FASHN 虚拟试穿升级到v1.5版:更高分辨率、更灵活宽高比,性能依旧虚拟试穿技术正以前所未有的速度发展,而 FASHN AI 再次走在了行业前沿。在最新发布的 FASHN v1.5 中,迎来了一个令人兴奋的升级:更高的输出分辨率、更灵活的输入尺寸支持,同时保持原有的运...早报# FASHN v1.5# 虚拟试穿11个月前04670
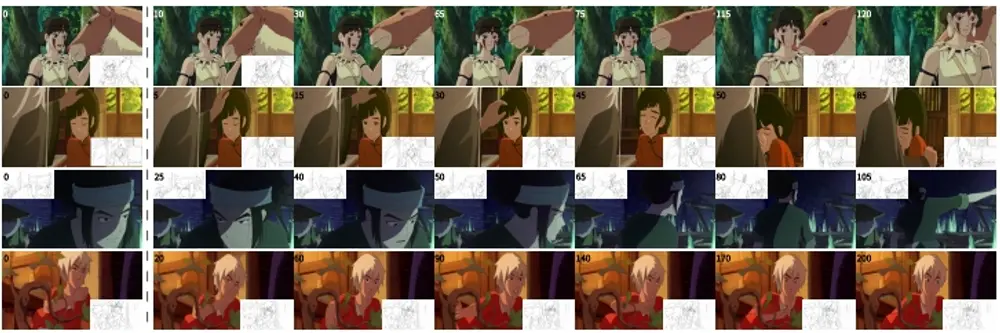
基于参考的线条艺术视频上色的视频扩散框架LVCD:用于根据参考图像和线稿序列为动画视频着色香港城市大学和腾讯的研究人员推出基于参考的线条艺术视频上色的视频扩散框架LVCD,用于根据参考图像和线稿序列为动画视频着色。这种方法能够生成长时间一致的、高质量的动画视频。LVCD在保持长时间一致性和...新技术# LVCD# 视频上色2年前04660
micro_diffusion :一种低成本训练文生图模型的方法索尼 AI和加州大学河滨分校的研究人员推出了一种低成本训练大规模文本到图像(Text-to-Image, T2I)扩散模型的方法micro_diffusion 。该方法通过创新的“延迟掩码”(defe...新技术# micro_diffusion# 文生图模型1年前04650
FlexGen框架:能够根据单一视角的图像、文本提示或两者的结合来灵活生成可控制且一致的多视图图像来自香港科技大学(广州)、香港科技大学和趣玩的研究人员开发了一个名为FlexGen的框架,它能够根据单一视角的图像、文本提示或两者的结合来灵活生成可控制且一致的多视图图像。想象一下,你给FlexGen...新技术# FlexGen1年前04650
