Google I/O 2025 发布 Native Speech Generation:AI 语音迈入拟真新纪元,免费支持多角色播客制作!在2025年的Google I/O开发者大会上,Google AI Studio推出了一项名为“Native Speech Generation(原生语音生成)”的创新功能,将AI语音生成技术推向了一...早报# Native Speech Generation# 原生语音生成# 谷歌11个月前04890
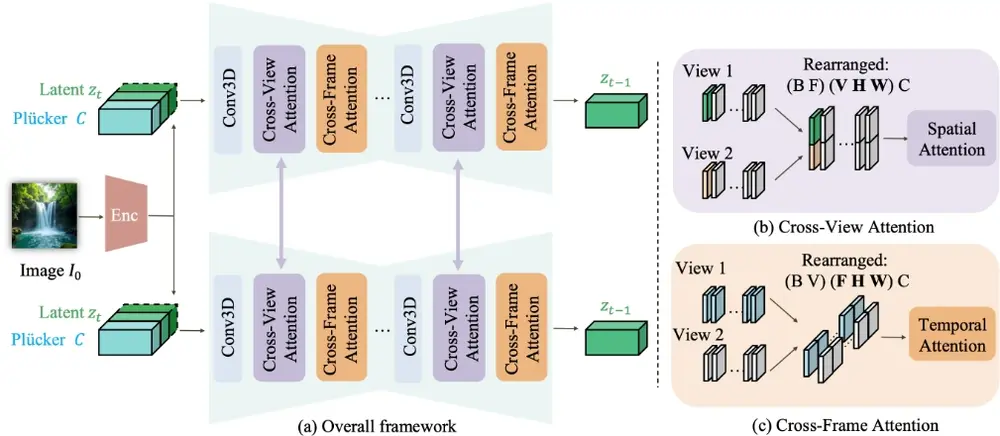
新型框架Cavia:生成具有相机控制功能的多视角视频德克萨斯大学奥斯汀分校、苹果和谷歌的研究人员推出新型框架Cavia,它能够生成具有相机控制功能的多视角视频。简单来说,Cavia可以根据一张图片和一些相机运动的指令,生成一系列从不同角度和时间点观察的...新技术# Cavia1年前04880
韩国科学技术研究院推出专门针对文生图模型的新型数据投毒攻击方法Silent Branding Attack韩国科学技术研究院和DeepAuto.ai的研究人员推出一种新型数据投毒攻击方法Silent Branding Attack ,专门针对文生图模型。该方法能够在文生图模型中隐秘地嵌入特定品牌标志或符号...新技术# Silent Branding Attack# 文生图模型# 韩国科学技术研究院1年前04870
新型端到端模型DnD-Transformer:提高了图像生成任务的质量和效率,为图像生成领域带来了新的可能北京大学、阿里巴巴集团、威斯康星大学麦迪逊分校和北京理工大学的研究人员推出新型端到端模型DnD-Transformer,这是一种用于高效细粒度图像生成的二维自回归Transformer。简单来说,这个...新技术# DnD-Transformer# 图像生成2年前04870
