Mistral AI 宣布开源 Mistral Small 4。这不仅仅是一次版本迭代,更是 Mistral 在开源 AI 领域的一次战略级跨越。
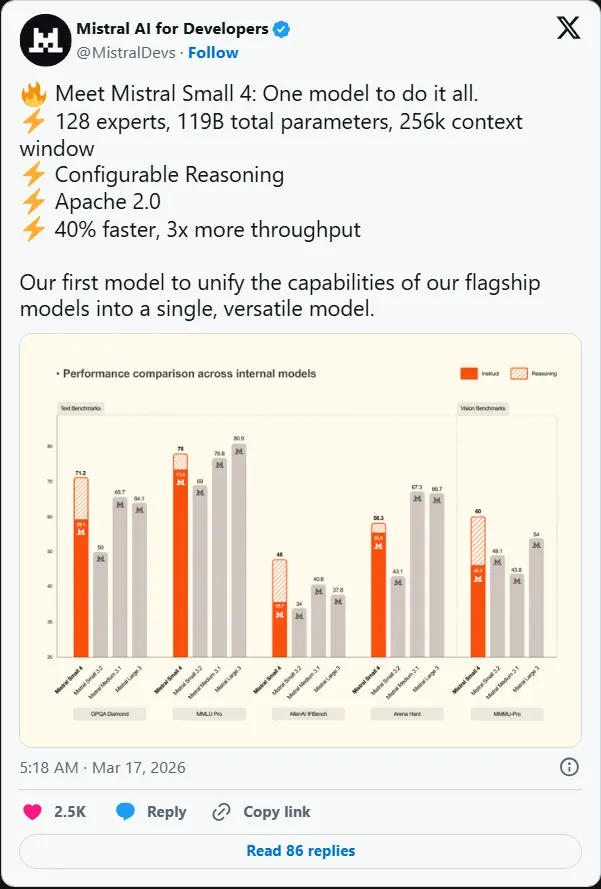
作为 Mistral Small 系列的最新旗舰,Small 4 打破了以往“快速指令”、“深度推理”与“多模态视觉”必须分属不同模型的界限。它首次将 Magistral 的推理深度、Devstral 的代理编码能力以及 Pixtral 的多模态视觉理解完美融合于单一架构之中。
- 官方介绍:https://mistral.ai/news/mistral-small-4
- API:https://mistral.ai/products/studio
- 模型:https://huggingface.co/collections/mistralai/mistral-small-4
在 Apache 2.0 宽松许可下,这款拥有 1190 亿参数的混合专家模型(MoE)向全球开发者、企业及研究人员完全开放。无论是通过 Mistral API、Hugging Face,还是本地部署的 vLLM 与 llama.cpp,你都可以即刻体验这一兼具速度与智能的全新引擎。
核心突破:统一架构,按需推理
过去,开发者往往需要在“响应速度”与“逻辑深度”之间做取舍,或在处理图像时切换专用模型。Mistral Small 4 终结了这一妥协。
1. 真正的“全能型”选手
Small 4 是一个统一的通用模型,能够根据任务需求动态调整行为:
- 日常对话与指令:提供毫秒级响应的轻量交互。
- 复杂逻辑与数学:调用深度推理引擎,逐步拆解难题。
- 代码代理与开发:具备 Devstral 级别的代码生成、调试与工作流自动化能力。
- 多模态分析:原生支持文本与图像输入,从文档解析到视觉图表分析一气呵成。
2. 可配置的推理努力度 (reasoning_effort)
这是 Small 4 最具创新性的特性之一。用户可通过参数动态控制模型的“思考深度”:
reasoning_effort="none":极速模式。适用于简单问答、摘要提取等日常任务,追求最低延迟。reasoning_effort="high":深度模式。适用于数学证明、复杂代码架构设计或长逻辑链推导,模型将自动进行多步思维链(CoT)推演。
价值主张:无需维护多个模型实例,单一部署即可覆盖从客服聊天到科研辅助的全场景需求,大幅降低基础设施成本。
架构解密:高效能背后的秘密
Mistral Small 4 采用了先进的 混合专家架构 (Mixture of Experts, MoE),在保持庞大知识容量的同时,实现了极致的运行效率。
| 架构指标 | 详细参数 | 优势解读 |
|---|---|---|
| 总参数量 | 1190 亿 (119B) | 具备旗舰级的知识储备与泛化能力。 |
| 激活参数 | 60 亿 (6B) / Token | 每次推理仅激活约 5% 的参数,显著降低计算负载与显存占用。 |
| 专家网络 | 128 个专家 | 每个 Token 动态路由激活 4 个专家,实现高度专业化分工。 |
| 上下文窗口 | 256k | 轻松处理整本小说、超长代码库或数百页的技术文档。 |
