
随着全球对高性能计算需求的不断增长,AI模型训练和推理对硬件资源的需求也在快速攀升。然而,由于美国出口限制等原因,中国市场更多依赖于英伟达的“缩减版”H800 GPU(相较于H100功能有所削减)。这种硬件限制促使开发者寻求通过软件优化来提升性能的方法。DeepSeek的开源第一弹FlashMLA正是在这样的背景下应运而生,它通过软件优化,为AI产业带来了新的希望。(相关:DeepSeek 宣布将于下周开源五个经过实战检验的代码库)

FlashMLA:技术与性能突破
FlashMLA 是DeepSeek开发的一种高效解码内核,专为英伟达Hopper GPU(如H800和H100)设计,旨在优化多头潜在注意力(MLA)机制,提升大语言模型(LLM)的推理效率。以下是FlashMLA的核心技术亮点和性能突破:
1. 性能提升
- BF16矩阵乘法性能:FlashMLA在Hopper H800上实现了580 TFLOPS的性能,这几乎是行业标准评级的八倍。
- 内存带宽优化:通过高效的内存利用,FlashMLA实现了高达3000 GB/s的内存带宽,接近H800理论峰值的两倍。
- 低秩键值压缩:FlashMLA采用低秩键值压缩技术,将数据块分解成更小的部分,从而实现更快的处理速度,同时将内存消耗降低40%-60%。
- 动态分页系统:基于块的分页系统能够根据任务的强度动态分配内存,而不是使用固定的内存值。这使得模型能够更高效地处理可变长度序列,从而进一步提升性能。
2. 技术原理
FlashMLA的核心是优化MLA(多头潜在注意力)机制。与传统的多头注意力(MHA)技术相比,MLA通过低秩分解的方法,将大内存需求压缩成更小的内存占用,同时保持了相同的功能。这种优化不仅节省了空间,还显著提升了处理速度。
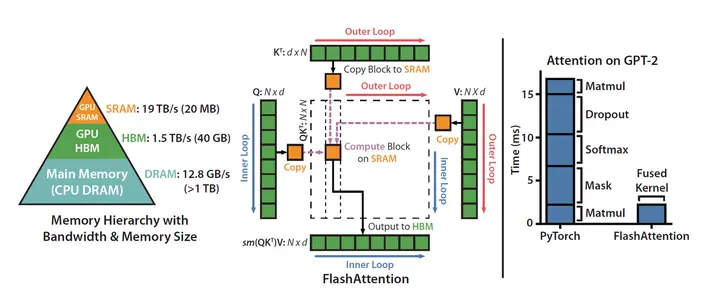
此外,FlashMLA还借鉴了FlashAttention 2&3和cutlass项目的经验。FlashAttention是一种高效的注意力计算方法,专门针对Transformer模型的自注意力机制进行优化,其核心目标是减少显存占用并加速计算。而cutlass则是一个优化工具,主要帮助提高计算效率。
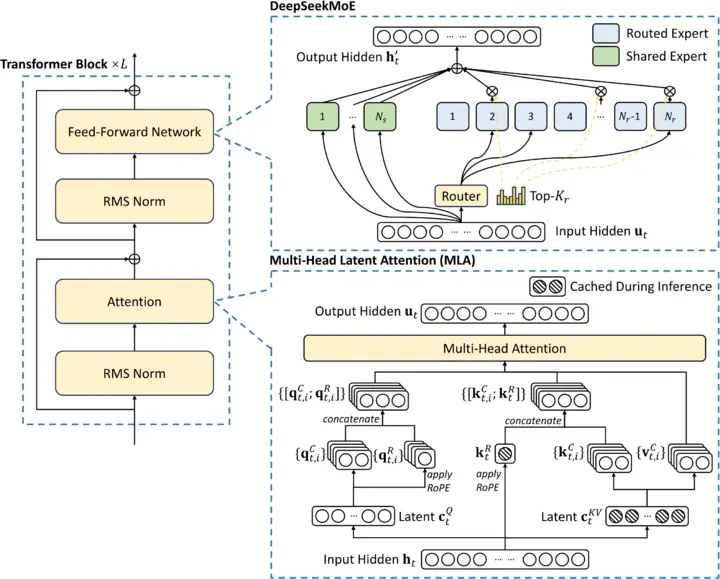
3. 应用场景
FlashMLA的主要应用场景包括:
- 长序列处理:适合处理数千个标记的文本,如文档分析或长对话。
- 实时应用:如聊天机器人、虚拟助手和实时翻译系统,降低延迟。
- 资源效率:减少内存和计算需求,便于在边缘设备上部署。
FlashMLA的开源与生态意义
FlashMLA的开源是DeepSeek“开源”周的重要组成部分,该公司计划通过GitHub向公众发布一系列易于使用的技术和工具。FlashMLA的开源不仅为AI开发者提供了强大的技术支持,还可能对整个AI生态产生深远影响:
- 降低硬件依赖:通过软件优化,FlashMLA减少了对高端硬件的依赖,使得AI模型能够在现有硬件条件下实现更高的性能。
- 开源生态扩展:FlashMLA可以被集成到vLLM(高效LLM推理框架)、Hugging Face Transformers或Llama.cpp(轻量级LLM推理)等生态中,从而让开源大语言模型(如LLaMA、Mistral、Falcon)运行得更高效。
- 降低推理成本:更高的计算效率(580 TFLOPS)和更好的内存带宽优化(3000 GB/s)使得相同的GPU资源可以处理更多请求,从而降低单位推理成本。
- 推动AI创业:过去,高效AI推理优化技术主要掌握在OpenAI、英伟达等巨头手中。FlashMLA的开源使得小型AI公司或独立开发者也能利用这些技术,从而催生更多的AI创业项目。
FlashMLA的部署与未来展望
FlashMLA的部署相对简单,但需要满足以下条件:
- 硬件要求:Hopper GPU(如H800或H100)。
- 软件要求:CUDA 12.3及以上版本,PyTorch 2.0及以上版本。
目前,FlashMLA仅支持BF16数据格式和分页KV缓存(块大小为64)。在H800 SXM5上运行CUDA 12.6时,FlashMLA在受内存带宽限制的配置下可达3000 GB/s,在受计算能力限制的配置下可达580 TFLOPS。
未来,FlashMLA有望进一步扩展其功能和兼容性。例如,它可能会被优化以支持更多的GPU型号,甚至可能被集成到其他AI框架中。此外,FlashMLA的开源也可能激发更多的开发者和研究机构进行类似的优化工作,从而推动整个AI领域的技术进步。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











