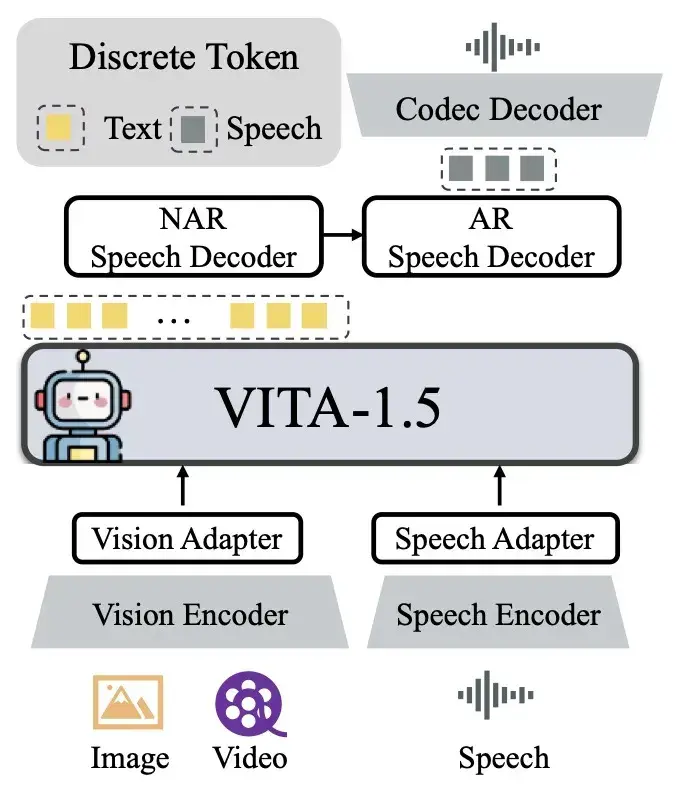
开源多模态视频语音大模型VITA-1.5: 基于Qwen2.5模型,实现接近实时的视觉和语音交互能力随着多模态大语言模型(MLLMs)的发展,如何有效地整合视觉、语言和语音成为了人工智能领域面临的一个重要挑战。VITA-1.5 是由南京大学(NJU)、腾讯优图实验室(Tencent Youtu La...语音模型# Qwen2.5模型# VITA-1.512个月前03360
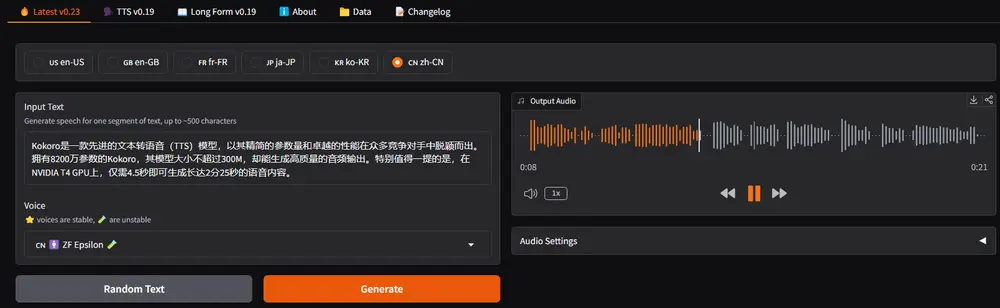
文本转语音模型Kokoro-82M:8200万参数,支持多语言和多声音选项Kokoro是一款先进的文本转语音(TTS)模型,以其精简的参数量和卓越的性能在众多竞争对手中脱颖而出。拥有8200万参数的Kokoro,其模型大小不超过300M,却能生成高质量的音频输出。特别值得一...语音模型# Kokoro-82M# TTS12个月前03,5080
