北京人工智能研究院推出新型图像生成模型OmniGen北京人工智能研究院推出新型图像生成模型OmniGen,与流行的扩散模型(例如,Stable Diffusion)不同,OmniGen不再需要额外的模块,如ControlNet或IP-Adapter来处...新技术# OmniGen# 图像生成模型1年前04530
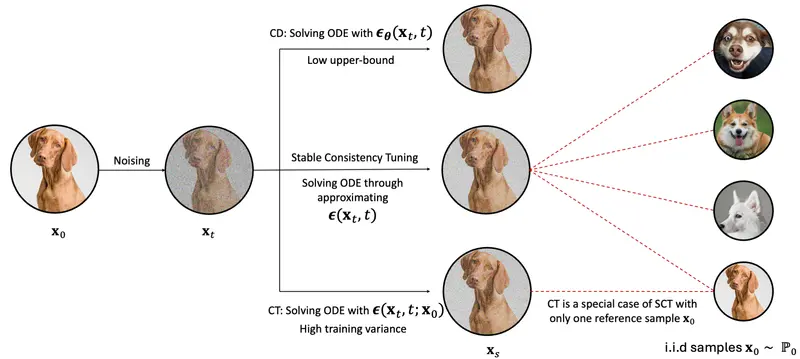
新框架SCT:旨在理解和改进一致性模型香港中文大学和卡内基梅隆大学的研究人员提出了一个名为Stable Consistency Tuning(SCT)的新框架,旨在理解和改进一致性模型(Consistency Models)。一致性模型是...新技术# SCT# 一致性模型1年前04520
新型视频生成技术Dr. Mo:提高视频生成的效率,同时保持或提升视频质量新型视频生成技术Dr. Mo(Diffusion Reuse MOtion),这项技术的核心在于提高视频生成的效率,同时保持或提升视频质量。研究团队的关键发现是,在早期去噪步骤中的粗粒度噪声在连续视频...新技术# Dr. Mo# 视频生成2年前04520
高通AI研究院推出一个为移动设备优化的视频生成模型MobileVD高通AI研究院推出了一个为移动设备优化的视频生成模型Mobile Video Diffusion(MobileVD),该模型的目标是在保持生成视频的质量和控制力的同时,显著降低计算需求,使得在移动设备...新技术# MobileVD# 视频生成模型1年前04500
基于常加速度方程的普通微分方程(ODE)框架CAF:用于学习两个分布之间的映射,特别是在图像生成领域高丽大学和韩国科学技术研究院的研究人员推出新型框架Constant Acceleration Flow(CAF),它是一种基于常加速度方程的普通微分方程(ODE)框架,用于学习两个分布之间的映射,特别...新技术# CAF# 图像生成1年前04490
CoRe:用于文本到图像个性化的上下文正则化文本嵌入学习中山大学和香港理工大学的研究人员推出文本对齐新技术CoRe,它用于提升文本到图像个性化生成的效果。简单来说,CoRe技术可以帮助人工智能系统更好地理解用户通过文本提供的概念,并生成与这些概念和文本描述...新技术# CoRe2年前04490
CAMI2V:引入物理约束提升文生视频模型中的相机控制精度浙江大学计算机科学与技术学院的研究团队推出一个名为CAMI2V(Camera-Controlled Image-to-Video Diffusion Model)的模型,它是一个基于扩散模型的图像到视...新技术# CAMI2V# 文生视频# 相机控制1年前04460
基于“幅度感知”的新型缓存机制MagCache:用于加速图像和视频扩散模型的生成过程近年来,视频扩散模型在生成高质量视频方面取得了显著进展,但其计算成本高、推理速度慢的问题始终是落地的一大障碍。 为了解决这一难题,来自北京大学和华为的研究人员在最新论文中提出了 MagCache ...新技术# MagCache# 幅度感知# 模型加速9个月前04440
Meta推出个性化图像生成模型Imagine yourself:根据参考照片,生成遵循特定文字描述的新图像,而且不需要对每个新用户进行单独调整Meta旗下GenAI团队推出个性化图像生成模型Imagine yourself,与传统的基于调整的个性化技术不同,Imagine yourself作为一个无需调整的模型运行,使得所有用户都能利用共享...新技术# Imagine yourself# Meta2年前04440
新型图像到视频生成技术OSV:可以将单张图像仅仅一步内生成高质量视频复旦大学、香港科技大学、香港中文大学和腾讯优图实验室的研究人员推出新型图像到视频生成技术OSV,可以将单张图像转换成视频。这项技术的目标是能够快速生成高质量的视频内容,而不需要复杂的多步骤处理。例如...新技术# OSV2年前04440
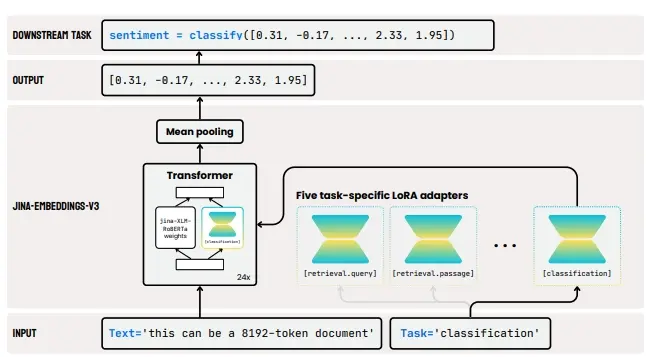
Jina AI推出新型文本嵌入模型 jina-embeddings-v3:专为多语言数据和长文本检索任务优化Jina AI推出文本嵌入模型 jina-embeddings-v3,这是一个具有 5.7 亿参数的新型文本嵌入模型,它在多语言数据和长上下文检索任务上实现了最先进的性能,支持的最大上下文长度达到 8...新技术# jina-embeddings-v3# 文本嵌入模型2年前04440
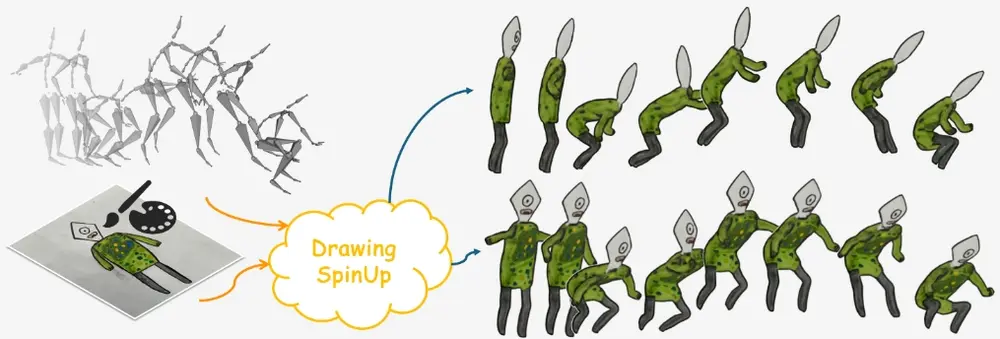
DrawingSpinUp:将单一的平面角色绘画转换成三维动画,同时保留了原始艺术作品的风格和特征香港城市大学的研究人员推出创新系统DrawingSpinUp,它能够将单一的平面角色绘画转换成三维动画,同时保留了原始艺术作品的风格和特征。这就像是给一张静态的画注入生命,让它动起来,比如让一个纸上的...新技术# DrawingSpinUp2年前04440