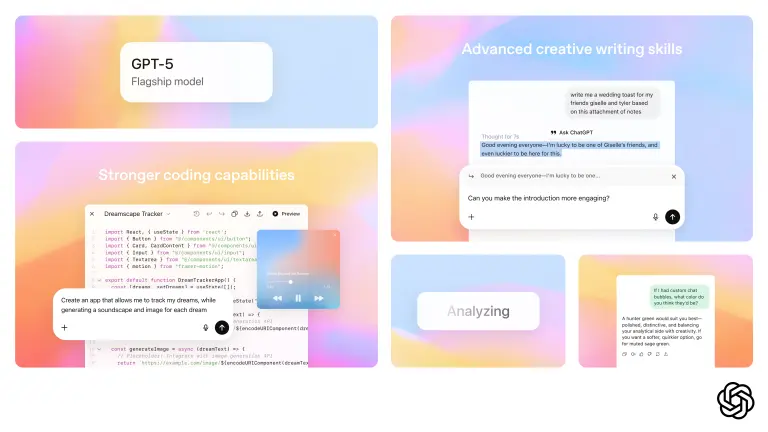
OpenAI 发布 统一智能模型GPT-5:迈向“AGI”的关键一步OpenAI 于今日正式推出其最新旗舰模型 —— GPT-5,标志着 ChatGPT 进入一个全新阶段。这不仅是性能的升级,更是一次范式转变:从“回答问题的聊天机器人”向“代表用户完成任务的智能代理...早报# GPT-5# OpenAI5个月前03120
腾讯混元推出新型框架 Hunyuan-GameCraft:为游戏环境生成高动态、交互式的视频内容腾讯混元项目组和华中科技大学的研究人员推出新型框架 Hunyuan-GameCraft,为游戏环境生成高动态、交互式的视频内容。Hunyuan-GameCraft 能够从单张图像和对应的提示出发,生成...新技术# Hunyuan-GameCraft# 腾讯混元6个月前03120
基于图像扩散先验的深度修复模型DepthLab:从单张图像中生成完整的3D场景香港大学、香港科技大学、蚂蚁集团、阿尔托大学和通义实验室的研究人员推出DepthLab ,它是一个基于图像扩散先验的深度修复模型,用于从单张图像中生成完整的3D场景。DepthLab旨在解决深度数据中...新技术# 3D场景# DepthLab# 深度修复模型1年前03120
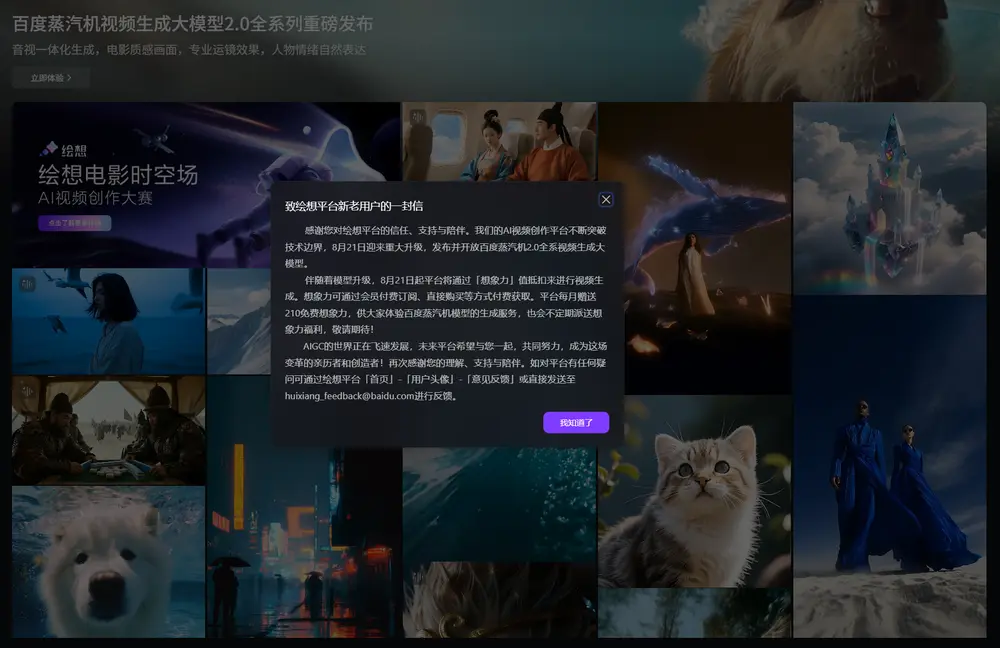
百度蒸汽机2.0 上线:首次实现多人有声视频一体化生成百度正式发布 MuseSteamer 2.0 —— 其音视频一体化生成模型的重大升级版本,在行业内首次实现多人有声视频的端到端联合生成。 这意味着,用户只需输入一段文字描述,系统即可自动生成包含多个角...早报# MuseSteamer 2.0# 百度# 蒸汽机2.04个月前03110
豆包上线AI播客功能:一键将长文转为双人对话音频6月17日,豆包正式全量上线AI播客功能。用户只需上传PDF文档或网页链接,即可一键生成一段拟真度极高的双人对话式播客节目。 这项功能尤其适合需要处理大量阅读材料的用户。有参与内测的用户反馈称,会将一...早报# AI播客# 豆包6个月前03110
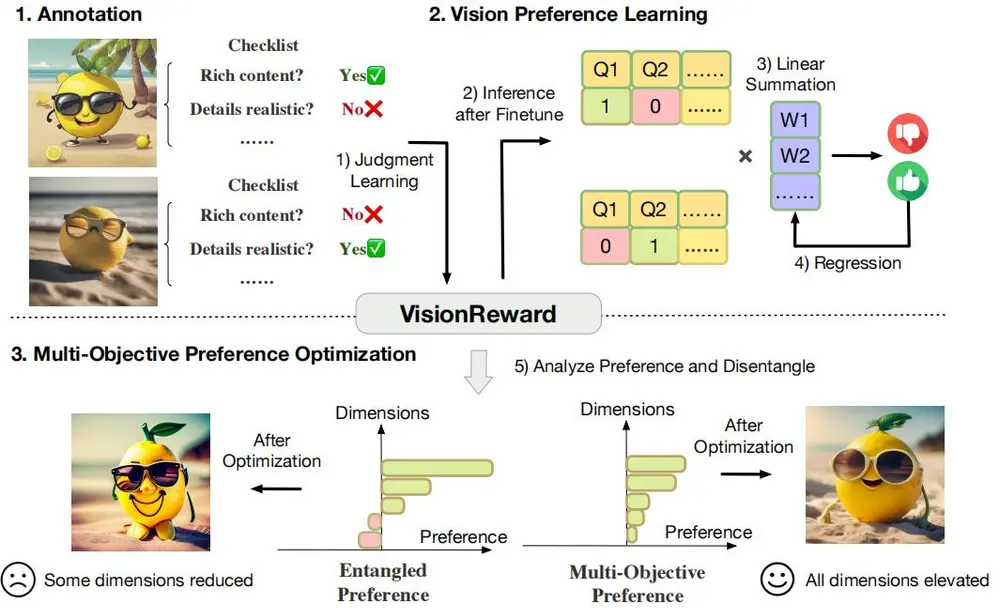
VisionReward:用于图像和视频生成的细粒度多维度人类偏好学习框架清华大学和智谱AI的研究人员推出VisionReward,这是一个用于图像和视频生成的细粒度多维度人类偏好学习框架。VisionReward通过构建一个细粒度且多维度的奖励模型,将人类对图像和视频的偏...新技术# VisionReward12个月前03110