
清华大学的研究人员推出RIFLEx,解决视频扩散模型在生成更长视频时的时空连贯性问题。该方法通过调整位置编码中的内在频率,有效抑制重复内容的生成,同时保持运动一致性,无需额外训练或修改模型。
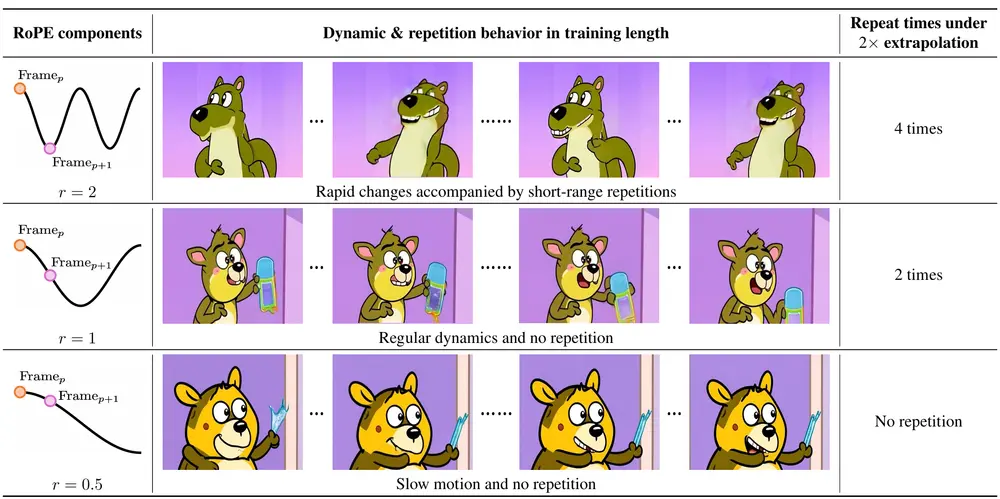
例如,我们有一个视频扩散模型,能够生成时长为 5秒钟的高质量视频。然而,当我们尝试将其扩展到10秒钟时,现有方法可能会导致视频内容重复(例如,某个场景不断循环)或运动速度变慢(例如,动作看起来像是慢动作)。RIFLEx 方法通过调整位置编码中的特定频率成分,可以生成自然流畅的 2 分钟视频,而无需重新训练模型。
目前已支持模型:
| 模型 | 延长 |
|---|---|
| HunyuanVideo | 5s -> 11s |
| CogVideoX-5B | 6s -> 12s |
| Wan2.1 | 5s -> 8s |
目前ComfyUI插件ComfyUI-KJNodes已支持此技术,ComfyUI用户安装此插件后,将节点加入工作流即可。
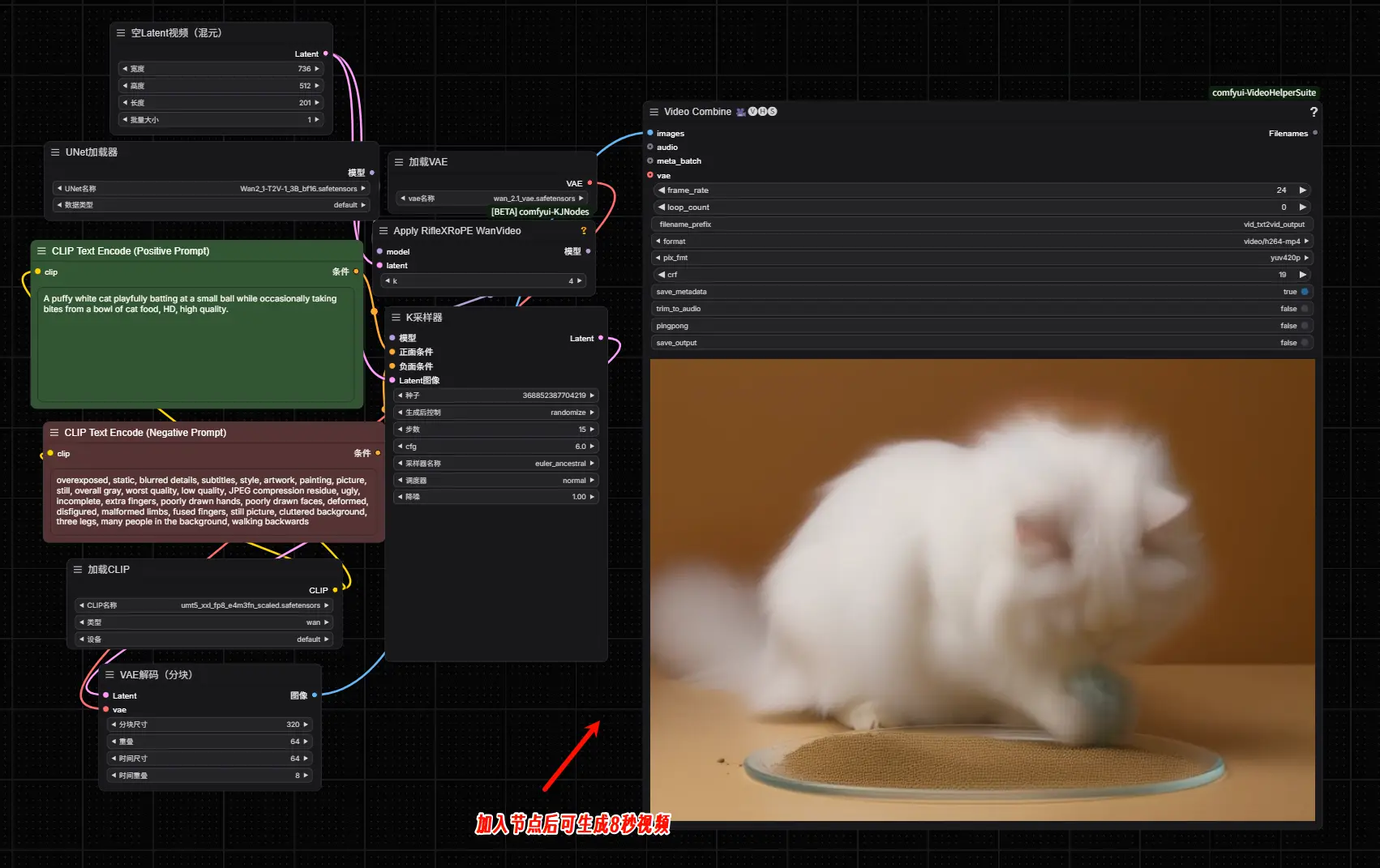
Wan T2V-1.3B工作流:
