AI会诱发精神病吗?《柳叶刀》最新研究:聊天机器人或放大易感人群妄想随着人工智能深度融入日常生活,一项发表于《柳叶刀精神病学》(The Lancet Psychiatry)的最新综述研究引发了学界与公众的广泛关注。该研究首次系统性地探讨了AI聊天机器人与“妄想思维”之...科普# 柳叶刀3周前0180
奇安信发布“龙虾安全伴侣”:国内首份 OpenClaw 威胁报告揭示技能爆炸背后的隐忧3月16日,奇安信在北京召开“龙虾安全产品发布会”,直面AI智能体OpenClaw(业内昵称“龙虾”)爆发式增长带来的安全挑战。会上,奇安信发布了国内首份《OpenClaw生态威胁分析报告》,并正式推...早报# 奇安信# 龙虾安全伴侣3周前0110
以 Token 为核心重构 AI 战略!阿里巴巴成立“Alibaba Token Hub”事业群, 悟空事业部首度曝光2026年3月16日,阿里巴巴集团内部发出一封重磅邮件,宣布正式成立 Alibaba Token Hub(简称 ATH)事业群。这一新组织由阿里巴巴 CEO 吴泳铭直接负责,标志着阿里在 AGI(通用...百科# Alibaba Token Hub# 悟空事业部# 阿里巴巴3周前0110
智谱 AI 重磅发布 GLM-5-Turbo:专为 OpenClaw“龙虾”打造的极速智能体引擎在 AI 智能体(Agent)从“对话”走向“执行”的关键时刻,智谱 AI 正式推出了 GLM-5-Turbo —— 一款专为 OpenClaw(俗称“龙虾”)场景深度优化的基座模型。 国内版: 文档...多模态模型早报# GLM-5-Turbo# 智谱 AI3周前01290
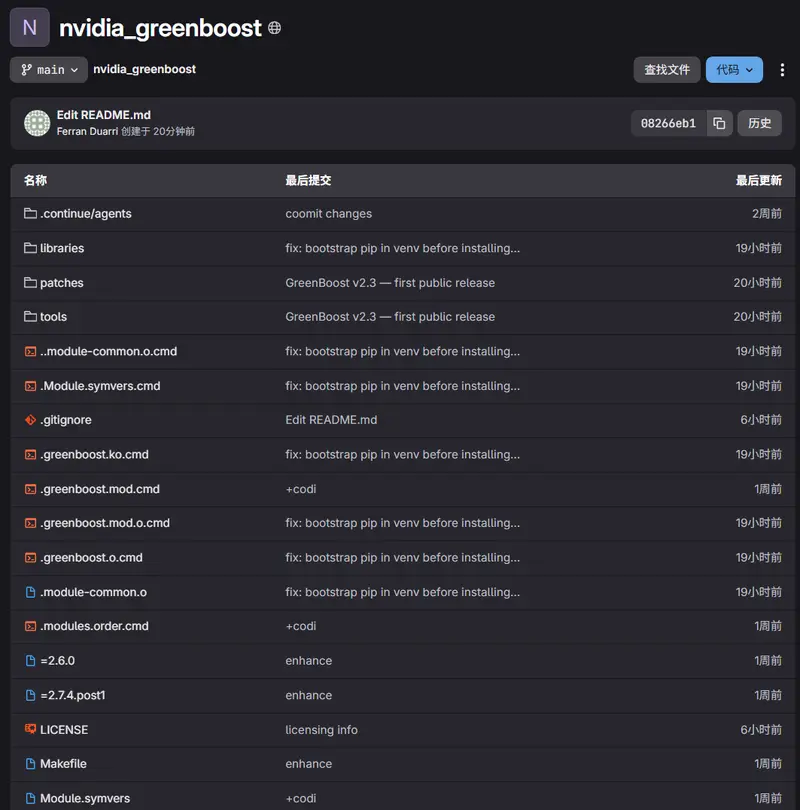
GreenBoost:Linux 下的“显存无限”魔法,让 12GB 显卡跑 32GB 大模型你是否拥有一张消费级显卡(如 RTX 4070/5070 12GB),却眼馋那些需要 24GB 甚至 48GB 显存才能运行的超大语言模型(如 GLM-4-Flash, Llama-3-70B)? 传...新技术# GreenBoost# 大语言模型3周前01900
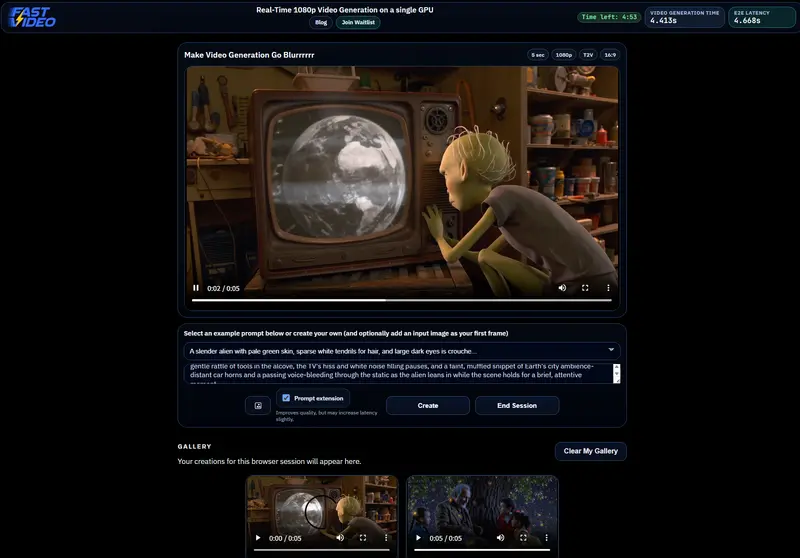
FastVideo 里程碑:单卡 4.5 秒生成 1080p 视频,AI 视频创作进入“实时交互”时代“灵感稍纵即逝,但生成却要等几分钟。” 这是当前 AI 视频创作者最大的痛点。当生成速度慢于构思速度时,创意的反馈循环就被彻底打破了。 FastVideo 团队宣布了一项突破性进展:他们成功将开源模型...新技术# FastVideo# LTX-2.33周前0870
