开源人像生成器InstantID:只需一张人脸照片,快速生成不同风格的人物照片开源人像生成器InstantID今天在推特引发了热议,InstantID只需要一张人脸照片,就能快速生成多种风格的人物照片,无需复杂的训练或微调过程。InstantID还能与流行的图像扩散模型(如 S...新技术# controlnet# InstantID# LCM2年前09530
不可混合扩散Immiscible Diffusion:加速扩散模型的训练过程加州大学伯克利分校和清华大学的研究人员推出新技术“Immiscible Diffusion(不可混合扩散)”,它旨在加速扩散模型的训练过程。扩散模型是一类在图像生成领域取得显著进展的模型,但它们的训练...新技术# Immiscible Diffusion# 扩散模型2年前09480
StreamMultiDiffusion:实时交互式图像生成和编辑的工具来自韩国首尔国立大学的团队发布新应用StreamMultiDiffusion,这是一种用于实时交互式图像生成和编辑的工具,这是将之前已发布的技术 MultiDiffusion + StreamDiff...新技术# StreamMultiDiffusion# 实时生图2年前09480
新型视频生成框架MovieDreamer:专门用于制作长篇视频内容,比如电影浙江大学和阿里巴巴的研究人员推出新型视频生成框架MovieDreamer,专门用于制作长篇视频内容,比如电影。与传统的短时视频生成技术不同,MovieDreamer能够处理复杂的叙事结构和情节发展,同...新技术# MovieDreamer# 视频生成框架2年前09470
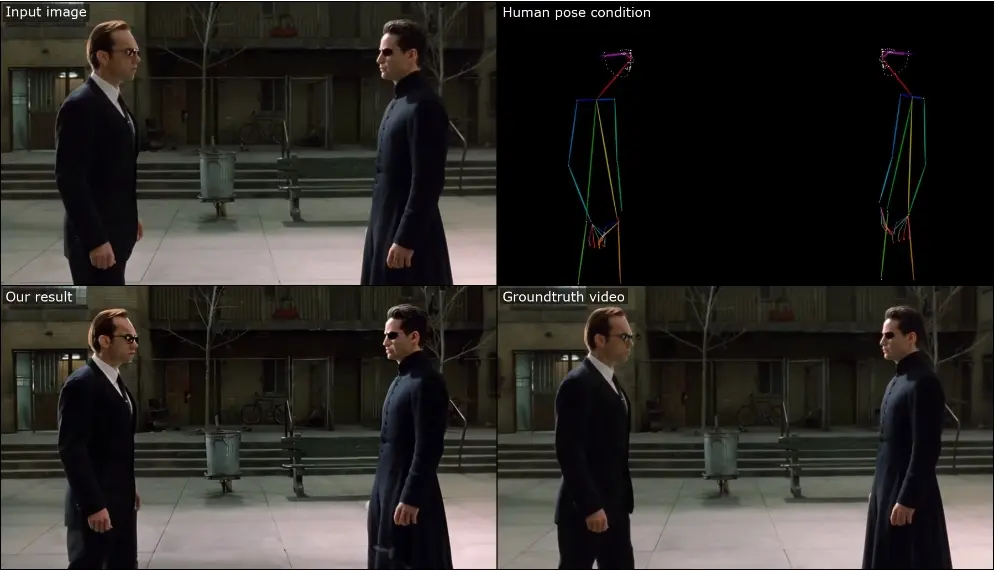
新型可控图像动画方法MOFA-Video:能够根据给定的图像和额外的可控信号(例如人体标记、手动轨迹或提供的其他视频)或它们的组合生成视频来自东京大学和腾讯AI实验室推出新型可控图像动画方法MOFA-Video,能够根据给定的图像和额外的可控信号(例如人体标记、手动轨迹或提供的其他视频)或它们的组合,从给定的图像中生成视频。这与以往的方...新技术# MOFA-Video# 可控图像动画生成2年前09470
零样本多模态高保真3D人体纹理生成模型TexDreamer:快速地从文本或图像中生成高保真3D人体纹理来自上海大学、腾讯优图实验室、上海交通大学和复旦大学的研究团队推出首个零样本多模态高保真3D人体纹理生成模型TexDreamer,采用高效的纹理适应微调策略,将大型T2I(文生图)模型与语义UV结构相...新技术# 3D人体纹理生成模型# TexDreamer2年前09410
分辨率适配器ResAdapte:解决SD模型生成超大图片和非训练分辨率图片时的肢体异常以及画面崩坏问题字节跳动推出ResAdapter,它是一个用于SD模型的分辨率适配器,可以生成任意风格领域的图像,并且能够在不同的分辨率下保持图像的一致性和质量。 项目主页 GitHub 模型地址 简单来说,可以解决...新技术# ResAdapte# SD模型2年前09400
文生图模型GLIGEN:用于将Stable Diffusion模型扩展为可定制模型威斯康星大学麦迪逊分校、哥伦比亚大学和微软的研究人员推出的GLIGEN模型,用于将Stable Diffusion模型扩展为可定制的模型。这个模型的核心目标是让计算机能够根据文本描述生成图像,并且能够...新技术# GLIGEN# Stable Diffusion# 文生图模型2年前09380
3D服装生成框架DressCode:根据文本指导生成具有缝纫图案和基于物理渲染(PBR)纹理的服装上海科技大学、宾夕法尼亚大学、影眸科技和赜深科技推出3D服装生成框架DressCode,它能够根据文本指导生成具有缝纫图案和基于物理渲染(PBR)纹理的服装。这项技术对于数字化人类创建、时尚设计、虚拟...新技术# 3D服装生成# DressCode2年前09370
一维(1D)标记化技术TiTok:用极少的标记(tokens)来表示和生成高分辨率图像字节跳动和慕尼黑工业大学的研究人员推出新型图像表示方法TiTok,它通过一种新颖的一维(1D)标记化技术,用极少的标记(tokens)来表示和生成高分辨率图像。这种方法与传统的二维(2D)图像标记化方...新技术# TiTok# 一维标记化2年前09320
专为人体图像动画设计的大规模高质量数据集HumanVid:结合了精心挑选的真实世界数据和合成数据香港中文大学和上海人工智能实验室的研究人员推出HumanVid,它旨在揭开用于生成逼真人物视频动画的训练数据的神秘面纱。HumanVid是首个为人物图像动画量身定制的大规模、高质量的数据集,它结合了精...新技术# HumanVid2年前09300
新型图像抠图技术Matting by Generation:能够生成更高分辨率和细节丰富的抠像结果东京大学、合肥大学、Snap Research、阳明大学、香港中文大学、台湾大学和日本国立信息研究所的研究人员推出新型图像抠图技术Matting by Generation,图像抠图是指从一幅图片中精...新技术# Matting by Generation# 抠图2年前09230