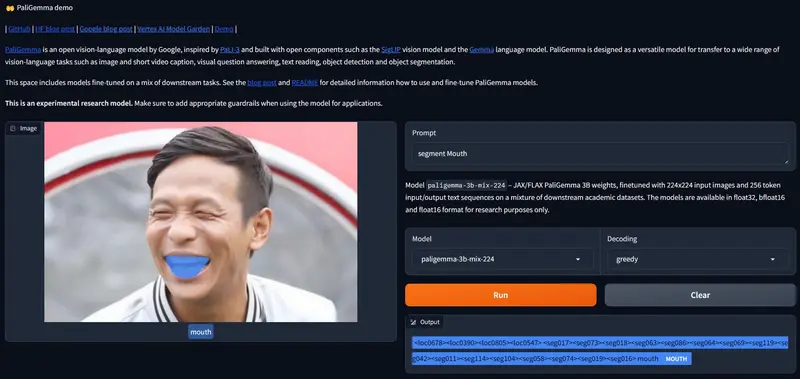
设计灵感来源于PaLI-3!谷歌推出开源视觉语言模型PaliGemmaPaliGemma 是谷歌推出的新一代视觉语言模型家族,其设计灵感来源于PaLI-3,能够接收图像与文本输入并生成文本输出。PaliGemma建立在包括SigLIP视觉模型和Gemma语言模型在内的开...多模态模型# PaliGemma# 谷歌1年前06590
谷歌推出贪婪生长方法(Greedy Growing):用来训练大规模、高分辨率的基于像素的图像扩散模型谷歌发布论文讨论了一个非常有趣的话题:如何通过一种称为“贪婪生长”(Greedy Growing)的方法来训练大规模、高分辨率的基于像素的图像扩散模型,且无需级联超分辨率组件。简单来说,就是科学家们找...新技术# Greedy Growing# 谷歌# 贪婪生长2年前06350
谷歌推出CamViG:控制视频生成过程中的相机视角,从而生成具有精确相机运动的视频Google Research推出CamViG(Camera Aware Image-to-Video Generation),它能够根据单一图像和三维相机运动信号生成视频。这项技术的核心在于,它能够...新技术# CamViG# 相机运动# 谷歌2年前07380
新型图像匹配技术OmniGlue:首个以泛化为核心设计原则的可学习图像匹配器德克萨斯大学奥斯汀分校和谷歌的研究人员推出新型图像匹配技术OmniGlue,这是首个以泛化为核心设计原则的可学习图像匹配器。OmniGlue利用来自视觉基础模型的广泛知识来指导特征匹配过程,从而增强了...新技术# OmniGlue# 谷歌2年前07200
谷歌推出新框架ImageInWords(IIW):创建准确且细节丰富的图像描述,以提高视觉-语言模型的训练效果Google Research、Google DeepMind和华盛顿大学的研究团队推出新框架ImageInWords(IIW),此框架旨在创建准确且细节丰富的图像描述,以提高视觉-语言模型(VLMs...新技术# IIW# ImageInWords# 数据集2年前07010
谷歌推出基于问答的自动评估指标Gecko,用于评估文生图模型的性能谷歌推出基于问答的自动评估指标Gecko2K,用于评估文生图模型的性能。文生图模型生成的图像并不总是能够完全符合文本中的所有细节。因此,评估这些模型生成的图像与文本描述的匹配程度是一个重要的研究问题...新技术# Gecko# Gecko2K# 自动评估2年前06680
图像逆向技术ReNoise:可能图像内容进行编辑重建来自特拉维夫大学和谷歌的研究团队推出图像逆向技术ReNoise,这是一种通过迭代噪声处理来实现真实图像在预训练扩散模型域内重建的方法。简单来说,就像我们有时候需要从一张已经损坏或者风格化的照片恢复出原...新技术# ReNoise# 图像编辑# 谷歌2年前05580
图像编辑技术Prompt-to-Prompt:通过提示词进行局部或全局编辑来自谷歌和特拉维夫大学的团队推出图像编辑技术Prompt-to-Prompt,这是一种直观的从提示到提示的编辑框架,其中编辑操作仅通过文本进行控制。此团队深入分析了文本条件模型,并观察到交叉注意力层在...新技术# Prompt-to-Prompt# 图像编辑# 提示词2年前06380
谷歌推出创新框架VLOGGER:只需要提供一张静态照片和一段语音,就能生成口型匹配的视频谷歌推出创新框架VLOGGER,它能够根据一段音频和一张人物的单张照片生成这个人说话和动作的逼真视频。想象一下,你只需提供一张你的照片和你的语音记录,VLOGGER就能制作出一个视频,在视频中你可以看...新技术# VLOGGER# 谷歌2年前05720
谷歌发布“多步一致性模型”(Multistep Consistency Models)谷歌发布新型生成模型“多步一致性模型”(Multistep Consistency Models),它在图像、视频和音频生成领域具有潜在的应用价值。这个模型是介于传统的“一致性模型”(Consiste...新技术# 多步一致性模型# 谷歌2年前05660
谷歌推出新一代开源模型Gemma,轻量级高性能,助力AI创新谷歌推出开源模型Gemma,这是一款轻量级、先进的开源模型,供开发者和研究人员用于AI构建。Gemma模型家族包括Gemma 2B和Gemma 7B两种尺寸,能够在不同的设备类型上运行,包括笔记本电脑...大语言模型# Gemma# 大语言模型# 谷歌1年前07290
视频编码器VideoPrism:能够处理多种视频理解任务,如分类、定位、检索、字幕生成和问答来自谷歌的研究人员推出视频编码器VideoPrism,它是一个通用的视频理解模型,能够处理多种视频理解任务,如分类、定位、检索、字幕生成和问答(QA)。VideoPrism通过在一个单一的冻结模型上进...新技术# VideoPrism# 视频编码器# 谷歌9个月前07030