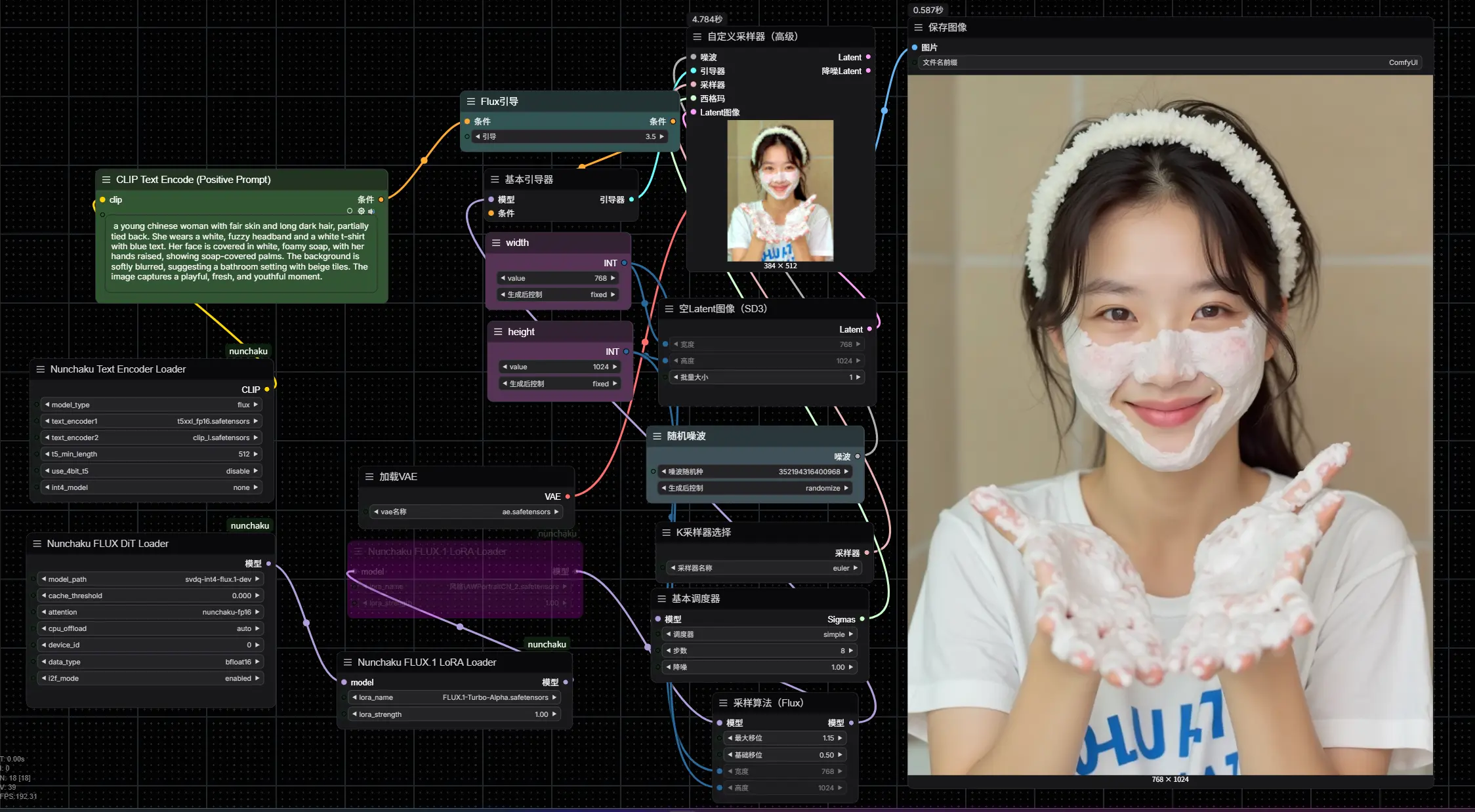
秒速出图!Nunchaku无损加速Flux生图,支持多LoRA和ControlNet几个月前,我们曾介绍过 SVDQuant 技术 和其在 ComfyUI 中的应用。然而,由于当时写的不够详细,许多用户在尝试安装和运行相关插件时遇到了困难。如今,官方已经将 Nunchaku 的 Co...工作流# ComfyUI-nunchaku# FLUX# Nunchaku10个月前01,8370
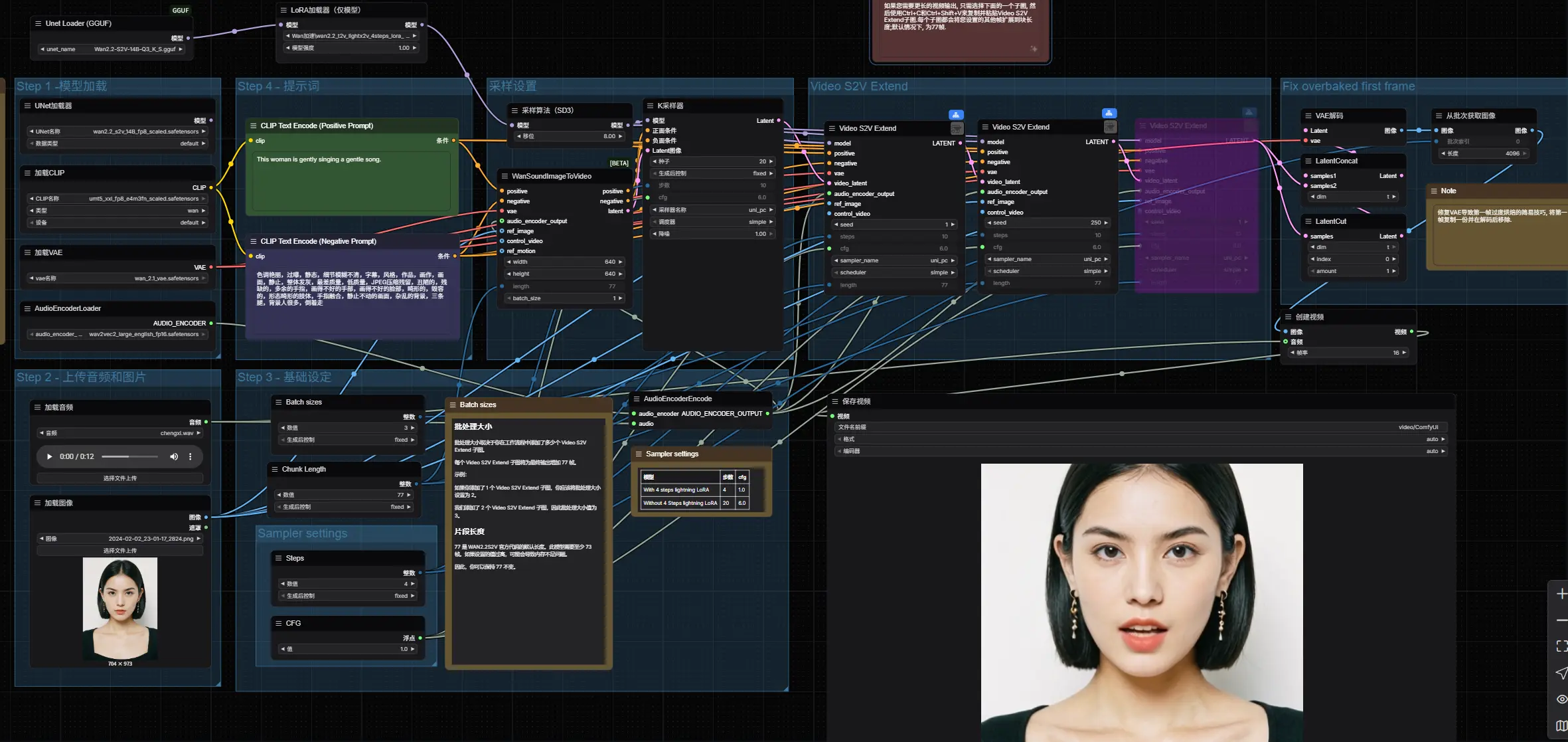
用语音激活静态图像!ComfyUI 原生适配 Wan2.2-S2V,一键生成口型同步视频ComfyUI官方宣布,高性能音频驱动视频生成模型Wan2.2-S2