腾讯音乐娱乐推出开源虚拟人视频生成框架MusePose腾讯音乐娱乐旗下天琴实验室推出开源虚拟人视频生成框架MusePose,MusePose 是 Muse 开源系列的最后一个组件,与 MuseV 和 MuseTalk 一起,标志着向构建端到端虚拟人物生成...新技术# MusePose# 虚拟人2年前09890
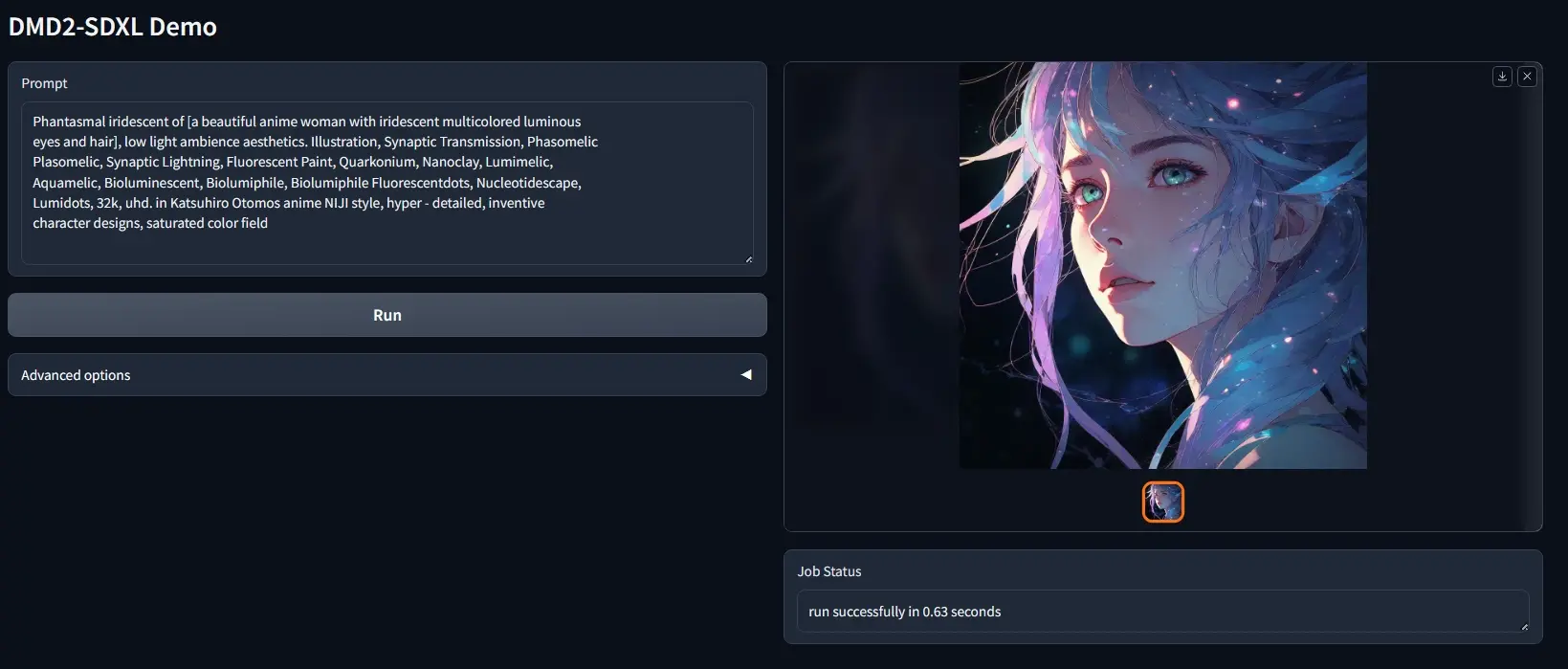
改进图像生成技术DMD2:通过高效的一步生成模型来加速图像生成过程,同时保持或甚至超越原始模型的质量麻省理工学院和 Adobe 研究中心的研究人员推出DMD2(Distribution Matching Distillation的改进版),这是一种改进图像合成技术,特别是针对大语言模型在图像生成...新技术# DMD2# 图像合成2年前09770
新型文本到视频生成框架VideoTetris:专门设计来解决现有方法在处理复杂场景(如多对象或对象数量动态变化的长视频)生成时面临的挑战来自北京大学和快手科技的研究人员推出新型文本到视频生成框架VideoTetris,此框架专门设计来解决现有方法在处理复杂场景(如多对象或对象数量动态变化的长视频)生成时面临的挑战。VideoTetri...新技术# VideoTetris# 北京大学# 快手2年前09730
新型3D生成模型LN3Diff:快速生成高质量的3D对象来自南洋理工大学、北京大学和上海人工智能实验室推出新型3D生成模型LN3Diff,它是一个基于潜在空间的神经辐射场扩散模型,用于快速生成高质量的3D对象。 项目主页 GitHub 想象一下,你有一张2...新技术# 3D生成模型# LN3Diff2年前09720
自级联扩散模型Self-Cascade:快速适应高分辨率的图像和视频生成来自南洋理工大学、腾讯AI实验室、香港科技大学和克莱姆森大学的研究人员提出了一种名为自级联扩散模型(Self-Cascade Diffusion Model)的新方法,该方法利用了低分辨率模型的丰富知...新技术# Self-Cascade# 自级联扩散模型2年前09720
英伟达推出新型大语言模型嵌入模型NV-Embed:专门设计用于提高文本嵌入任务的性能英伟达推出新型大语言模型嵌入模型NV-Embed,NV-Embed专门设计用于提高文本嵌入任务的性能,它在多种文本嵌入任务上的表现开始超越了基于BERT或T5的嵌入模型,包括基于密集向量的检索。NV...新技术# NV-Embed# 嵌入模型2年前09710
