新型文生图模型CountGen:根据文本提示准确地生成指定数量的对象巴伊兰大学、英伟达和特拉维夫大学的研究人员推出新型文生图模型CountGen,它能够根据文本提示准确地生成指定数量的对象。在以往的技术中,尽管文本到图像的扩散模型取得了巨大成功,但它们在控制生成图像中...新技术# CountGen# 文生图模型2年前05300
埃隆·马斯克的Grok推出AI伴侣:可爱哥特风动漫女孩Ani和红色3D卡通狐狸Bad Rudy埃隆·马斯克旗下的 AI 聊天机器人 Grok 迎来了新的功能更新 —— AI 伴侣角色。 这一新功能现已对 Grok 的订阅用户(SuperGrok,每月30美元)开放,首批角色包括: Ani:一位...早报# AI伴侣# Grok9个月前05290
3D场景生成技术Invisible Stitch:生成平滑且连贯的3D场景,通过深度修复来改善场景的几何一致性牛津大学的研究人员推出一种新的3D场景生成技术Invisible Stitch,这项技术的目标是生成平滑且连贯的3D场景,特别是通过深度修复(depth inpainting)来改善场景的几何一致性...新技术# 3D场景生成# Invisible Stitch2年前05280
图像修复模型InstructIR:按照人类指令进行高质量图像修复来自维尔茨堡大学计算机视觉实验室、索尼PlayStation旗下FTG团队的研究人员推出一款图像修复模型InstructIR,它能够根据人类编写的指令来修复和增强图像。简单来说,一张因为雨滴而模糊的招...新技术# InstructIR# 图像修复模型2年前05280
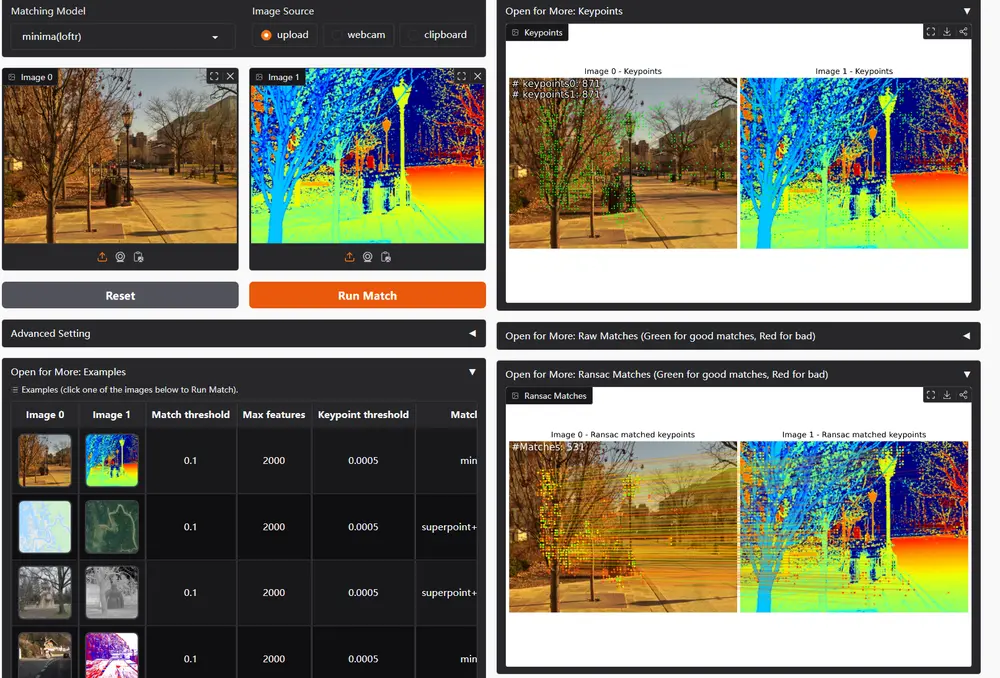
图像匹配框架MINIMA:解决跨视图和跨模态的情况下,多模态感知中的图像匹配问题华中科技大学和武汉大学的研究人员推出一个统一的图像匹配框架MINIMA,即模态不变图像匹配。这项研究旨在解决多模态感知中的图像匹配问题,特别是在跨视图和跨模态的情况下。例如,在自动驾驶中,需要将可见光...新技术# MINIMA# 图像匹配框架1年前05270
一种无需额外训练和条件约束的新方法SEG:利用了自我注意力机制的能量视角来改进图像生成高丽大学的研究人员推出一种无需额外训练和条件约束的新方法SEG(Smoothed Energy Guidance,平滑能量指导),它利用了自我注意力机制的能量视角来改进图像生成。例如,你有一个魔法画笔...新技术# SEG# 平滑能量指导2年前05260