V已实现原生适配——无需额外插件,即可直接在ComfyUI中调用该模型,将静态图片与音频结合,生成对话、唱歌、角色表演等动态视频内容...工作流# ComfyUI# Wan2.2-S2V# 口型同步视频7个月前01,7380
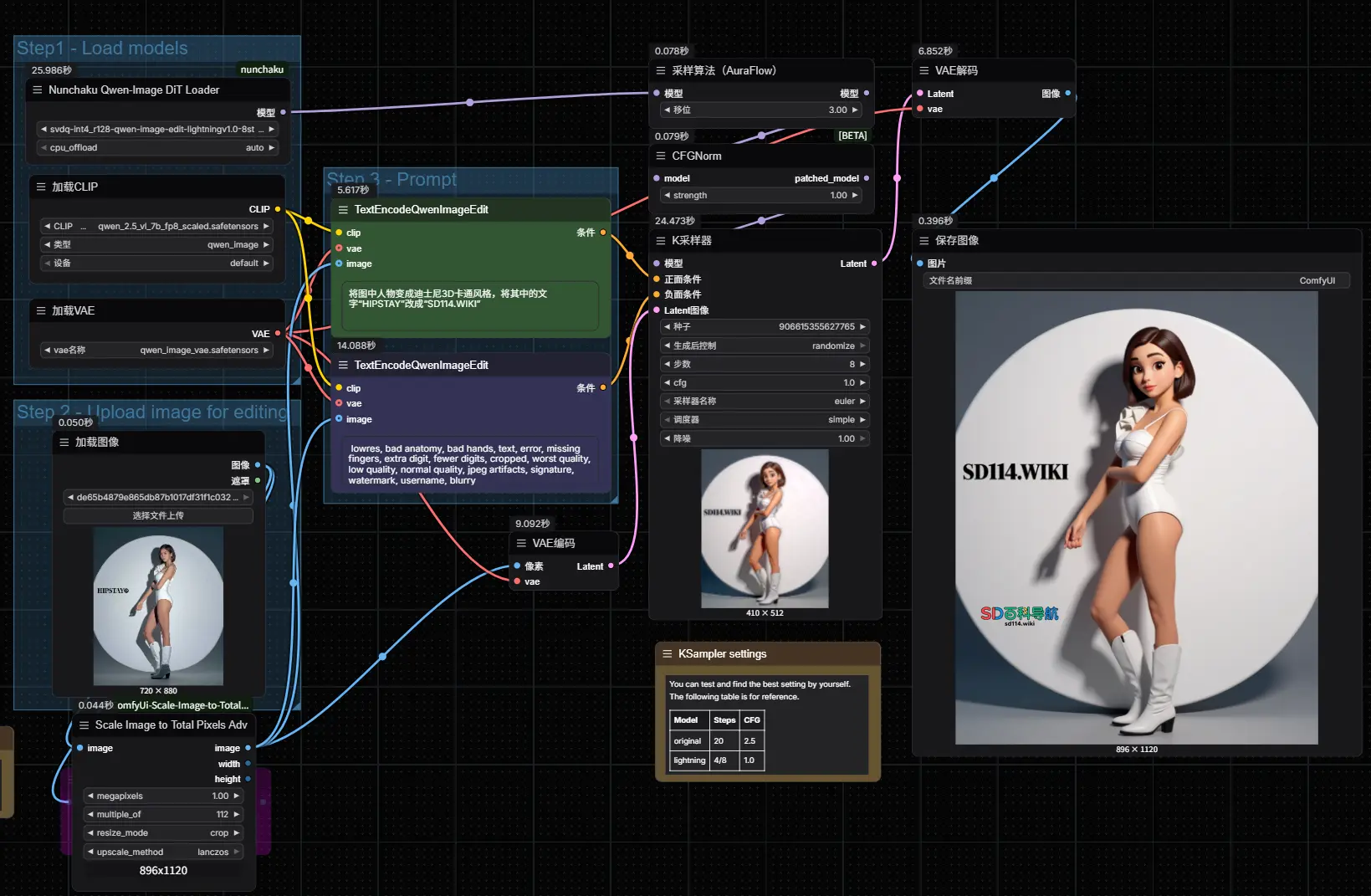
Nunchaku 正式发布 1.0:让 Qwen-Image 与 Qwen-Image-Edit 模型在低显存设备上跑起来9月4日,Nunchaku 团队正式发布 v1.0.0 版本,标志着这一面向 4 位量化神经网络(SVDQuant) 的高性能推理引擎进入稳定可用阶段。 GitHub:https://github.c...工作流# Nunchaku# Nunchaku v1.0.0# Qwen-Image6个月前01,7310