谷歌放大招!全新视频编辑神器Flow即将亮相I/O大会谷歌正计划在 2025年5月20日 举行的 Google I/O大会 上发布一款名为 Flow 的实验性新产品。这款工具最近出现在 Google Labs 中,其标语为“激发你的内在故事讲述者,通过生...早报# Flow# 视频编辑器# 谷歌11个月前04640
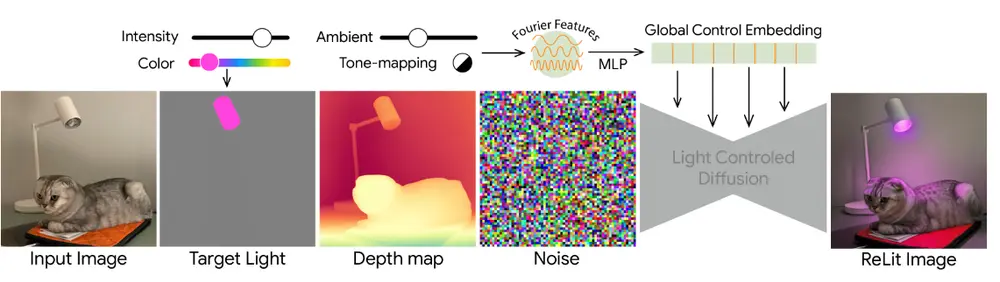
高通AI研究院推出一个为移动设备优化的视频生成模型MobileVD高通AI研究院推出了一个为移动设备优化的视频生成模型Mobile Video Diffusion(MobileVD),该模型的目标是在保持生成视频的质量和控制力的同时,显著降低计算需求,使得在移动设备...新技术# MobileVD# 视频生成模型1年前04640
半策略偏好优化方法SePPO:用于优化和微调文生图模型,使其更好地符合人类的审美和偏好罗切斯特大学、普渡大学、延世大学、腾讯 AI 实验室和华盛顿大学的研究人员推出半策略偏好优化方法SePPO,用于优化和微调扩散模型(如用于生成图像的模型),使其更好地符合人类的审美和偏好,而无需依赖外...新技术# SePPO# 半策略偏好优化# 文生图模型2年前04640
北京人工智能研究院推出新型图像生成模型OmniGen北京人工智能研究院推出新型图像生成模型OmniGen,与流行的扩散模型(例如,Stable Diffusion)不同,OmniGen不再需要额外的模块,如ControlNet或IP-Adapter来处...新技术# OmniGen# 图像生成模型1年前04640