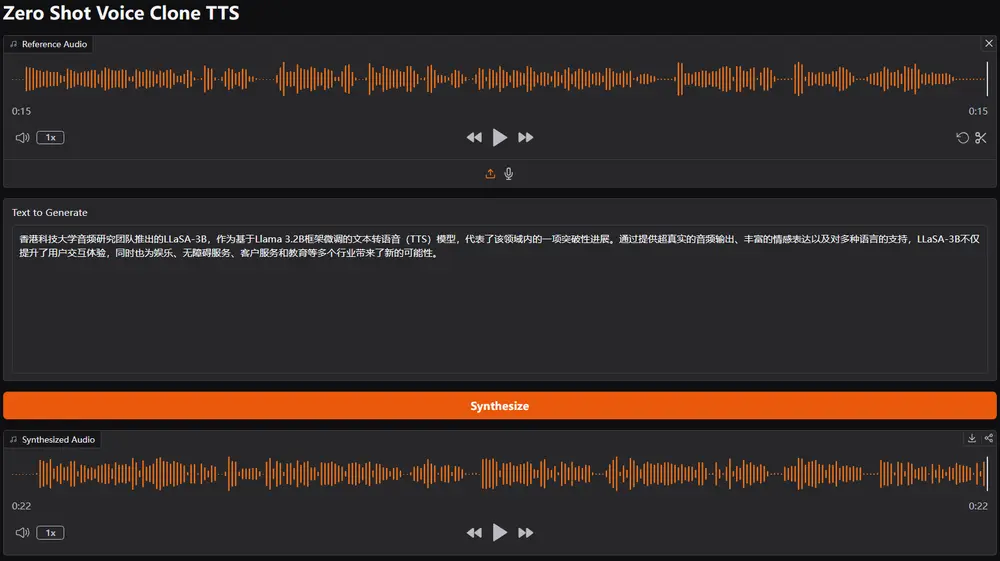
Llasa:基于LLaMA语言模型的先进文本转语音(TTS)系统文本转语音(TTS)技术正成为人机交互领域的重要工具。随着娱乐、无障碍服务、客户服务和教育等行业对语音合成的需求不断增加,市场对逼真、情感丰富且支持多种语言的语音合成技术的需求也在迅速增长。然而,传统...语音模型# Llasa# TTS12个月前06420
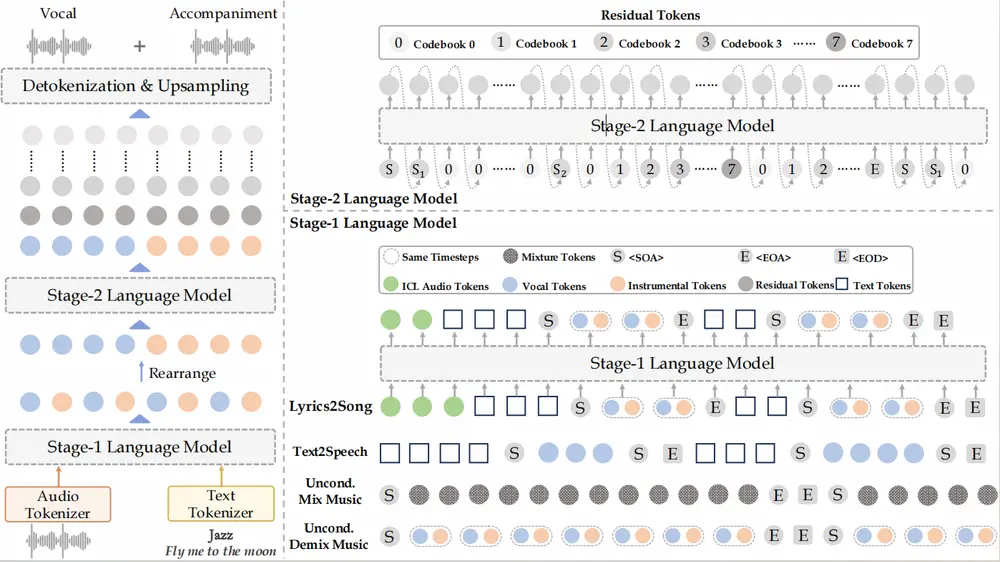
香港科技大学推出歌词生成音乐模型YuE香港科技大学的研究团队近期在探索从给定歌词生成完整歌曲音频的领域取得了重要进展,这一过程被称为“歌词到歌曲”(lyrics2song)。尽管基于文本条件的音乐生成模型在创作非人声音乐短片段方面已经展现...语音模型# AI音乐# YuE12个月前02670