| 多模态支持 | 文本 + 图像 | 原生视觉编码器,无需外挂插件即可理解图表、截图与文档。 |
这种“大容量、小激活”的设计,使得 Small 4 在保持 GPT-OSS 120B 级别智能的同时,运行成本却远低于同类稠密模型。
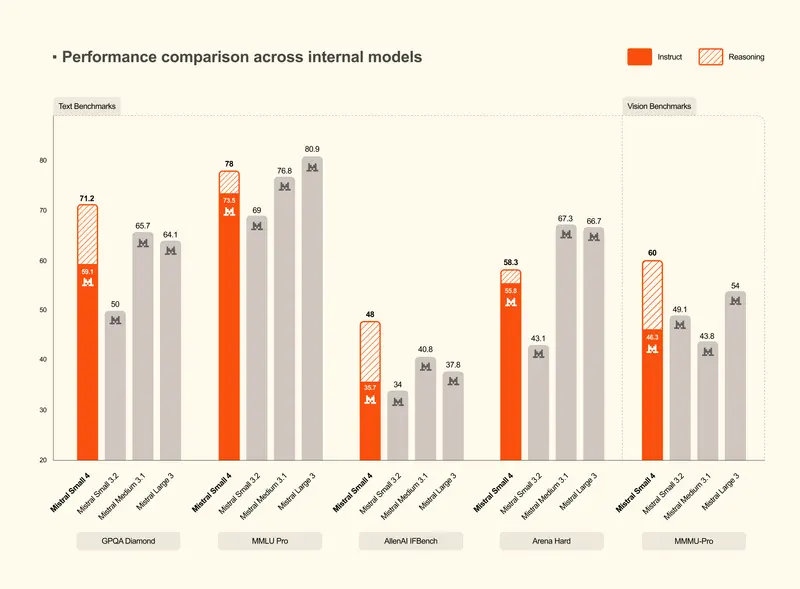
性能实测:更快、更准、更省
与上一代 Mistral Small 3 相比,Small 4 在效率与质量上实现了双重飞跃。官方基准测试数据显示:
- ⏱️ 延迟降低 40%:端到端完成时间大幅缩短,用户体验更加流畅。
- 📈 吞吐量提升 3 倍:每秒请求数(RPS)翻了三番,高并发场景下的服务能力显著增强。
- 🎯 输出更精炼:在同等性能下,Small 4 生成的内容更短、更精准。
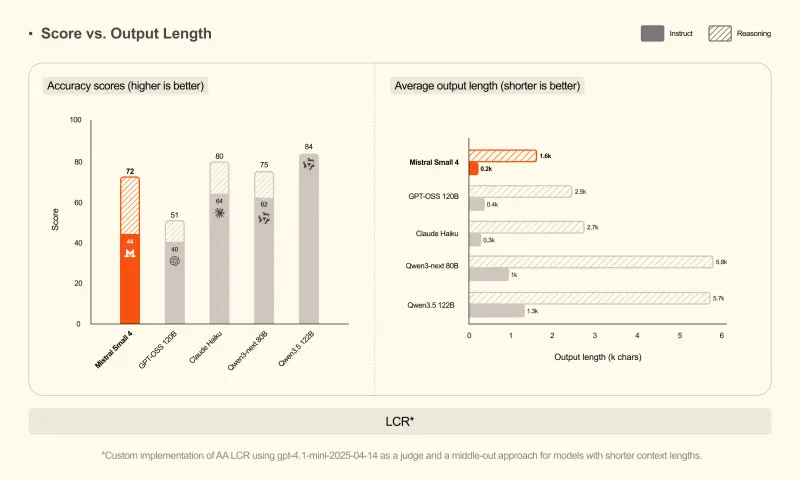
- AA LCR 基准:Small 4 仅用 1.6K 字符 即获得 0.72 分,而 Qwen 等竞品需 3.5-4 倍的输出量才能达到同等效果。
- LiveCodeBench:性能超越 GPT-OSS 120B,且代码输出量减少 20%,意味着更少的 Token 消耗与更快的生成速度。
这种“短而精”的特性,对于按 Token 计费的 API 用户或关注 GPU 成本的企业而言,直接转化为真金白银的节省。
部署与生态:开箱即用,灵活集成
Mistral Small 4 秉承“开放协作”的理念,提供了极其友好的部署体验。
1. 广泛的框架支持
模型已针对主流开源推理框架进行了深度优化:
- vLLM & SGLang:经过专门调优,确保护理高吞吐量服务时的极致效率。
- llama.cpp:支持本地量化运行,让高性能模型在消费级硬件上成为可能。
- Transformers:原生支持,方便研究人员进行微调与实验。
2. 灵活的部署方案
- 云端调用:通过 Mistral API 或 AI Studio 即时接入。
- 容器化部署:NVIDIA 提供 Day-0 NIM 容器,支持一键部署。
- 本地私有化:企业可下载权重,在内部服务器或私有云中完全离线运行,确保数据主权。
3. 推荐硬件配置
为了充分发挥 Small 4 的性能,Mistral 给出了以下硬件建议:
- 最低配置:4x NVIDIA HGX H100 或 2x NVIDIA HGX H200。
- 推荐配置(最佳性能):4x NVIDIA HGX H200 或 2x NVIDIA DGX B200。
- 单卡可行性:得益于 MoE 架构的高效性,经过量化处理后,甚至在单张高端消费级显卡上也能运行部分精度版本。
生态合作:加入 NVIDIA Nemotron 联盟
Mistral 此次发布不仅展示了技术实力,更彰显了其开放合作的愿景。作为创始成员,Mistral 正式加入 NVIDIA Nemotron 联盟。
这一举措标志着 Mistral 将与英伟达及全球主要行业参与者紧密协作,共同推动大规模、高效 AI 模型的标准化与优化。通过共享工具链、优化推理引擎,双方致力于让像 Small 4 这样的高性能开源模型在企业级应用中更容易落地。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