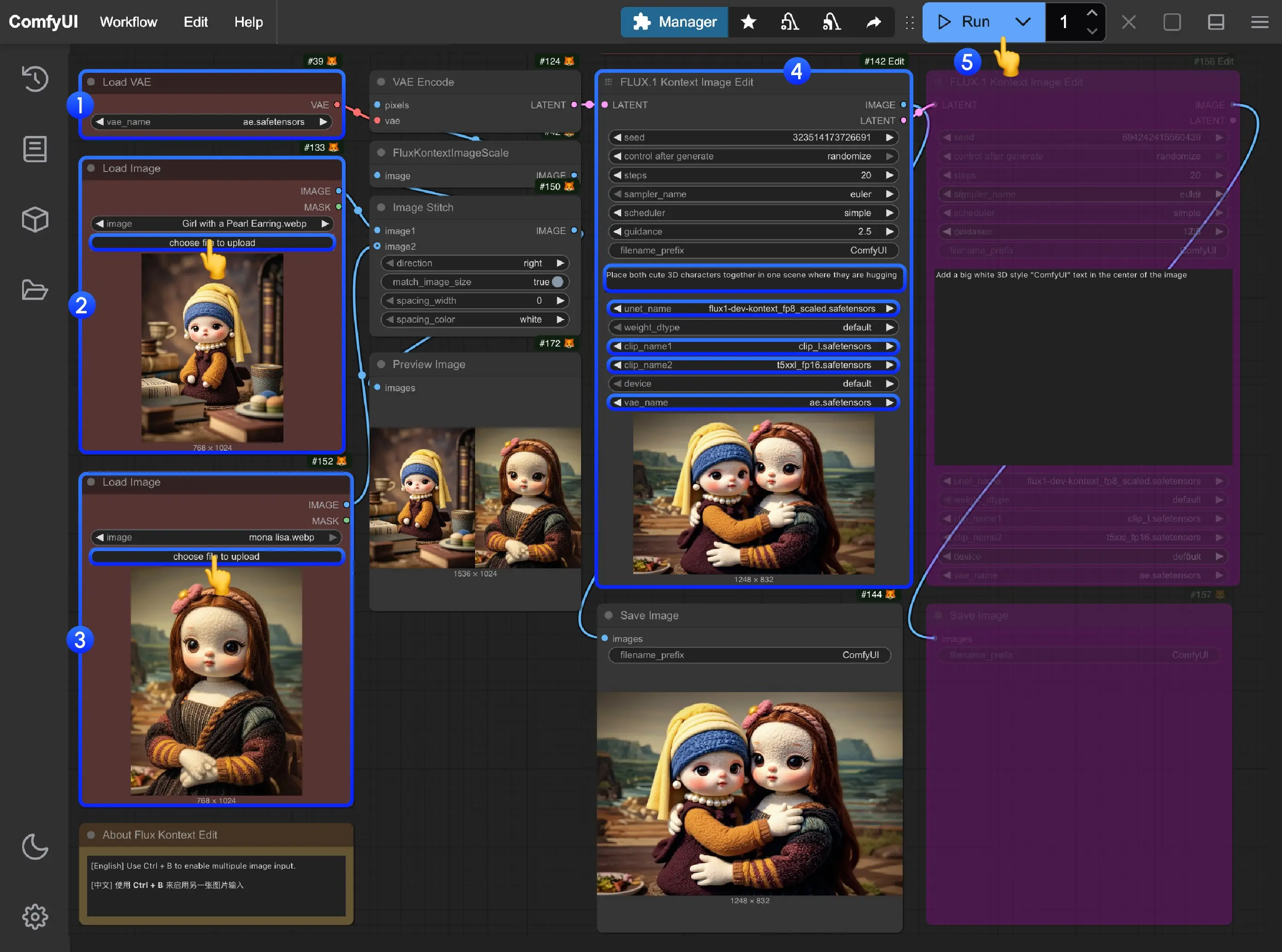
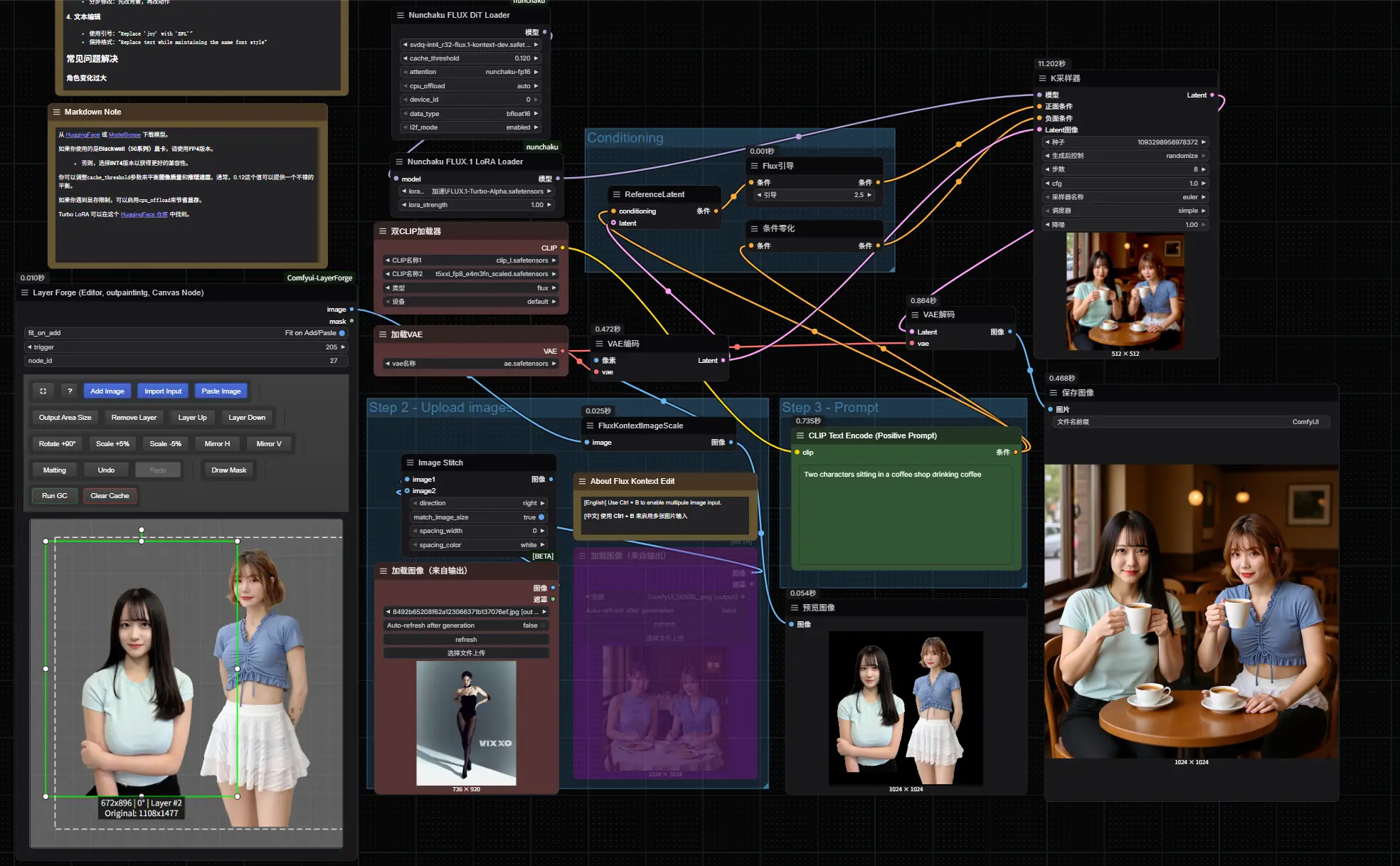
ComfyUI 中使用 FLUX.1 Kontext Dev 进行图像编辑的原生工作流指南FLUX.1 Kontext Dev 是由 Black Forest Labs(黑森林实验室) 推出的一款开源多模态图像编辑模型,具备强大的上下文理解能力,支持通过文本指令对现有图像进行智能修改。该模...工作流# ComfyUI# FLUX.1 Kontext [dev]9个月前21,7270
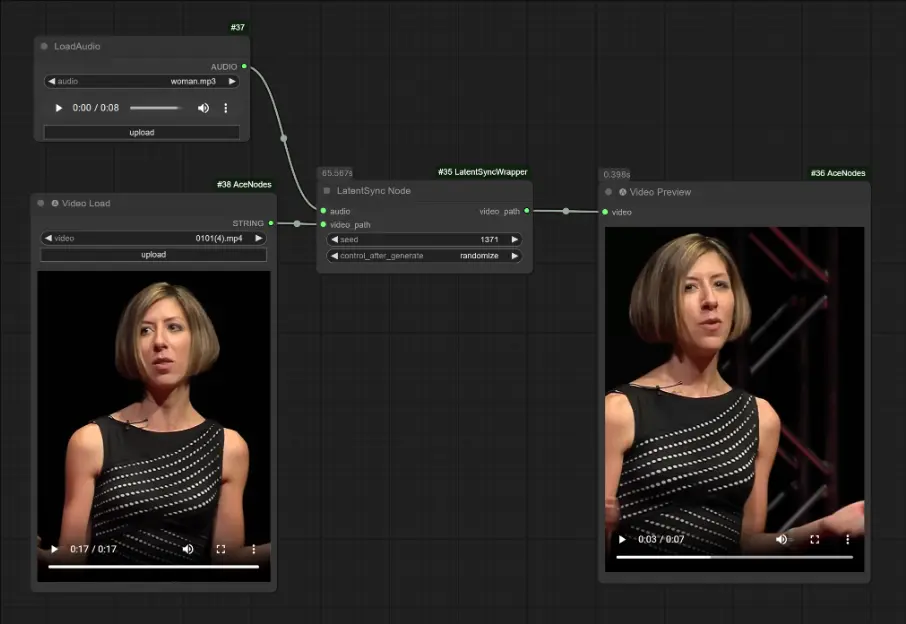