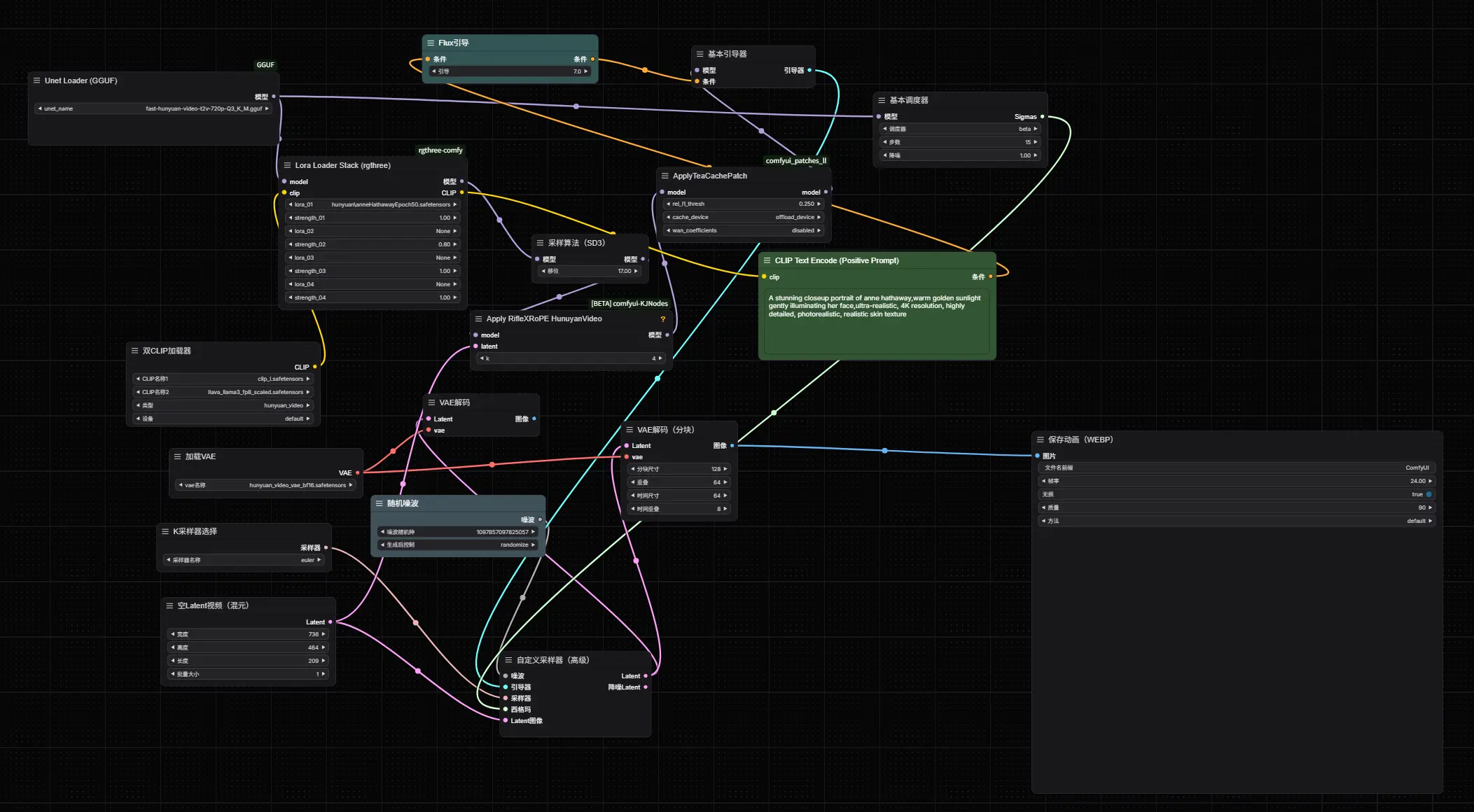
混元文生视频工作流:
主要功能
视频长度扩展:将现有视频扩散模型的生成时长扩展到 2 倍甚至 3 倍,同时保持视频内容的连贯性和自然性。 训练自由(Training-Free):在不需要额外训练的情况下,实现高质量的 2 倍视频长度扩展。 微调支持(Fine-Tuning):通过少量原始长度视频的微调(仅需 1/50,000 的预训练计算量),进一步提升生成视频的质量,支持 3 倍长度扩展。 空间扩展支持:除了时间维度,RIFLEx 还可以应用于空间维度,扩展视频的分辨率。
主要特点
简单高效:RIFLEx 是一种最小化的方法,仅通过调整位置编码中的内在频率来实现长度扩展,无需对模型架构或训练过程进行复杂修改。 无需额外数据:不需要额外的长视频数据进行训练,仅依赖于现有模型的预训练结果。 广泛的适用性:该方法适用于多种现有的视频扩散模型,如 CogVideoX-5B 和 HunyuanVideo。 理论支持:通过分析位置编码中不同频率成分的作用,RIFLEx 提供了一种理论上的解释,说明为什么现有方法会失败,并提出了针对性的解决方案。
工作原理