图像编辑方法Click2Mask:通过简单的点击来实现对图片的局部编辑,而不需要复杂的遮罩或详细的描述耶路撒冷希伯来大学的研究人员推出图像编辑方法Click2Mask,它能够让用户通过简单的点击来实现对图片的局部编辑,而不需要复杂的遮罩或详细的描述。总的来说,Click2Mask提供了一种直观且高效的...新技术# Click2Mask# 图像编辑2年前04640
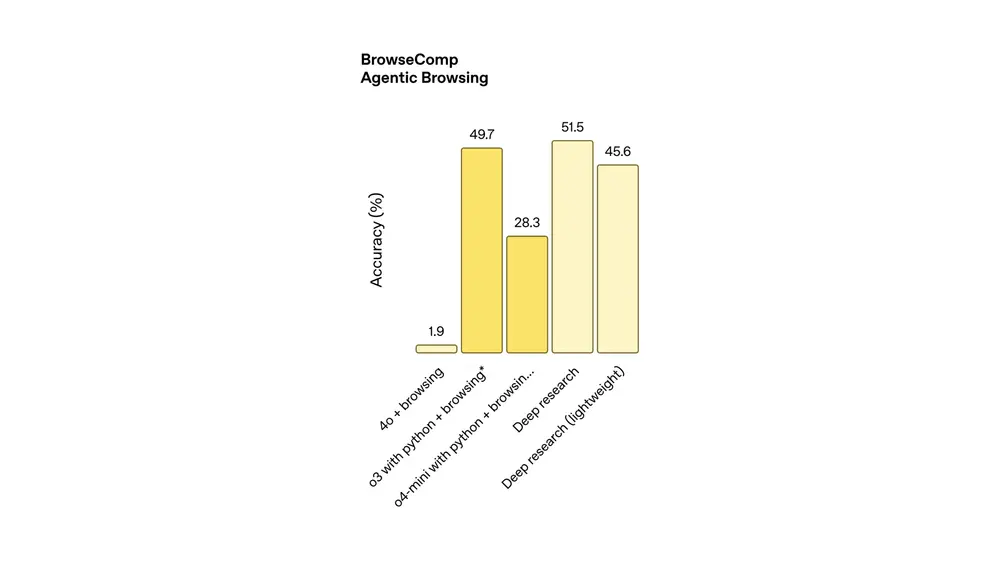
OpenAI 推出轻量级 Deep Research 版本,免费用户也能体验 AI 研究助手两个月前,OpenAI 推出了Deep Research,一款专为复杂、多步骤研究任务设计的 AI 工具。它能够筛选海量在线信息,生成带有引用的综合报告,类似于一个数字化的研究分析师。最初,这项功能仅...早报# AI 研究助手# Deep Research# OpenAI12个月前04620
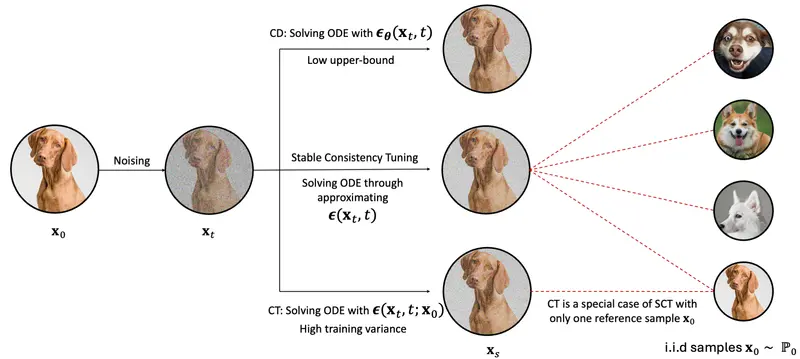
新框架SCT:旨在理解和改进一致性模型香港中文大学和卡内基梅隆大学的研究人员提出了一个名为Stable Consistency Tuning(SCT)的新框架,旨在理解和改进一致性模型(Consistency Models)。一致性模型是...新技术# SCT# 一致性模型1年前04620
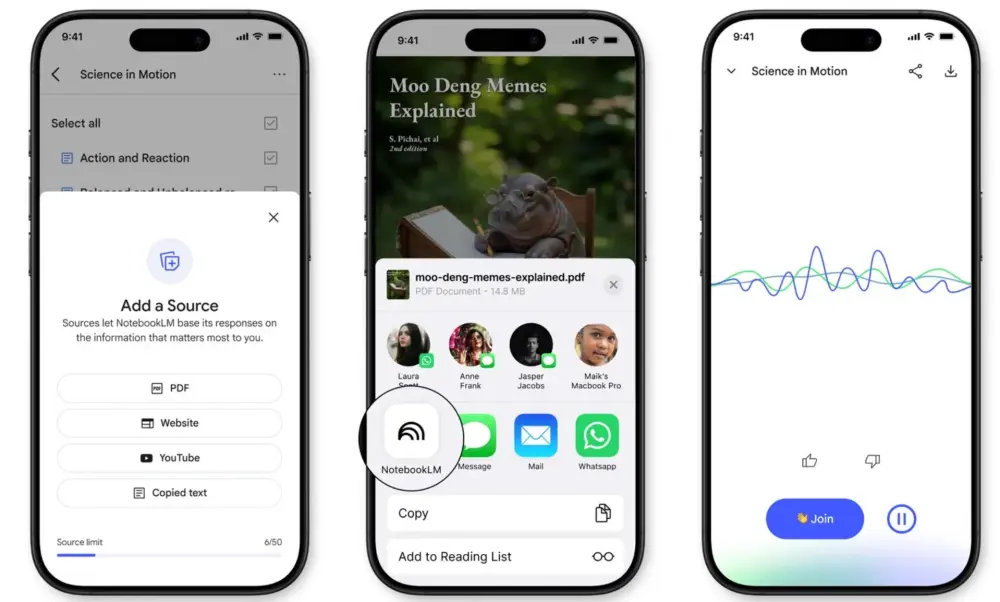
谷歌 NotebookLM 移动版将于5 月 20 日正式上线,现已开放预订谷歌的 NotebookLM 移动应用即将在 5 月 20 日与大家见面!目前,安卓和 iOS 版本的应用已经开放预订。这款基于 AI 的笔记和研究助手自 2023 年推出以来,一直受到用户的青睐,但...早报# NotebookLM# 谷歌11个月前04610