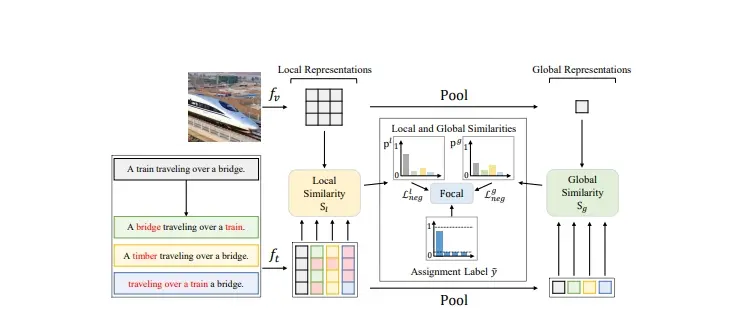
FSC-CLIP:提升预训练视觉和语言模型(VLMs)在理解图像和文字组合任务上的能力,同时保持在多模态任务上的性能韩国科学技术院、世宗大学和汉阳大学的研究人员推出FSC-CLIP,提升预训练视觉和语言模型(VLMs)在理解图像和文字组合任务上的能力,同时保持在多模态任务上的性能。简单来说,就是让计算机能够更好地理...新技术# FSC-CLIP# 多模态2年前05390
Face-Adapter:专为预训练扩散模型设计的高效且有效的适配器,用于实现高精度和高保真的面部编辑来自浙江大学、腾讯、 VIVO和南洋理工大学的研究人员推出Face-Adapter,这是一个专为预训练扩散模型设计的高效且有效的适配器,用于实现高精度和高保真的面部编辑。经过观察,开发人员发现无论是人...新技术# Face-Adapter# 适配器# 面部编辑2年前05390
RankDPO:提高模型在遵循文本提示和视觉质量方面的表现直接偏好优化(DPO)已成为一种强大的方法,用于将文本到图像(T2I)模型与人类反馈对齐。然而,成功应用DPO需要大量的资源来收集和标注大规模数据集,例如数百万张生成的人类偏好注释的配对图像。此外,随...新技术# RankDPO1年前05380
创新框架Generative Photomontage:通过组合多个生成的图像来创建他们所需的图像卡内基梅隆大学和赖希曼大学的研究人员推出创新框架Generative Photomontage,它使用户能够通过组合多个生成的图像来创建他们所需的图像,这个过程就像是用不同的图像拼贴出一幅全新的画面...新技术# Generative Photomontage2年前05380
DragAPart:一张图片和加一系列拖动操作作为输入,生成新图片牛津大学视觉几何小组推出DragAPart,它接收一张图片和一系列拖动操作作为输入,能够生成该物体在新状态下的新图片,且新图片与拖动操作所表达的动作相匹配。与先前主要关注物体重新定位的工作不同,Dra...新技术# DragAPart2年前05350
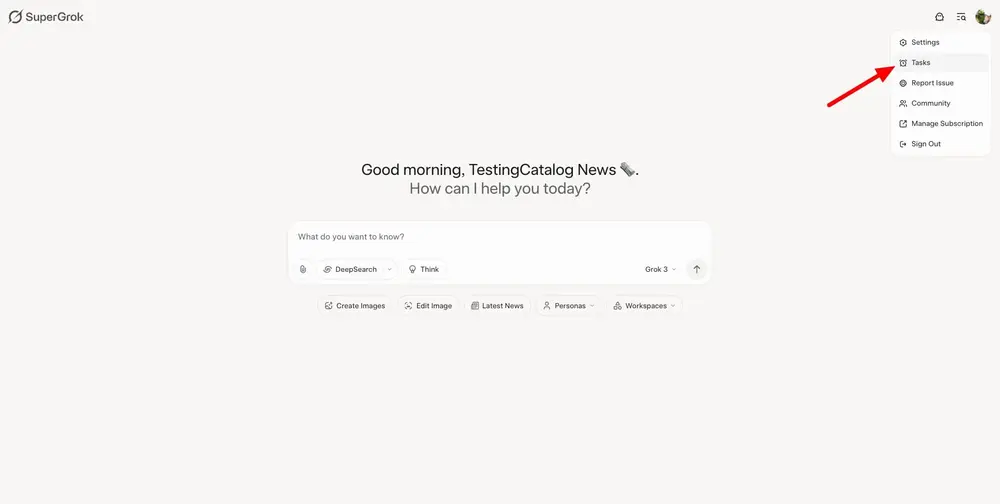
Grok 即将推出“任务(Tasks)”功能,支持自动化定期执行xAI 正在为旗下 AI 模型 Grok 开发一项名为“任务”(Tasks)的新功能。这项功能预计将在 Grok 的下一次模型更新前正式上线,并为用户带来更强大的自动化能力。与 ChatGPT 的自定...早报# Grok# 任务11个月前05340
