Follow-Your-Click:通过用户简单的点击和简短的动作提示来实现图像的局部动画化来自香港科大、腾讯浑源和清华大学的团队推出新颖框架Follow-Your-Click,它能够通过用户简单的点击和简短的动作提示来实现图像的局部动画化。 项目主页 GitHub 想象一下,你有一张静态图...新技术# Follow-Your-Click# 局部动画化2年前06740
Gempix现身Whisk!谷歌测试基于Imagen 4的精准图像编辑功能据最新代码线索显示,谷歌正在为其AI图像工具 Whisk 测试一项名为 Gempix 的新功能,该功能可能代表基于 Imagen 4 的新一代图像编辑模型。 这一发现来自 Google Labs 实验...早报# Gempix# Imagen 4# Whisk8个月前06730
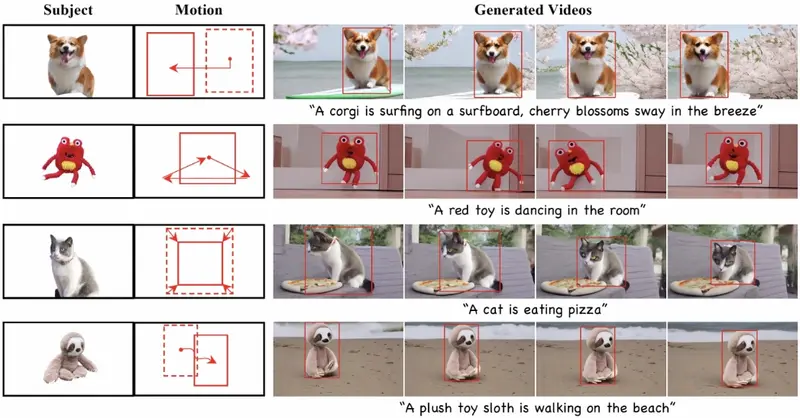
零样本视频定制框架DreamVideo-2:根据单一图像和一系列界定框序列生成具有特定主题和运动轨迹的视频复旦大学、阿里巴巴、南洋理工大学和密歇根州立大学的研究人员推出一个零样本视频定制框架DreamVideo-2,能够根据单一图像和一系列界定框(bounding box)序列生成具有特定主题和运动轨迹的...新技术# DreamVideo-2# 视频定制1年前06730
新型知识蒸馏方法DisBack:加速扩散模型的生成模型的采样速度浙江大学、北京大学和阿里巴巴的研究人员推出新型知识蒸馏方法DisBack,它用于加速一类称为扩散模型(diffusion models)的生成模型的采样速度。扩散模型是当前非常热门的生成模型,能够生成...新技术# DisBack# 蒸馏方法2年前06720
ProCreate:改善基于扩散的图像生成模型的样本多样性和创造性,并防止对训练数据的直接复制纽约大学的研究人员推出创新方法ProCreate,旨在改善基于扩散的图像生成模型的样本多样性和创造性,并防止对训练数据的直接复制。简而言之,ProCreate能够在生成图像的过程中,确保新生成的图像既...新技术# ProCreate2年前06720
3D到3D生成方法ThemeStation:根据少量的示例生成具有一致主题的3D资源来自香港城市大学、上海AI实验室、南洋理工大学的研究团队推出3D到3D生成方法ThemeStation,它是一个能够根据少量的示例(exemplars)生成具有一致主题的3D资源的创新方法。其追求两个...新技术# 3D模型# ThemeStation2年前06720
