文生视频模型VSTAR:解决现有开源T2V模型难以生成内容动态变化和较长视频的问题来自博世人工智能中心、曼海姆大学、马克斯·普朗克信息学研究所和图宾根大学的研究团队推出VSTAR,这是一种用于生成动态视频的文本到视频(T2V)合成技术。VSTAR的目标是解决现有开源T2V模型难以生...新技术# VSTAR# 文生视频模型2年前08230
BroadWay:提升文生视频模型的质量,而且不需要额外的训练上海交通大学、中国科学技术大学、香港中文大学和上海人工智能实验室的研究人员推出为BroadWay,它能够提升文生视频模型的质量,而且不需要额外的训练。这就像是给视频生成模型安装了一个“涡轮增压器”,让...新技术# BroadWay# 文生视频模型1年前07810
Search_T2V:改善文本到视频合成的质量和真实感浙江大学、飞步科技、宁波港和腾讯数据平台的研究人员推出新技术Search_T2V,旨在改善文本到视频(Text-to-Video, T2V)合成的质量和真实感。该技术通过搜索现有的视频资源作为运动先验...新技术# Search_T2V# 文生视频模型2年前06890
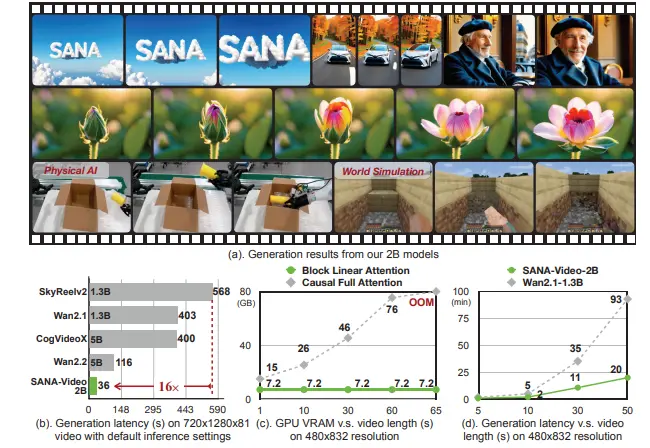
线性注意力 + 恒定内存 KV 缓存!SANA-Video:高效生成分钟级高清视频的新一代文生视频模型在文本到视频(T2V)生成领域,高分辨率、长时长与低延迟三者往往难以兼得。现有大模型虽能生成高质量视频,但动辄数千秒的推理时间与高昂的训练成本严重限制了其落地应用。 为此,由英伟达、香港大学、麻省理工...视频模型# SANA-Video# 文生视频模型6个月前06740
DiT架构的文生视频模型xGen-VideoSyn-1:根据文本描述生成逼真的视频场景Salesforce推出新的文生视频模型xGen-VideoSyn-1,这个模型能够根据文本描述生成逼真的视频场景,它的设计灵感来源于OpenAI的Sora模型,并在此基础上进行了改进和创新。例如,你...新技术# xGen-VideoSyn# 文生视频模型2年前06580
CameraCtrl:为文生视频模型提供精确的摄像机控制能力来自香港中文大学、上海人工智能实验室和斯坦福大学的研究人员推出CameraCtrl,它能够为文本到视频(Text-to-Video, T2V)生成模型提供精确的摄像机控制能力。在视频创作中,摄像机的移...新技术# CameraCtrl# 文生视频模型2年前05790
LIFT:利用人类反馈进行文生视频模型对齐的新型微调方法文本到视频(T2V)生成模型近年来取得了显著进展,能够生成高质量的合成视频。然而,这些模型在将合成视频与人类偏好(例如,准确反映文本描述)对齐方面仍然存在不足。复旦大学、上海人工智能科学院和阿德莱德大...视频模型# LIFT# 微调# 文生视频模型1年前03610
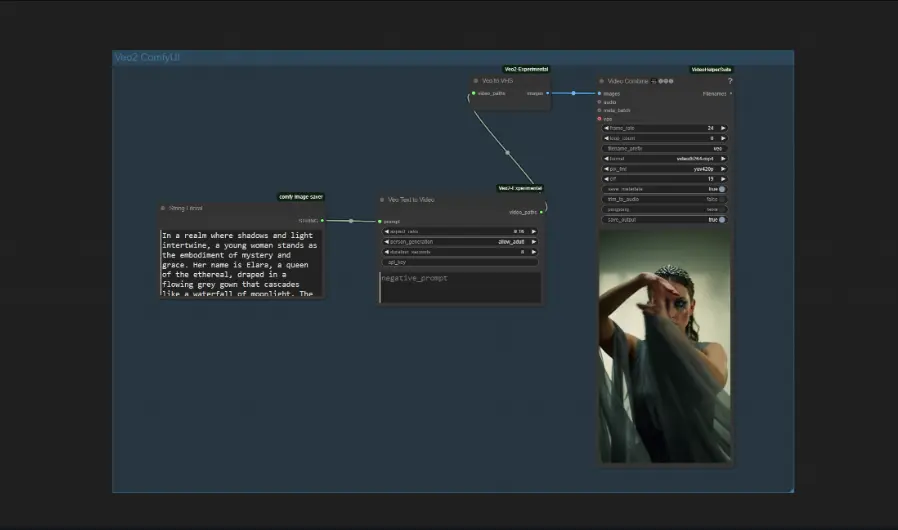
ComfyUI-Veo2-Experimental:将谷歌文生视频模型Veo 2集成到ComfyUI中ComfyUI-Veo2-Experimental是一个为ComfyUI设计的自定义节点,它将谷歌Veo 2强大的文生视频功能集成到ComfyUI中,为创作者提供了一个高效且富有创意的工具。 GitH...插件# ComfyUI-Veo2-Experimental# Veo 2# 文生视频模型12个月前03480
Wan-Alpha:支持透明通道的高质量文生视频模型在视频编辑、虚拟合成、游戏特效和社交媒体创作中,带有透明背景(Alpha 通道)的视频素材具有不可替代的价值——它们可以无缝叠加到任意场景中,无需后期抠像或遮罩处理。 然而,当前主流的文生视频(Tex...视频模型# Wan-Alpha# 文生视频模型6个月前03090
阶跃星辰开源300 亿参数文生视频模型Step-Video-T2V:能够生成长达 204 帧的高质量视频由前微软全球副总裁、微软亚洲互联网工程院首席科学家姜大昕创办的AI公司阶跃星辰,开源了一款强大的文生视频模型——Step-Video-T2V。该模型拥有 300 亿参数,能够生成长达 204 帧的高质...视频模型# Step-Video-T2V# Step-Video-T2V-Turbo# 文生视频模型1年前03020