基于物理的交互式3D对象动态生成方法PhysDreamer:利用视频生成技术实现与3D物体进行物理交互来自麻省理工学院、斯坦福大学、 哥伦比亚大学和康奈尔大学的研究人员推出PhysDreamer系统,这是一个基于物理的交互式3D对象动态生成方法。PhysDreamer能够使静态的3D对象通过视频生成模...新技术# 3D对象# PhysDreamer2年前04870
新型视频生成方法TrackGo:根据用户的输入精确控制视频中对象的运动北京航空航天大学和爱诗科技的研究人员推出新型视频生成方法TrackGo,它能够根据用户的输入精确控制视频中对象的运动。这项技术允许用户通过自由形式的遮罩(masks)和箭头来指定目标对象或部分,以及它...新技术# TrackGo# 视频生成2年前04860
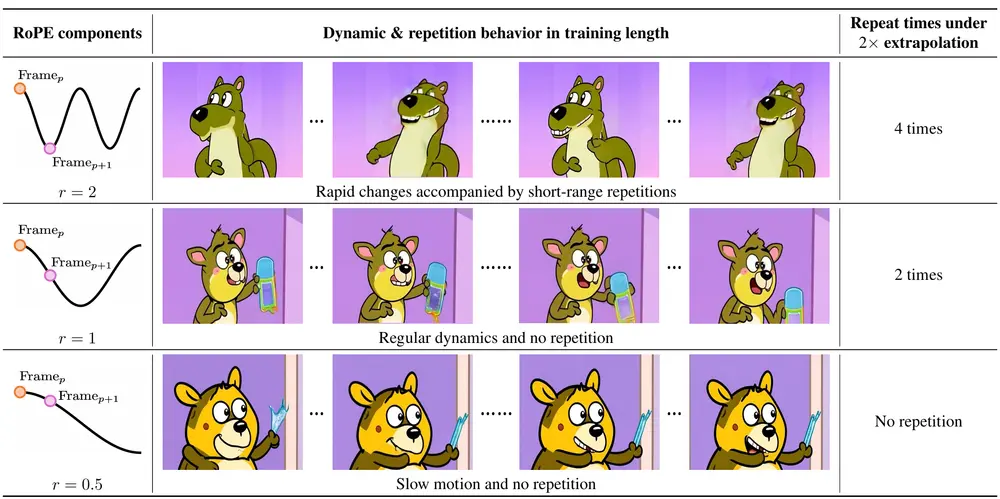
清华大学推出RIFLEx:解决视频扩散模型在生成更长视频时的时空连贯性问题清华大学的研究人员推出RIFLEx,解决视频扩散模型在生成更长视频时的时空连贯性问题。该方法通过调整位置编码中的内在频率,有效抑制重复内容的生成,同时保持运动一致性,无需额外训练或修改模型。 项目主页...新技术# RIFLEx# 清华大学# 视频扩散模型1年前04850
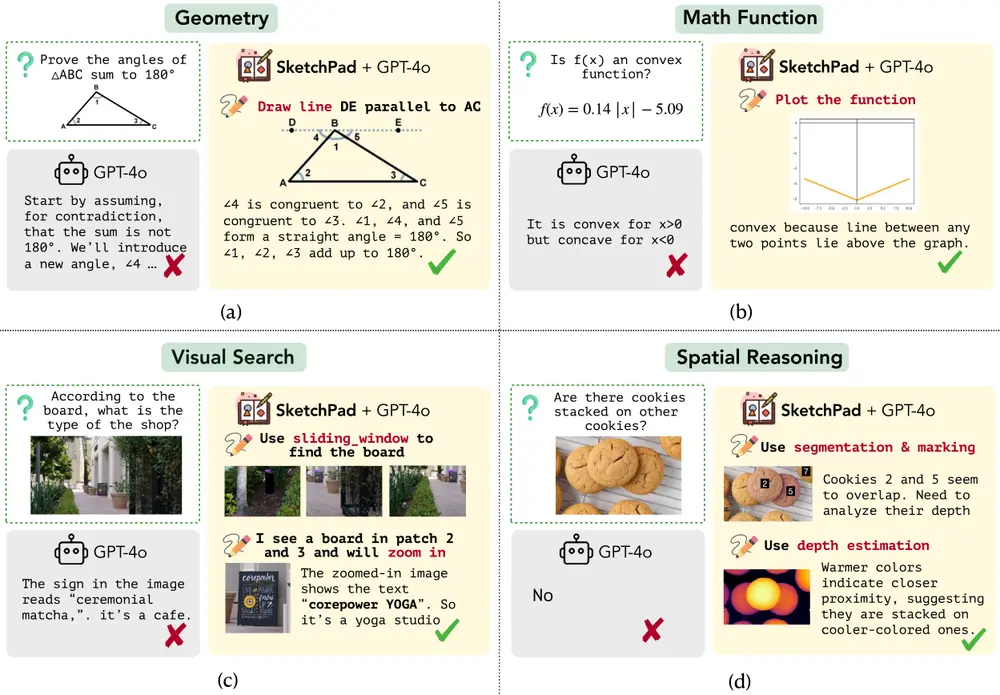
Visual SKETCHPAD 框架:为多模态语言模型提供一个可视化的“草图板”,使其能够在解决问题时生成中间草图并进行推理华盛顿大学、艾伦人工智能研究所和宾夕法尼亚大学的研究人员推出Visual SKETCHPAD 框架,为多模态语言模型(LMs)提供一个可视化的“草图板”,使其能够在解决问题时生成中间草图并进行推理。这...新技术# Visual SKETCHPAD# 多模态语言模型# 草图板12个月前04830