ComfyUI-LatentSyncWrapper:基于字节跳动唇音同步框架LatentSync的非官方ComfyUI节点ComfyUI-LatentSyncWrapper是专门为ComfyUI设计的非官方节点,基于字节跳动的LatentSync框架,实现视频中嘴唇动作与音频输入的同步。借助这一工具,用户可以在Comfy...插件# LatentSync# LatentSync 1.5# 唇音同步1年前01,6840
如何申请及使用Stable Diffusion 3 APIStability AI在经历了人员变动后,其最新基于MMDiT架构的Stable Diffusion 3是否开源就成了大家关心的话题,官方一直向外界传递消息会开源,但从公布Stable Diffus...新闻# ComfyUI# SD3# Stable Diffusion 3 API2年前01,6230
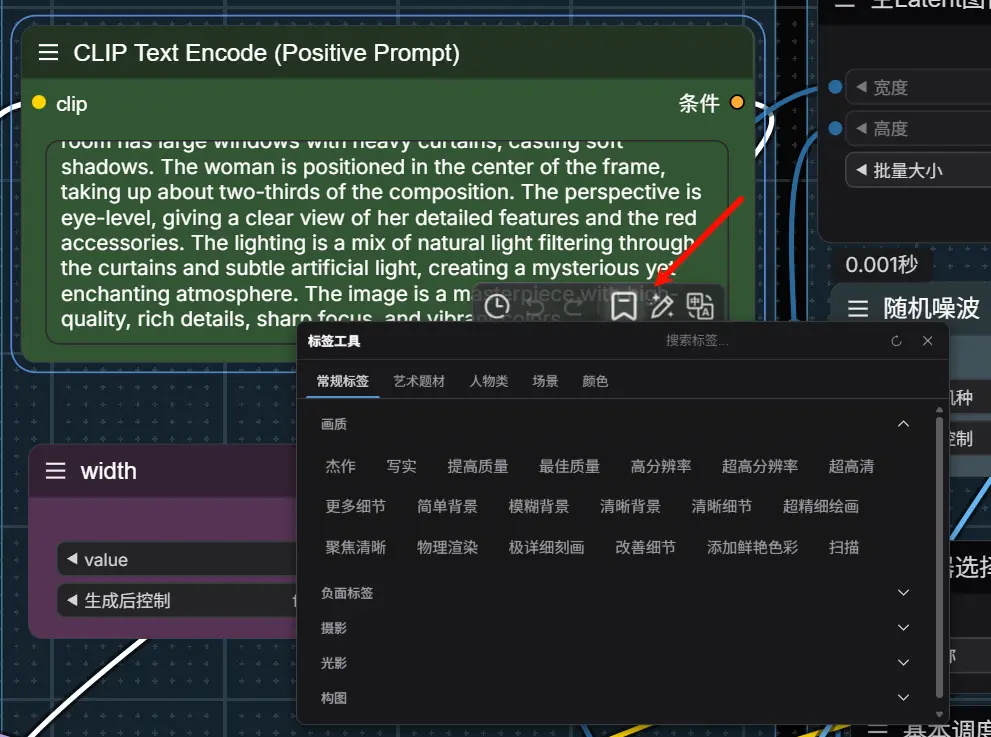
ComfyUI Prompt Assistant(提示词小助手):支持提示词翻译、扩写、预设标签插入、图片反推提示词、历史记录等功能的ComfyUI 插件 ComfyUI Prompt Assistant(提示词小助手)是一个无需添加节点即可使用的 ComfyUI 插件,专为提升图像生成效率设计。支持提示词翻译、扩写、预设标签插入、图片反推提示词、历史...插件# ComfyUI Prompt Assistant# ComfyUI 插件# 提示词小助手9个月前01,6070
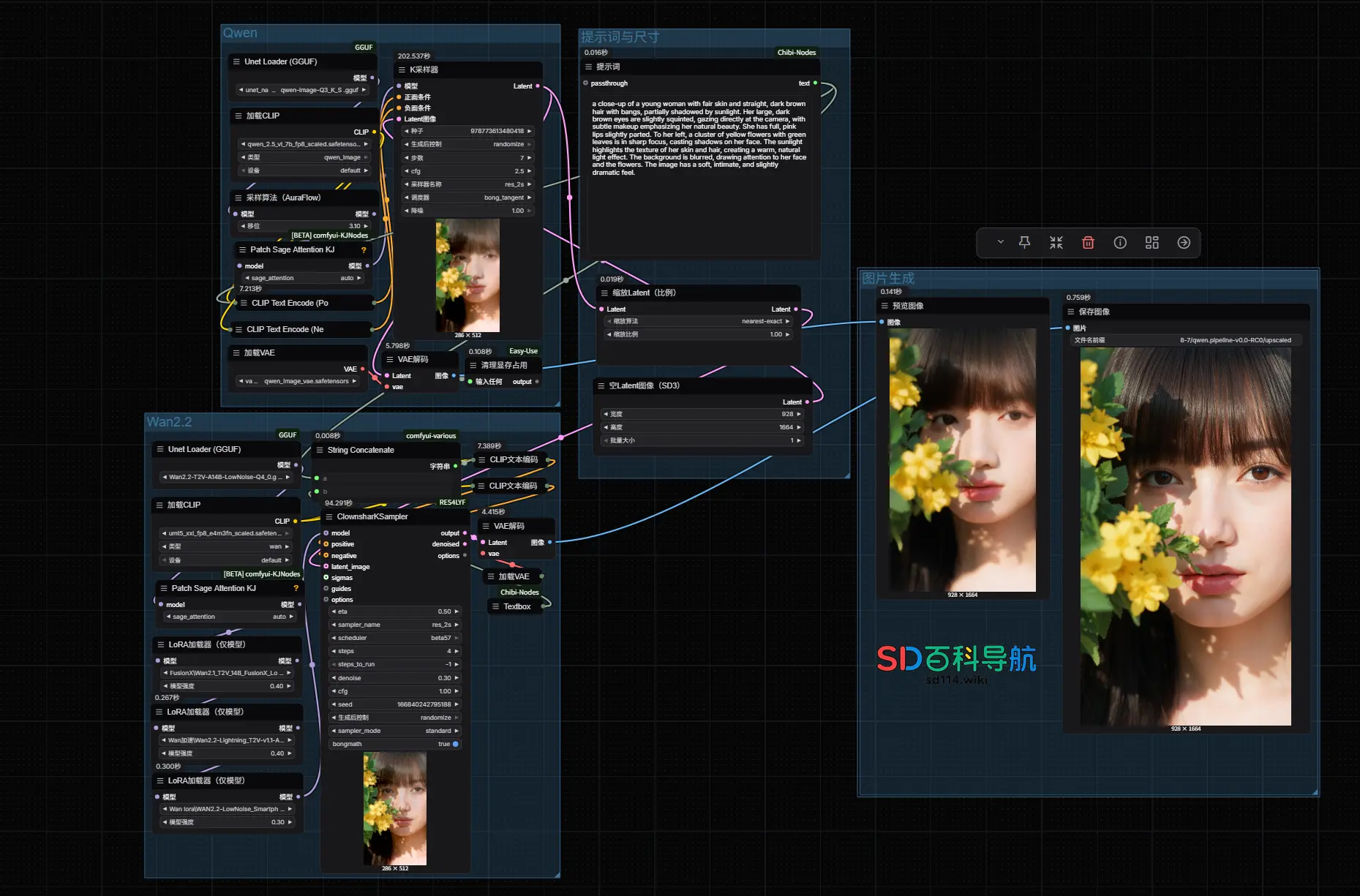
