在 AI 智能体(Agent)向复杂长程任务进军的道路上,MiroThinker 团队今日正式推出了 MiroThinker-1.7 系列模型。该系列包含 MiroThinker-1.7-mini (30B) 和 MiroThinker-1.7 (235B) 两款模型,凭借增强的后训练流程和强大的工具调用能力,在深度研究与长链推理任务中实现了开源模型的SOTA性能。
- GitHub:https://github.com/MiroMindAI/MiroThinker
- 模型:https://huggingface.co/collections/miromind-ai/mirothinker-17
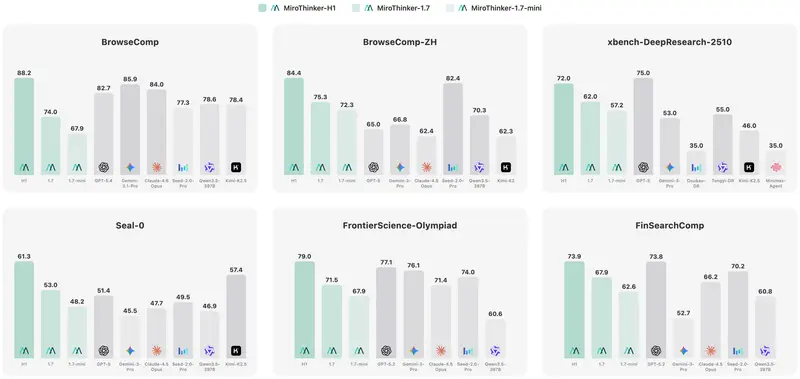
其中,仅拥有 30B 参数的 MiroThinker-1.7-mini 在权威基准测试 BrowseComp-ZH 上取得了 72.3 的高分,创下同量级开源模型的新纪录,证明了“小参数、大智慧”的可行性。
🚀 核心突破:为长链任务而生
MiroThinker-1.7 系列专为解决需要多步骤规划、长时间上下文保持及复杂工具交互的“深水区”任务而设计:
- 超长上下文窗口:原生支持 256K 上下文,能够轻松处理海量文档、长篇代码库及跨会话的长期记忆。
- 超强工具交互:单个任务最多支持 300 次 工具调用。无论是浏览网页、执行代码还是查询数据库,模型都能保持精准的逐步推理与决策,避免在长流程中“迷路”。
- 双版本灵活部署:
- **Mini **(30B):极致性价比,适合资源受限环境下的复杂推理,性能越级挑战大模型。
- **Full **(235B):旗舰性能,应对最苛刻的深度研究场景,提供无与伦比的逻辑密度。
🏆 基准测试:全面领跑开源阵营
在严格的评估环境下(为防止信息泄露,测试期间屏蔽了部分网站访问),MiroThinker-1.7 展现了卓越的通用研究能力:
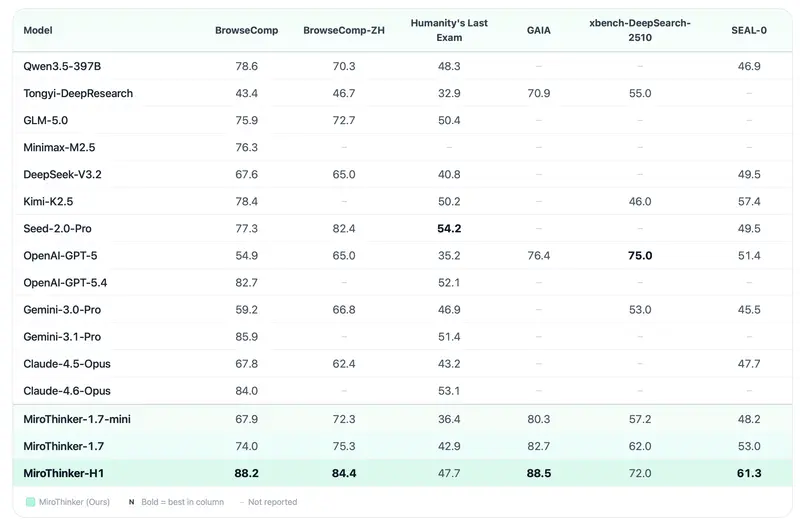
| 基准测试 | MiroThinker-1.7 得分 | 表现评价 |
|---|---|---|
| BrowseComp-ZH (中文浏览理解) | 75.3% | SOTA (开源第一) |
| BrowseComp (英文浏览理解) | 74.0% | 领先同类开源模型 |
| GAIA-Val-165 (通用智能体评估) | 82.7% | 展现强大的多模态与工具协同能力 |
| HLE-Text (高难度逻辑推理) | 42.9% | 在极难逻辑题上取得显著突破 |
注:MiroThinker-1.7-mini (30B) 在 BrowseComp-ZH 上单独取得了 72.3 分,以极小的参数量逼近旗舰版表现,效率惊人。
🧠 技术亮点:可验证的推理链条
MiroThinker 系列的核心优势在于其专有的智能体架构 MiroThinker-H1。该架构引入了“步骤可验证”与“全局可验证”的双重机制:
- 过程透明:每一步的工具调用和推理逻辑均可被独立审查,减少了“幻觉”在长链条中的累积。
- 自我修正:模型能够在执行过程中根据反馈动态调整策略,显著提升了复杂工作流的成功率。
📦 生态与获取
MiroThinker-1.7 系列不仅发布了模型权重,还配套提供了一套全面的工具链和工作流模板,旨在降低开发者构建高级智能体的门槛。
- 模型规模:30B / 235B
- 上下文:256K
- 工具调用上限:300 次/任务
- 获取方式:现已上线 Hugging Face,开发者可立即下载体验。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