自动化图形设计工具PosterLLaVa:利用多模态大语言模型来自动化图形设计中的布局生成任务腾讯推出PosterLLaVa系统,它是一个统一的多模态布局生成器,利用多模态大语言模型(MLLM)来自动化图形设计中的布局生成任务。布局生成是图形设计中非常关键的一环,它需要以一种视觉上令人愉悦且遵...新技术# PosterLLaVa# 多模态布局生成器# 自动化图形设计2年前09670
MVEdit:用于3D对象合成和编辑的通用3D扩散适配器来自斯坦福大学、加州大学圣地亚哥分校和Apparate Labs的研究人员推出MVEdit,这是一个用于3D对象合成和编辑的通用3D扩散适配器。 项目主页 Demo GitHub MVEdit的核心功...新技术# 3D# MVEdit2年前09610
创新框架MotionBooth:生成具有定制主体和可控主体及摄像机运动的动画视频北京大学、南洋理工大学、上海人工智能实验室、浙江大学和上海交通大学的研究人员推出创新框架MotionBooth,它专门用于生成具有定制主体和可控主体及摄像机运动的动画视频。简单来说,MotionBoo...新技术# MotionBooth2年前09590
基于指令的高质量图像编辑数据集HQ-Edit加州大学圣克鲁斯分校的研究人员推出高质量数据集HQ-Edit,它专门用于基于指令的图像编辑任务。例如,你有一张图片,想要根据某些具体的指令来修改它,比如改变背景、调整物体的颜色或者添加一些新元素。HQ...新技术# HQ-Edit# 图像编辑数据集2年前09570
视频插帧新技术ZeroSmooth:提升预训练视频扩散模型生成高帧率视频的能力,而无需额外的训练数据和参数更新中国科学院大学人工智能学院、中国科学院自动化研究所模式识别新实验室和腾讯AI实验室的研究人员推出ZeroSmooth,它能够提升预训练视频扩散模型生成高帧率视频的能力,而无需额外的训练数据和参数更新...新技术# ZeroSmooth# 视频插帧2年前09560
新型文生图风格迁移技术InstantStyle-Plus:在生成图像的同时保留原始图像的内容和风格InstantX团队推出新型文生图风格迁移技术InstantStyle-Plus,在生成图像的同时保留原始图像的内容和风格。这项技术特别适用于需要将一种图像的风格应用到另一种图像上,但又希望保留原始图...新技术# InstantStyle-Plus# 风格迁移2年前09550