阿里云正式宣布通义灵码上线 Qwen3-Coder,免费使用不限量阿里云正式宣布,开源其最新一代AI编程大模型——Qwen3-Coder。这是阿里云在代码生成领域迄今最具突破性的成果,标志着国产AI编程能力迈入全球领先行列。 与此同时,阿里云旗下AI编程助手“通义灵...早报# Qwen3-Coder# 通义灵码# 阿里云8个月前06710
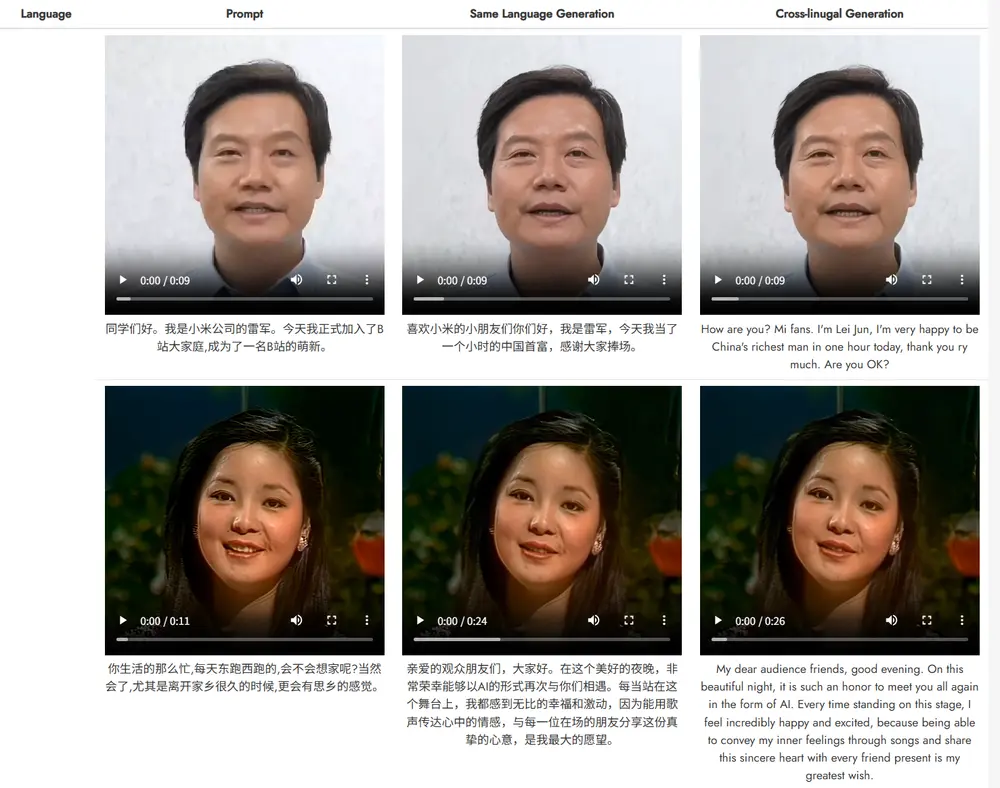
新型实时文本驱动的说话头像生成框架OmniTalker :在零样本场景下同时生成同步的语音和说话头像视频,同时保留语音风格和面部风格阿里通义实验室推出新型实时文本驱动的说话头像生成框架OmniTalker ,能够在零样本(zero-shot)场景下同时生成同步的语音和说话头像视频,同时保留语音风格和面部风格。OmniTalker ...新技术# OmniTalker# 通义实验室1年前06700
阿里巴巴Wanx 团队推出新型多模态生成模型ACE:可以根据文本指令来执行复杂的图像编辑和生成任务阿里巴巴Wanx 团队推出新型多模态生成模型ACE,这个模型的核心功能是处理和生成图像,但它与传统的图像处理工具不同,因为它可以根据文本指令来执行复杂的图像编辑和生成任务。例如,你是一名摄影师,你拍摄...新技术# ACE# 阿里巴巴1年前06700
自回归技术StreamingT2V:能够创建具有丰富运动动力学的长视频,不会出现停滞现象来自Picsart AI研究部门、得克萨斯大学奥斯汀分校、佐治亚理工学院和伊利诺伊大学厄巴纳-香槟分校的研究团队推出先进的自回归技术StreamingT2V,能够创建具有丰富运动动力学的长视频,不会出...新技术# StreamingT2V# 自回归技术2年前06690
Ideogram推出角色一致性功能Ideogram Character,支持跨场景形象统一在数字创作中,角色是叙事的核心。然而,与真人演员不同,AI生成的角色往往难以“保持人设”——同一张脸,在不同场景中可能变成另一个人。缺乏一致性,故事便失去了连贯的锚点。 现在,这个问题有了新的解法。 ...早报# Ideogram# Ideogram Character# 角色一致性8个月前06680
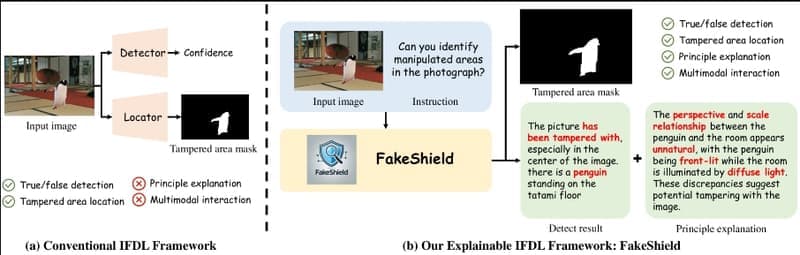
多模态框架FakeShield:通过多模态大语言模型评估图像的真实性,用于检测AI及PS图片生成式AI的快速发展为内容创作带来了巨大便利,但同时也使得图像篡改变得更加容易且难以检测。当前的图像伪造检测和定位(IFDL)方法虽然通常有效,但仍面临两大挑战: 黑箱性质:检测原理未知,难以理解和解...新技术# FakeShield# 多模态框架1年前06680