频率成分分析:RIFLEx 首先分析了位置编码(如 RoPE)中不同频率成分的作用。高频成分捕捉短期依赖关系,容易导致重复;低频成分捕捉长期依赖关系,但可能导致运动速度变慢。 识别内在频率:通过实验发现,不同视频模型中存在一个一致的“内在频率”成分,它在长度扩展时起主导作用。该频率决定了视频内容的重复模式。 降低内在频率:RIFLEx 通过降低内在频率,使其在扩展后仍保持在一个周期内,从而避免重复内容的生成。 微调优化:对于 3 倍扩展,由于内在频率的调整幅度较大,可能需要通过少量的微调来进一步优化生成效果。
应用场景
视频内容创作:在视频制作中,创作者可以通过 RIFLEx 快速生成更长的视频内容,而无需担心重复或运动不自然的问题。例如,生成更长的动画视频、广告视频或故事视频。 视频增强:对于现有视频,RIFLEx 可以用于扩展其时长或分辨率,提升视频的整体质量和视觉效果。 虚拟现实与增强现实:在 VR 和 AR 应用中,RIFLEx 可以生成更长的沉浸式视频内容,增强用户体验。 视频会议与远程协作:通过扩展视频长度,可以在视频会议中生成更自然的背景或动画效果,提升会议的趣味性和互动性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











