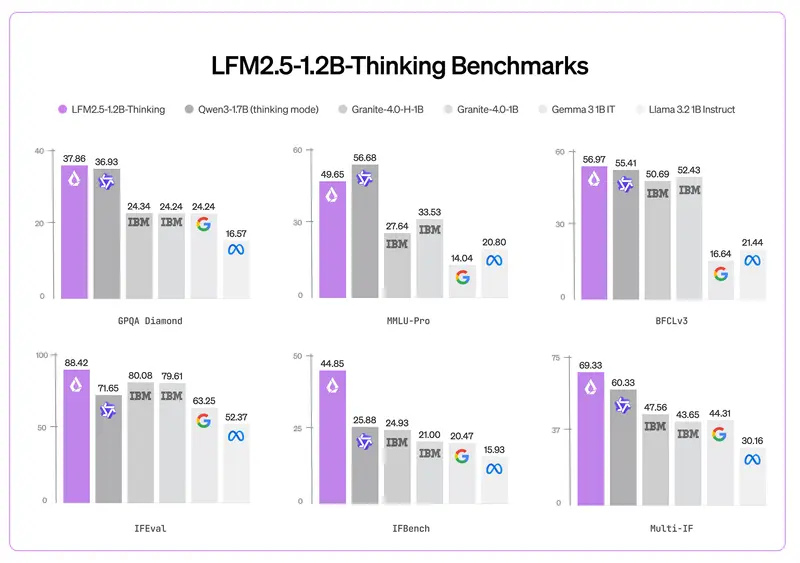
推理语言模型通过生成更长的思维链序列来提升性能,但目前无法控制推理长度,导致计算资源分配低效。模型可能生成过长输出浪费资源,或过早停止导致性能不佳。传统方法(如使用“等待”或“最终答案”标记)会降低性能,因为推理任务需要在计算效率和准确性之间找到平衡。
此前研究虽证明增加推理计算能改善复杂推理任务性能,但缺乏对推理长度的细粒度控制。卡内基梅隆大学(CMU)的研究人员推出了一种新方法——长度控制策略优化(Length Controlled Policy Optimization, LCPO),通过强化学习优化推理模型,使其在保持性能的同时精准控制推理长度。
- GitHub:https://github.com/cmu-l3/l1
- 模型:https://huggingface.co/collections/l3lab/l1-67cacf4e39c176ca4e9890f4
LCPO 方法的核心优势
LCPO 通过强化学习训练模型,使其根据用户指定的长度约束调整推理长度。这种方法产生了两种变体:
- L1-Exact:严格匹配目标长度,确保推理输出的精确性。
- L1-Max:保持在指定最大长度内,同时优先考虑正确性,提供灵活性。
这种方法不仅优化了推理性能,还确保了计算成本的可控性,提升了整体效率。

L1 模型的表现
研究人员训练的 L1 模型在多个基准测试中展现了卓越性能,始终优于基准模型,同时保持精确的令牌约束。与传统方法(如 S1)相比,L1 实现了 20-25% 的绝对提升和超过 100% 的相对提升。此外,L1 在域外任务中表现出良好的泛化能力,展现了稳健的性能扩展。
在数学推理任务中,L1 保持了高度的长度一致性,偏差极小。它采用自适应推理策略,在较长长度下为自我纠正和结论分配更多令牌,同时在中间推理步骤和最终输出之间保持高效平衡。
L1 的创新点
- 精确长度控制:L1 通过在提示中设定目标长度,解决了传统推理模型缺乏控制输出长度机制的问题。
- 强化学习训练:其奖励函数在准确性和长度约束之间取得平衡,确保推理过程既高效又准确。
- 超越现有方法:L1 不仅在等效推理长度下优于 GPT-4o 等大型模型,还在短思维链推理中表现出色,展现了强大的泛化能力。
研究总结
这项研究提出了 LCPO,一种强化学习方法,能够精确控制语言模型中推理链的长度。使用 LCPO 训练的 L1 模型遵循用户指定的长度约束,同时优化准确性。L1 在数学推理中实现了超过 100% 的相对提升和 20% 的绝对提升,并在域外任务中展现出良好的泛化能力。LCPO 通过简单的基于提示的长度控制,提供了一种可扩展且高效的方法来平衡计算成本和准确性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