如何兼顾“创意”与“真实”?用 Qwen-Image + Wan 2.2 实现高质量图像生成阿里Qwen项目组近期发布的两款模型Qwen-Image和Wan 2.2都具有图像生成功能,但两款模型在生成图片的时候具有局限性: Qwen-Image 擅长创意构图,想象力丰富,但人物细节 AI 感...工作流# Qwen-Image# WAN 2.2# 图像生成7个月前01,5700
Nunchaku正式支持FLUX.1 Kontext Dev:低显存用户的福音在6月26日,黑森林实验室(Black Forest Labs)发布了其图像编辑模型FLUX.1 Kontext开源版本 FLUX.1 Kontext [dev]。尽管这一模型在图像编辑质量上表现优异...工作流# FLUX.1 Kontext [dev]# Nunchaku# nunchaku-flux.1-kontext-dev9个月前01,4570
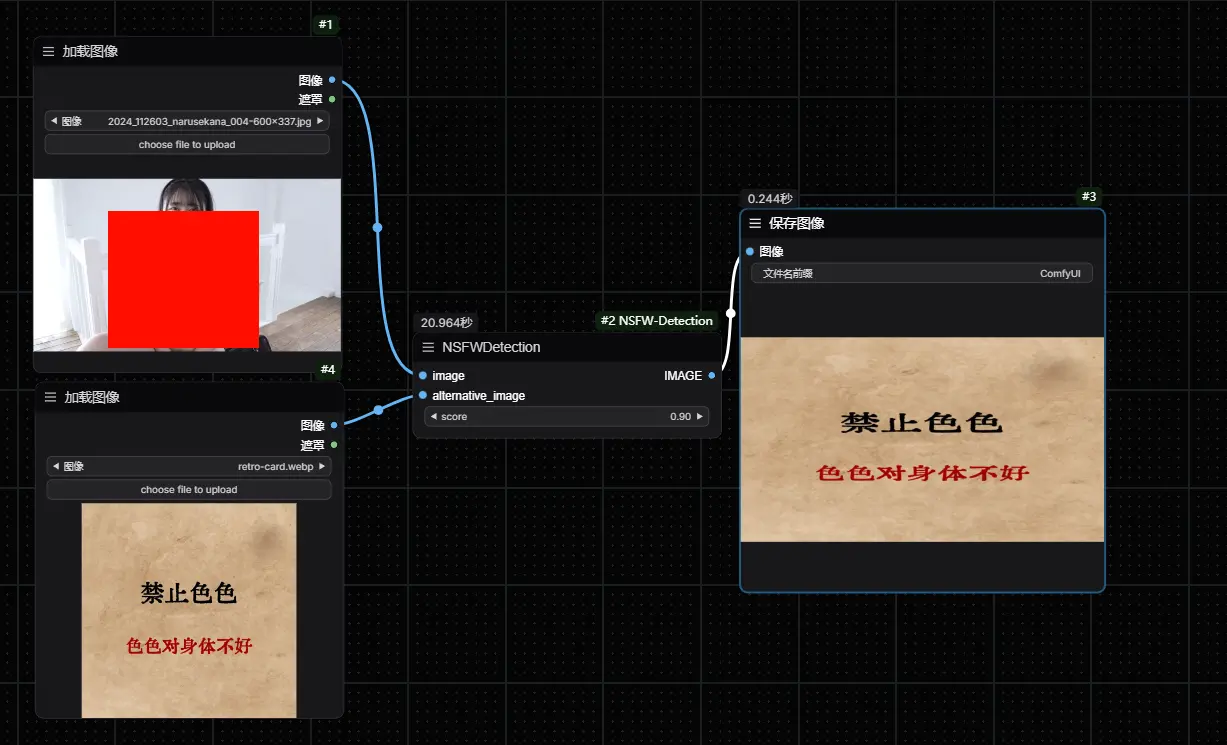
NSFW 检测插件:确保所有生成的内容都是适宜公开分享的NSFW Check for ComfyUI 是一款专为 ComfyUI 用户设计的插件,旨在检测由 ComfyUI 生成的内容是否包含不适合工作场所展示的元素(NSFW,色情)。该插件利用先进的机器...插件# NSFW检测1年前01,4380
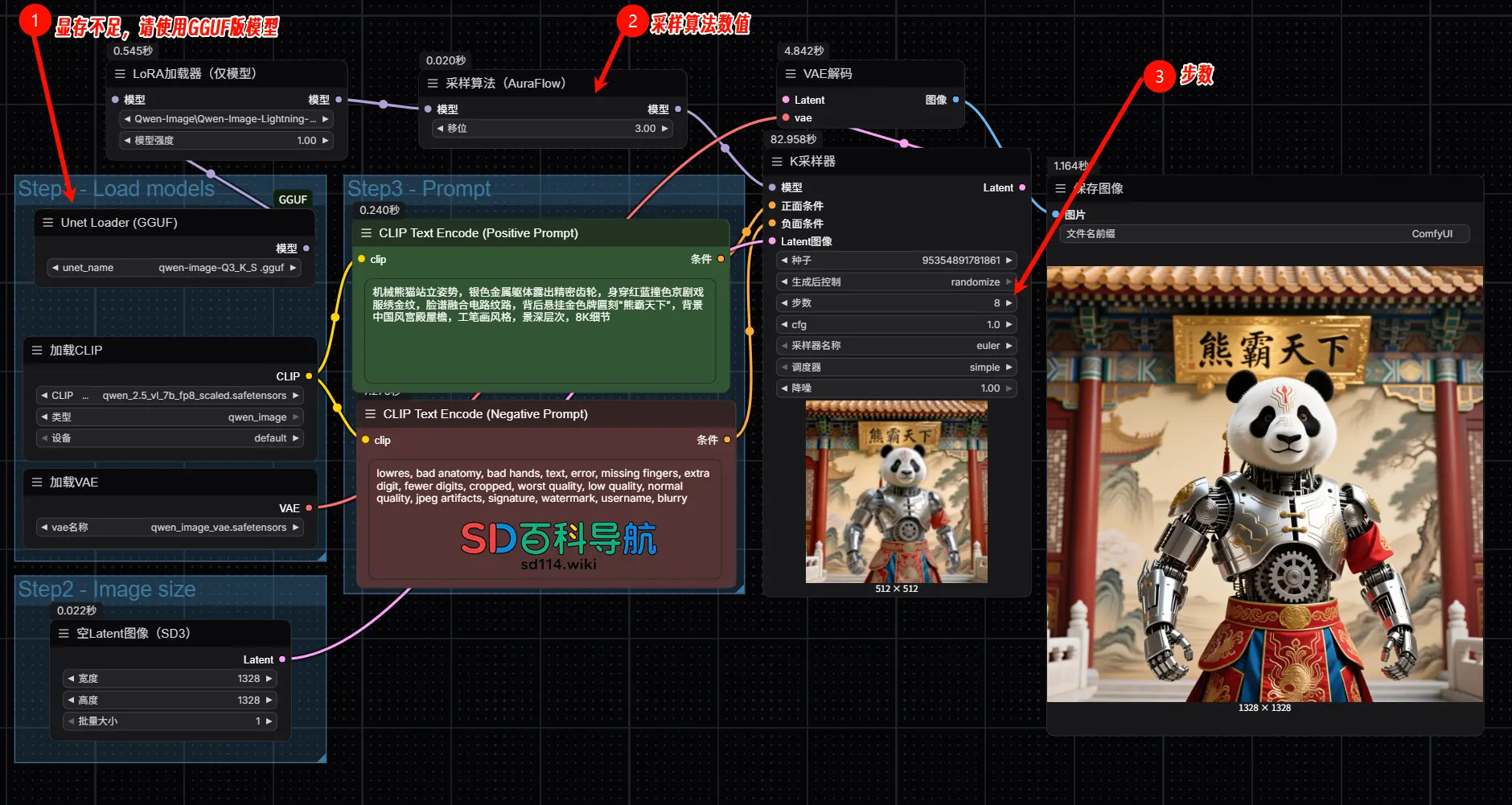
4步出图,文本清晰!高效推理加速Lora,Qwen-Image-Lightning来了LightX2V团队推出 Qwen-Image-Lightning —— Qwen-Image 