美国撤销争议AI硬件出口规则:取消“对等投资”要求,新规仍在制定美国商务部已正式撤销一项争议性AI硬件出口规则草案,该草案曾要求海外大型AI集群运营商必须投资美国AI基础设施才能采购英伟达、AMD等厂商的高端AI加速器。目前,针对AI硬件的新出口框架仍在制定中。 ...早报# AI硬件# AMD# 美国3周前0220
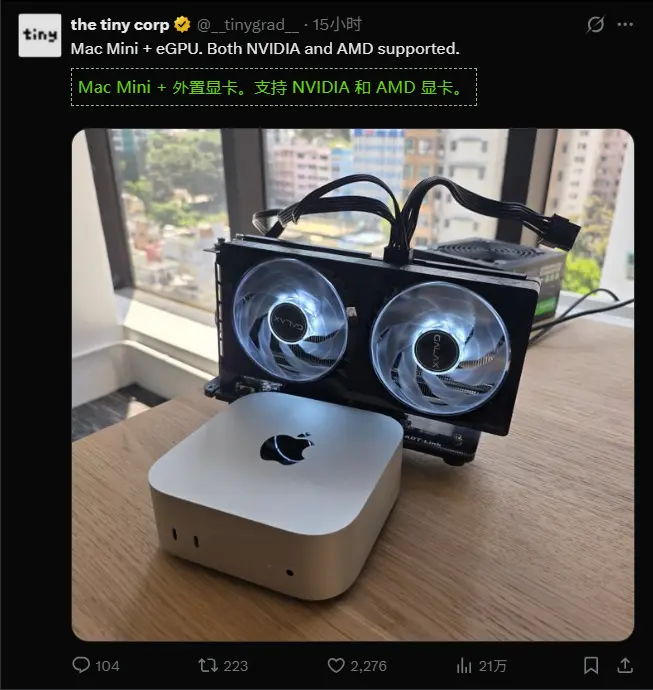
Mac Mini 变身 AI 工作站!TinyCorp 实现外接 NVIDIA/AMD 显卡跑本地大模型在 OpenClaw 热潮推动下,苹果 Mac Mini 成为热门本地 AI 计算设备,而 AI 初创公司 TinyCorp 进一步突破性能上限,成功通过外接显卡方案,将 Mac Mini 打造成更强...硬件# Mac Mini# TinyCorp3周前0530
高管称AI大幅提升生产力,报告实测净增益仅每周16分钟AI被企业高管视为提升效率的核心工具,但Foxit发布的《文档智能状况报告》显示,在扣除审核与校验时间后,AI带来的实际生产力提升远低于预期。 感知与现实巨大差距:净收益仅16分钟 89%的高管认为A...早报# AI3周前0140
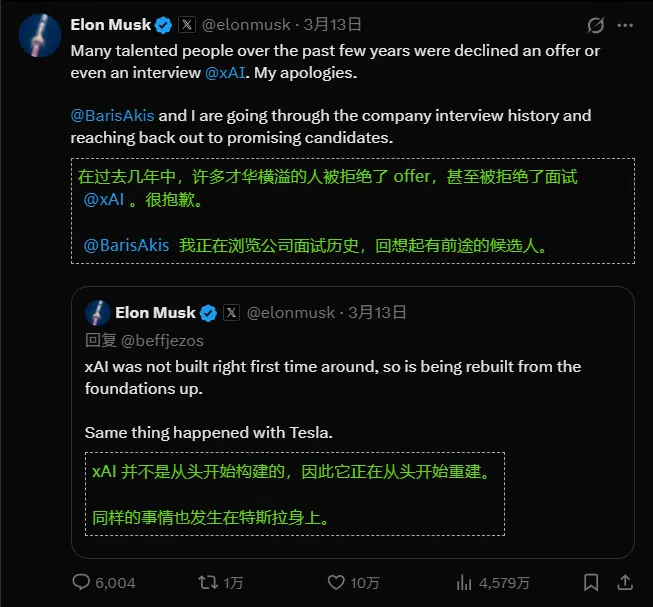
xAI 遭遇“创始团队大清洗”:11 人仅剩 2 人,马斯克空降“整顿者”重塑编程能力埃隆·马斯克(Elon Musk)旗下的 xAI 正经历一场前所未有的内部动荡。据《金融时报》及多方信源报道,因对 Grok 编程产品 的表现极度不满,马斯克启动了严厉的重组计划,导致多位联合创始人被...早报# xAI# 马斯克3周前0170
Chrome 146 原生支持 WebMCP:Agent 操作网页的“去后端化”革命,却陷“鸡生蛋”困局谷歌在 Chrome 146 版本中迈出了关键一步:原生支持 WebMCP (Web Model Context Protocol)。这一更新标志着 AI Agent 与浏览器交互的方式发生了范式转移...教程早报# Chrome# WebMCP3周前02370
AMD 官方完整教程:Windows 本地部署 OpenClaw AI 智能体(双硬件方案)AMD 正式发布了面向 Windows 系统的技术指南,详细介绍了如何在 AMD 硬件平台上通过两条不同路径实现 OpenClaw 的本地化部署,这两条方案分别被命名为 RyzenClaw 和 Rad...教程# AMD# OpenClaw# RadeonClaw3周前02080