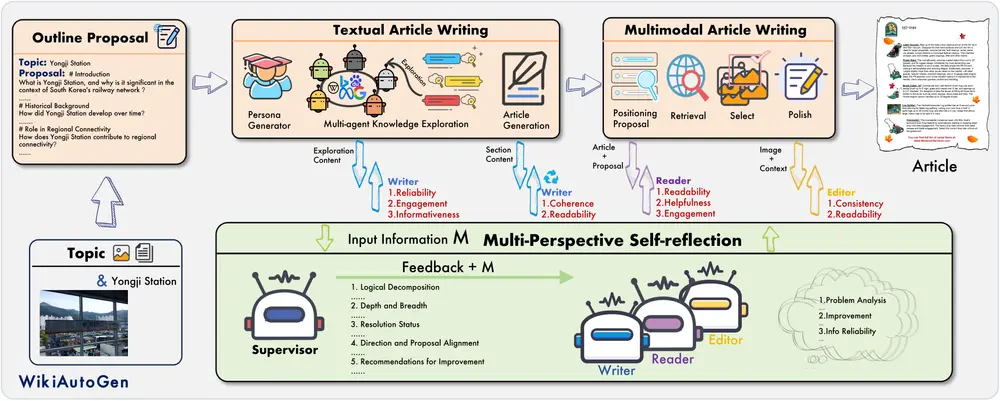
WikiAutoGen:用于自动化生成多模态维基百科风格文章的系统阿卜杜拉国王科技大学、兰州大学、悉尼大学的研究人员推出WikiAutoGen,这是一个用于自动化生成多模态维基百科风格文章的系统。它通过整合文本和图像信息,生成高质量、多模态的维基百科风格文章,同时引...新技术# WikiAutoGen# 多模态# 维基百科1年前05250
新型多模态图像生成系统MUMU:从文本和图像混合提示生成图像来自萨特希尔风险投资公司的研究人员推出新型多模态图像生成系统MUMU,MUMU的核心能力是从文本和图像混合提示(multimodal prompts)生成图像。简单来说,用户可以提供一些文本描述和参考...新技术# MUMU# 多模态图像生成2年前05250
阿里推出高清长视频生成方法EasyAnimate:基于Transformer架构,能够高效地制作出高质量的视频内容阿里推出先进视频生成方法EasyAnimate,它基于Transformer架构,能够高效地制作出高质量的视频内容,目前EasyAnimate已能展现出生成包含144帧视频的能力。例如,你想要制作一段...新技术# EasyAnimate# 长视频生成1年前05250
controllable text-to-3D generation:根据文本提示和条件图像生成高质量、可控制的3D模型来自浙江大学、西湖大学和同济大学的研究团队推出controllable text-to-3D generation,它能够根据文本提示和条件图像生成高质量、可控制的3D模型。这种方法的核心在于使用一种...新技术# 3D模型# controllable text-to-3D generation2年前05250
新型3D生成模型VFusion3D:利用预训练的视频扩散模型来创建可扩展的3D生成模型来自Meta和牛津大学的研究团队推出新型3D生成模型VFusion3D,它利用预训练的视频扩散模型来创建可扩展的3D生成模型。这项技术的核心在于解决3D数据稀缺的问题,因为3D数据不像图片、文本或视频...新技术# 3D生成模型# VFusion3D2年前05250
Gemini 全面升级:你的 AI 助手现在更懂你、更主动、更强谷歌在 Google I/O 上正式宣布了 Gemini 应用的一系列重磅更新 ,从视觉交互、内容创作到深度研究、学习辅助全面升级。现在的 Gemini 不再只是一个被动回答问题的 AI 工具,而是一...早报# Gemini# 谷歌11个月前05230