
在2025年的Google I/O开发者大会上,Google AI Studio推出了一项名为“Native Speech Generation(原生语音生成)”的创新功能,将AI语音生成技术推向了一个新的高度。这项功能不仅能够将纯文字转换成极为自然的语音内容,还支持多角色对话模式,特别适合模拟播客对谈,让创作者能够轻松打造具有真实感的AI对话节目。
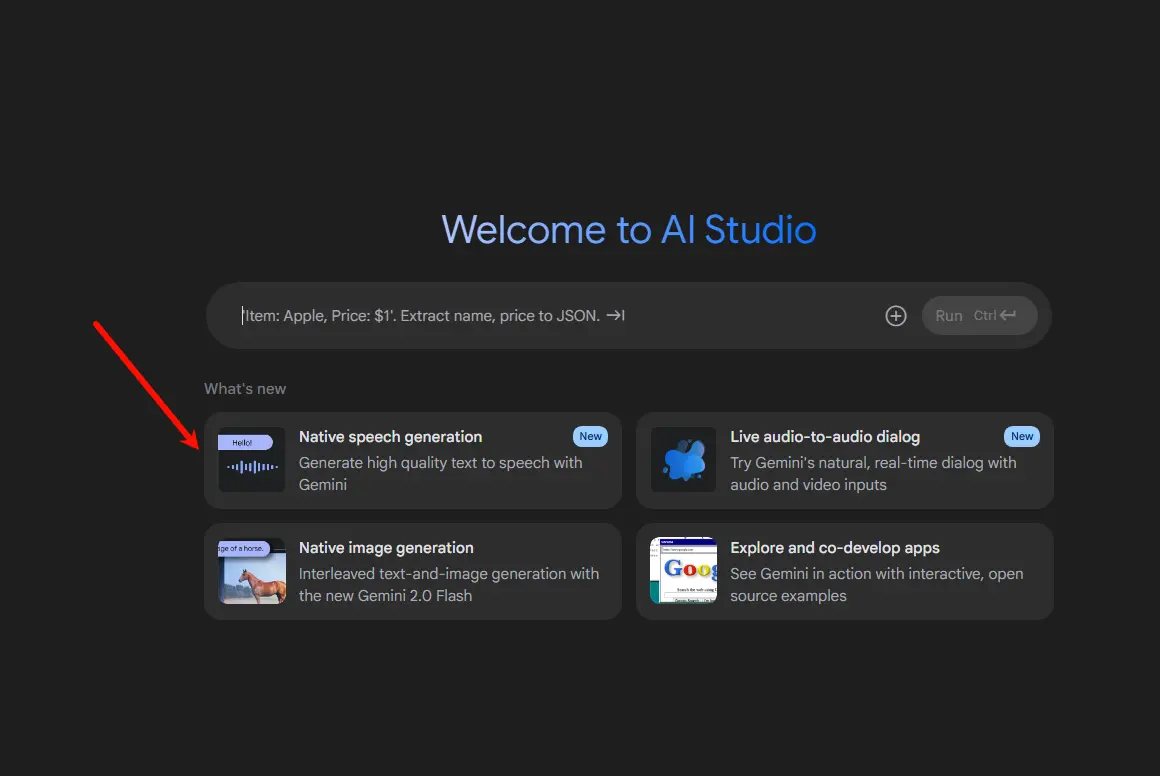
Native Speech Generation:AI语音生成的全新突破
1. 功能亮点
自然语音生成:Native Speech Generation能够将纯文字转换成极为自然的语音内容,无论是语调、节奏还是情感的流露,都大幅超越了以往常见的TTS(文字转语音)系统。这使得生成的语音更加贴近人类的真实语音,提升了用户体验。
多角色对话模式:该功能支持多角色对话模式,适合用于模拟Podcast对谈。用户可以轻松创建多个角色,并为每个角色分配不同的声音和对话内容,无需录音室与配音员,就能呈现高水准的声音体验。
即时语音对语音对话:Native Speech Generation与“Live Audio-to-Audio Dialog(即时语音对语音对话)”功能结合,让开发者或内容创作者能够以即时互动的方式操控语音角色进行对话。这类似于NotebookLM的Audio Overview,但功能更强、应用更自由。
免费使用:这些功能目前可在Google AI Studio中免费使用,无论是开发AI语音机器人、建立教学内容,还是制作娱乐型Podcast,Native Speech Generation都是一个不可忽视的全新利器。
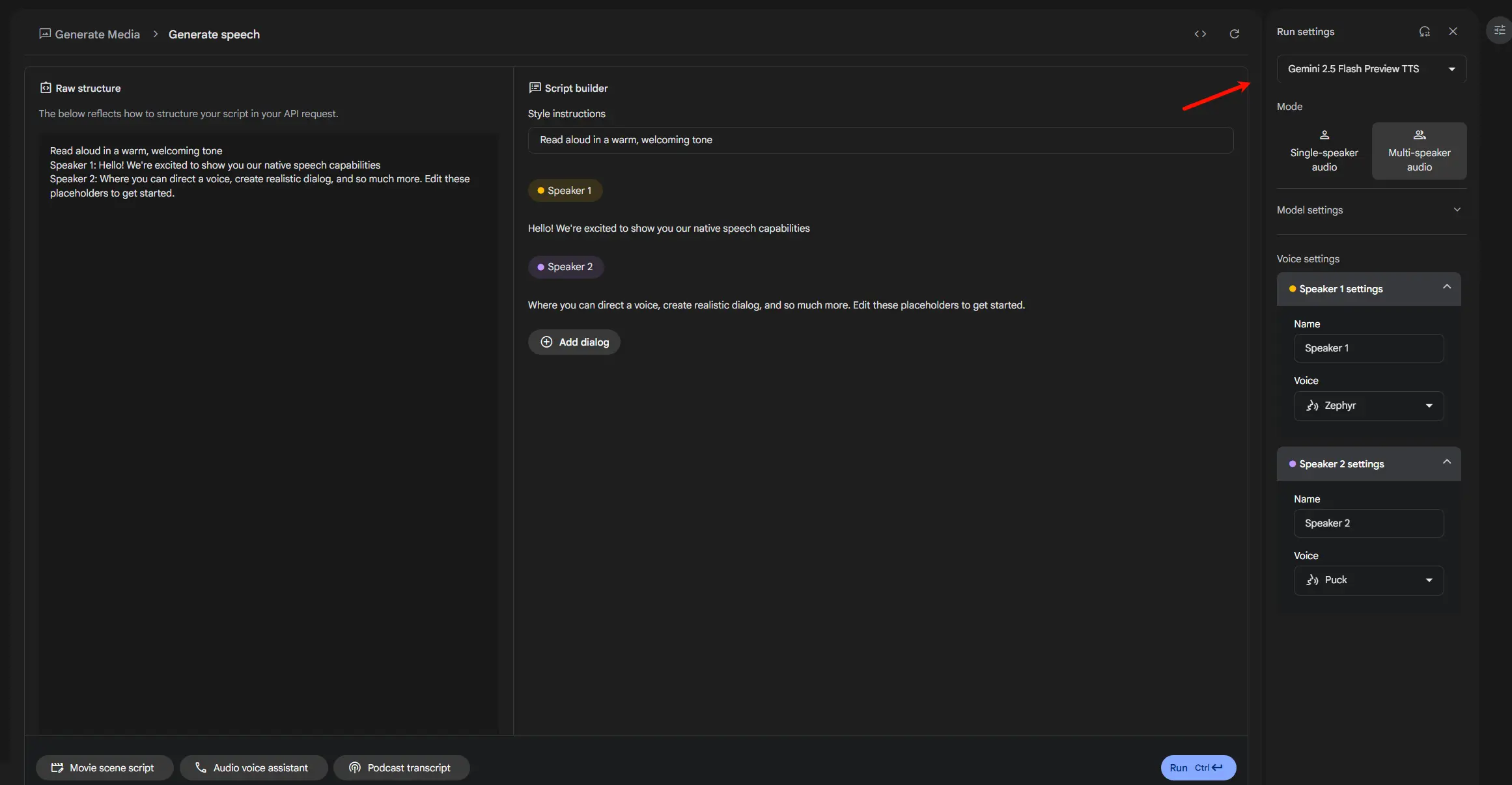
2. 如何使用
访问Google AI Studio:只要你有Google账号,就可以免费体验Native Speech Generation功能。虽然界面目前只有英文,但操作其实很简单。
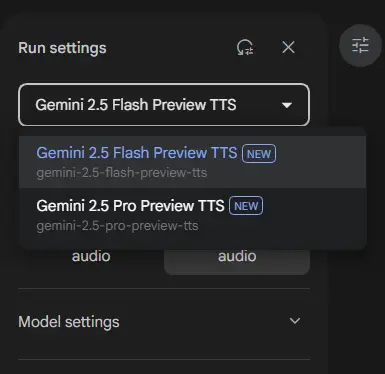
选择模型和模式:
- Model:目前有两个一个选项:Gemini 2.5 Flash Preview TTS和Gemini 2.5 Pro Preview TTS
- Mode:预设是多人对话语音(Multi-speaker audio),如果只需要单一声音,可切换为Single-speaker audio。
设置语音角色:
- Name:可以更换每位讲话者的名称。
- Voice:可以选择声音角色,支持中文。
编辑脚本:
- Script builder:会随右侧栏的选项而变动,每个角色要说的话也可以在这里编辑。
- Raw structure:会随Script builder而变动,也可以直接输入文字内容。
生成语音:
- 单人语音生成:输入文字内容到输入框内,也可以按底部文字内容生成按钮,让AI自行产生文字内容(目前仅支持英文内容)。选择声音角色后,点击“Run”即可生成语音。
- 多人对话:需要自行将内容区分想要对话的角色,可以借助ChatGPT或Gemini来产生。将生成的内容贴回到Google AI Studio,选好对话的角色,再按“Run”来产生、在线播放与下载。
下载语音:生成的语音可以在线播放,也可以点击播放器最右边的直线3点图示按钮,选择“下载”,将生成的语音下载成.wav音档。
未来展望
Native Speech Generation的推出,标志着AI语音生成技术迈入了一个新的时代。它不仅提升了语音生成的自然度,还通过多角色对话模式和即时语音对语音对话功能,为内容创作者提供了更强大的工具。无论是打造多角色Podcast、模拟对话情境,还是制作教学语音内容,Native Speech Generation都能轻松完成,真正做到“输入文字、语音即现”。未来,AI语音生成将不再只是冰冷机械的朗读,而是更贴近人声的互动体验,让创作变得更直觉、更有温度。
如果你对Native Speech Generation感兴趣,可以立即登录Google AI Studio,体验这一全新的语音生成功能,抢占语音内容创作的先机。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