系列的高效推理加速Lora,它在显著降低计算成本的同时,完整保留了原模型对复杂文本内容生成(如广告文案...工作流# Qwen-Image-Lightning7个月前01,4370
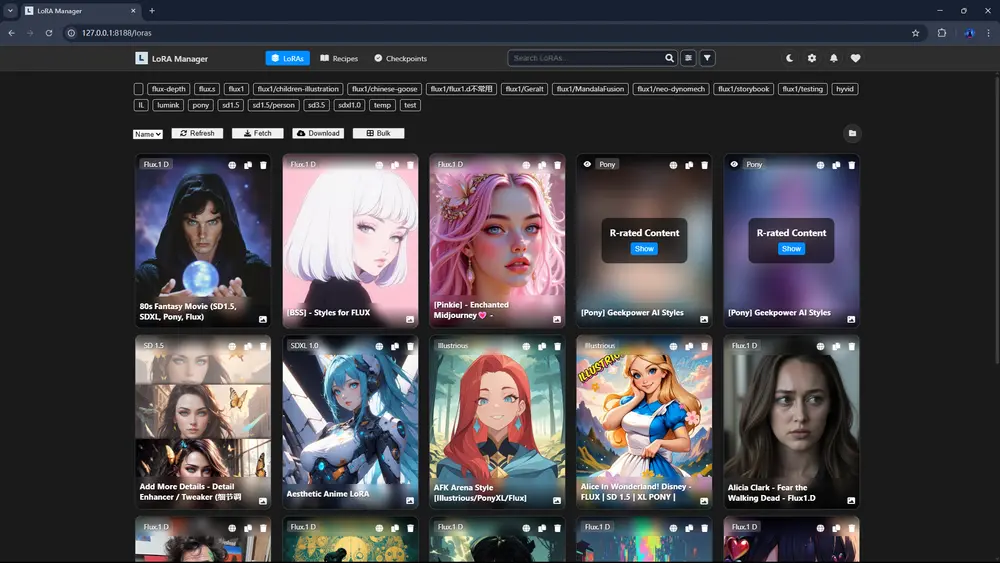
LoRA模型管理插件ComfyUI LoRA Manager:简化LoRA模型的组织、下载和应用流程,显著提升创作效率ComfyUI自诞生以来就缺少一个像Stable Diffusion web UI那样的优秀的LoRA模型管理功能,今天要介绍的ComfyUI LoRA Manager或许是个不错的选择,开发者表示这...插件# ComfyUI LoRA Manager# ComfyUI插件# LoRA模型12个月前01,3820