新型文本到图像生成方法FRAP:基于自适应调整每个词汇的提示权重来改善生成图像与提示之间的一致性和真实性阿尔伯塔大学电子与计算机工程系、华为技术加拿大公司和华为麒麟解决方案的研究人员推出新型文本到图像生成方法FRAP,旨在提高由文本提示生成图像的真实性和忠实度,确保生成的图像与文本描述的内容精确匹配。F...新技术# FRAP# 文生图2年前04830
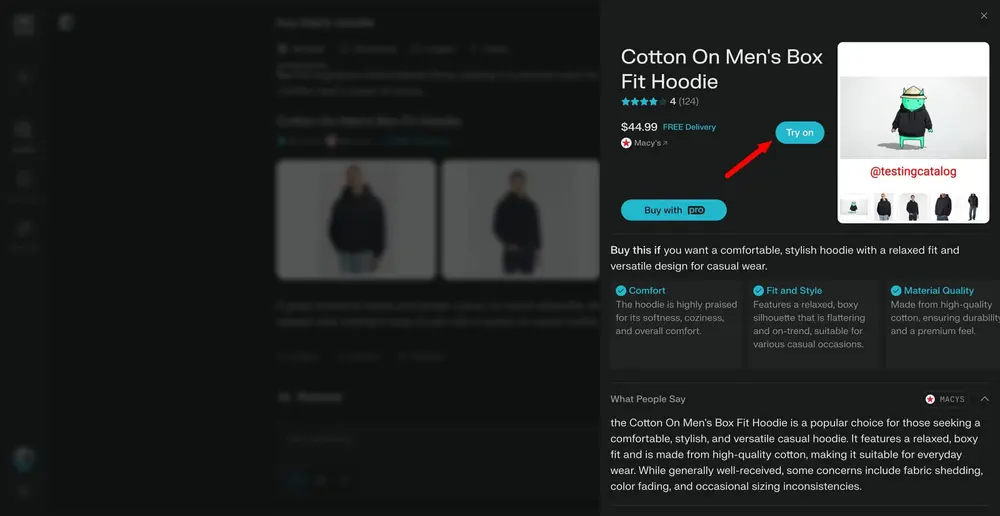
Perplexity 开发 AI 试穿功能,助力在线购物“所见即所得”在线购物虽然方便,但“看不到实物”始终是用户的一大顾虑。为了解决这一痛点,Perplexity 正在开发一项基于人工智能的“虚拟试穿”功能,让用户在购买服装前,能通过上传个人照片生成穿着效果预览图,从...早报# AI 试穿# Perplexity10个月前04820
ObjectMate:能够在无需微调的情况下,实现对象插入和主题驱动的图像生成对象插入和主体驱动生成是计算机视觉中的两个重要任务,旨在将给定的对象合成到由图像或文本指定的场景中。具体来说: 对象插入:将一个对象无缝地插入到目标场景中,要求合成后的图像在姿态、光照等方面看起来逼真...新技术# ObjectMate# 图像编辑1年前04820
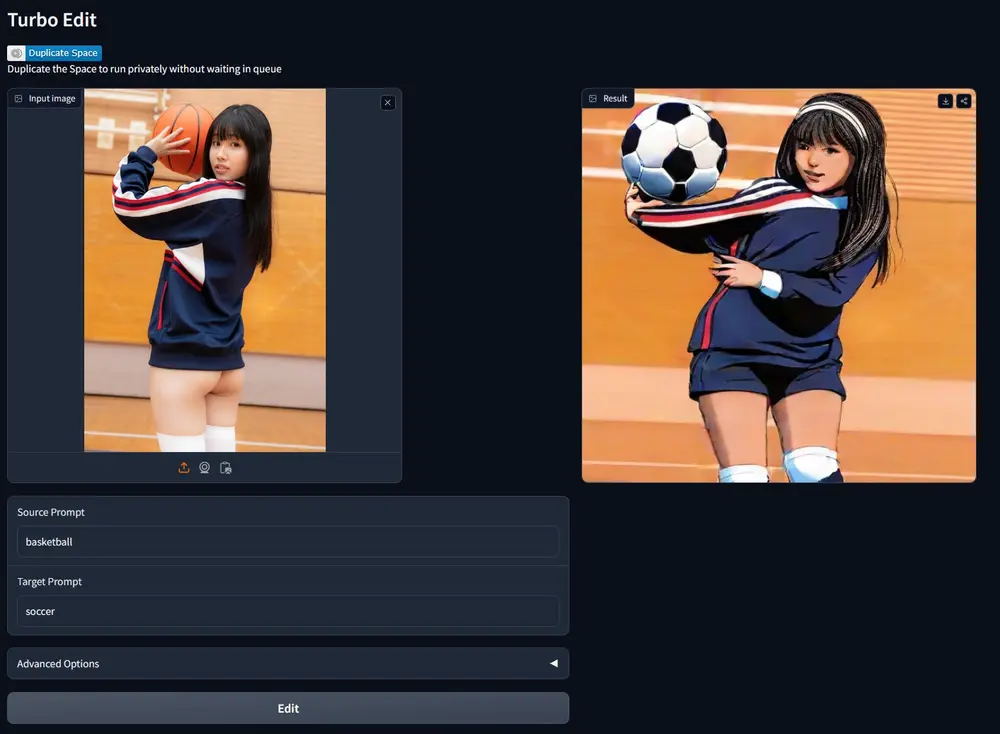
基于文本的编辑框架TurboEdit:能够使用极少的几步就能基于文本指令编辑真实图片特拉维夫大学的研究人员推出一种流行的基于文本的编辑框架TurboEdit,它能够使用极少的几步就能基于文本指令编辑真实图片。这种技术利用了所谓的“扩散模型”(diffusion models),这是一...新技术# TurboEdit# 图像编辑# 编辑框架2年前04820