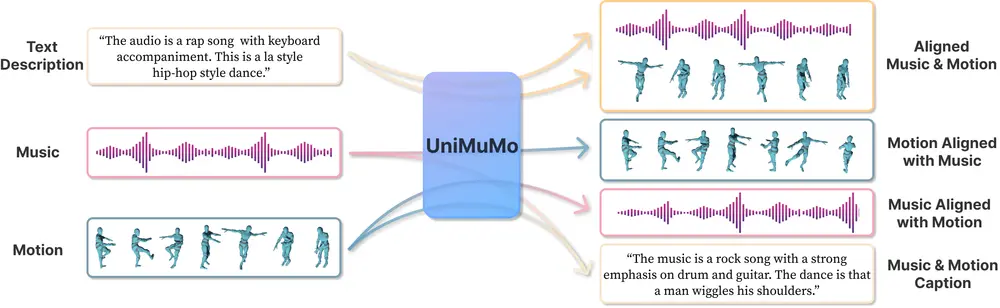
多模态统一模型UniMuMo:能够处理文本、音乐和动作(运动)数据,并在这三种模式之间生成内容香港中文大学、华盛顿大学、不列颠哥伦比亚大学、麻省大学阿默斯特分校、 MIT-IBM Watson AI 实验室和思科研究院的研究人员推出多模态统一模型UniMuMo,它能够处理文本、音乐和动作(运动...新技术# UniMuMo# 多模态统一模型2年前05340
新颖的图生视频方法PhysGen:能够将一张静态图片转换成一段真实感强、物理上可信、时间上连贯的视频伊利诺伊大学香槟分校推出一种新颖的图像到视频生成方法PhysGen,它能够将一张静态图片转换成一段真实感强、物理上可信、时间上连贯的视频。简单来说,就是给定一张图片,比如一个球在斜坡上,PhysGen...新技术# PhysGen# 图生视频2年前05330
微软推出小型语言模型Phi-3系列:可在手机端运行的大模型微软推出小型语言模型Phi-3系列,它在性能上可以与一些大型模型相媲美,如Mixtral 8x7B和GPT-3.5,但大小却足以部署在手机上。这项技术的创新之处在于其训练数据集,这是phi-2数据集的...新技术# Phi-3# 微软2年前05320
视频字幕生成模型Video ReCap:能为长达数小时的视频生成多层次的字幕来自北卡罗来纳大学教堂山分校和 Meta AI的研究人员推出视频字幕生成模型Video ReCap,它能够为长达数小时的视频生成多层次的字幕。 这个模型的设计受到了人类行为层次结构的启发,人类行为通常...新技术# Video ReCap# 视频字幕生成模型2年前05320
开源版风格参考StyleCodes:能够将图像风格表达为一个 20 符号的 base64 代码扩散模型在图像生成方面取得了显著的成功,但如何有效地控制生成图像的风格仍然是一个挑战。虽然使用示例图像可以实现风格控制,但这种方法存在一些不便:示例图像体积较大,不易于分享,且可能涉及隐私问题。为此...新技术# Midjourney# StyleCodes# 风格参考1年前05310
创新人工智能系统Genie:从单一图像提示生成无限种可玩(即可通过行动控制的)游戏场景来自不列颠哥伦比亚大学和Google DeepMind研究人员提出创新人工智能系统Genie,它能够从互联网上的未标记视频数据中学习,生成可交互的虚拟环境。Genie的核心功能是将文本、合成图像、照片...新技术# Genie# Google DeepMind1年前05310