ComfyUI-AceMusic 是基于 ACE-Step 1.5 开发的 ComfyUI 自定义节点,专注实现多语言带歌词完整歌曲生成,支持 19 种语言(含中文、英语、日语、韩语等),将 ACE-Step 1.5 核心能力完整封装为节点化工作流,适配本地部署与生产级音乐创作场景。
核心亮点
- 完整 ACE-Step 1.5 集成:全球首个将 ACE-Step 1.5 全功能落地为 ComfyUI 节点的套件,共 15 个功能节点,覆盖生成、编辑、微调全流程。
- 模块化节点架构:拆分 Settings、Lyrics、Caption 独立节点,无组件顺序依赖,工作流逻辑清晰、可读性强,便于复用与二次修改。
- 跨平台高兼容:替换 torchaudio 为 soundfile/scipy 后端,完美支持 Windows 系统及 Python 3.13+ 版本,解决跨环境兼容性问题。
- 生产级稳定性:内置输入验证、参数自动回退机制,避免运行时报错;支持批量生成与异常容错,适配长期稳定运行。
- 生态互通:与 HeartMuLa 节点无缝衔接,可组合构建混合 AI 音乐工作流,兼容主流音乐生成插件生态。
核心功能特性
1. 多语言歌词生成
支持 19 种语言生成带人声的完整歌曲,核心语言品质分级:
- 优秀:英语(en)、中文(zh)、日语(ja)
- 很好:韩语(ko)、西班牙语(es)
其余语言均支持基础生成,满足多语种创作需求。
2. 歌曲结构精细化控制
通过标准段落标记定义歌曲结构,支持完整歌曲范式:
| 段落标记 | 功能说明 |
|---|---|
| [Intro] | 开场器乐/人声引子 |
| [Verse] | 主歌段落 |
| [Pre-Chorus] | 副歌过渡段 |
| [Chorus] | 副歌/高潮核心段 |
| [Bridge] | 对比转折段落 |
| [Outro] | 结尾收尾段 |
| [Instrumental] | 纯器乐段落 |
3. 风格与参数精准调控
- 风格标签体系:支持流派、人声、情绪、节奏、乐器多维度标签组合,精准控制音乐风格。
- 流派:pop、rock、electronic、jazz、c-pop、mandopop 等;
- 人声:female vocal、male vocal、duet、choir、instrumental;
- 情绪:energetic、melancholic、romantic、dreamy 等;
- 乐器:piano、guitar、drums、erhu、pipa 等。
示例标签组合:mandopop, female vocal, romantic, piano, emotional ballad。
- 时长与参数:支持最长 240 秒(4 分钟)连续音频生成,可自定义 BPM、采样步数、语言等核心参数。
4. 全链路音频编辑
覆盖从生成到二次修改的全流程,支持 5 大核心编辑功能:
- Cover:现有音频风格转换(Audio2Music);
- Repaint:音频指定片段重生成;
- Retake:现有音频变体创作;
- Extend:音频首尾内容扩展;
- Edit:保留旋律前提下修改标签/歌词(FlowEdit)。
5. 模型与微调支持
- 自动下载并缓存 ACE-Step 官方模型,存储路径:
~/.cache/ace-step/checkpoints/; - 支持 LoRA 微调适配器加载,适配特殊风格、音色定制化需求。
完整节点列表(15 个核心节点)
| 节点名称 | 核心功能 |
|---|---|
| Model Loader | 下载、加载并缓存 ACE-Step 基础模型 |
| Settings | 配置生成参数(时长、语言、BPM、步数等) |
| Generator | 文本+歌词驱动音乐生成(Text2Music 核心节点) |
| Lyrics Input | 专用歌词输入节点,支持段落标记解析 |
| Caption Input | 风格/流派标签专用输入节点 |
| Cover | 音频风格转换(Audio2Audio) |
| Repaint | 音频局部片段重生成 |
| Retake | 现有音频变体生成 |
| Extend | 音频首尾内容扩展 |
| Edit | 保留旋律的标签/歌词修改(FlowEdit) |
| Conditioning | 参数整合为 Conditioning 条件对象 |
| Generator (from Cond) | 基于 Conditioning 对象生成音乐 |
| Load LoRA | 加载 LoRA 微调适配器 |
| Understand | 从现有音频提取元数据(风格、结构、参数) |
| Create Sample | 自然语言查询转生成参数 |
安装教程
方式一:ComfyUI Manager 安装(推荐)
- 打开 ComfyUI,进入 ComfyUI Manager 面板;
- 搜索节点名称:
ComfyUI-AceMusic; - 点击安装,等待依赖自动下载完成,重启 ComfyUI 生效。
方式二:手动源码安装
- 进入 ComfyUI 自定义节点目录:
cd ComfyUI/custom_nodes - 克隆项目仓库:
git clone https://github.com/hiroki-abe-58/ComfyUI-AceMusic.git - 安装节点依赖:
cd ComfyUI-AceMusic pip install -r requirements.txt - 安装 ACE-Step 1.5 核心库:
pip install git+https://github.com/ace-step/ACE-Step.git - 重启 ComfyUI,节点自动加载。
模型下载
首次使用节点时,模型会自动从 Hugging Face 下载至本地缓存目录,无需手动操作;若下载失败,可手动下载模型文件放入 ~/.cache/ace-step/checkpoints/。
快速开始(基础工作流)
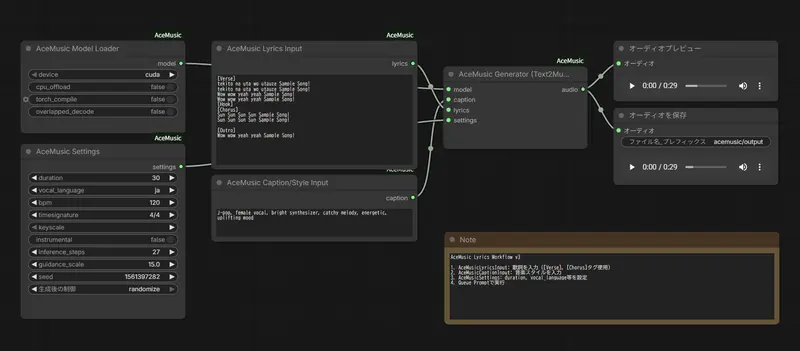
- 加载模型:添加
AceMusic Model Loader节点,选择运行设备(cuda 优先,无 GPU 选 cpu); - 配置参数:添加
AceMusic Settings节点,设置歌曲时长(如 180 秒)、语言(zh 中文)、BPM(如 120); - 输入歌词:添加
AceMusic Lyrics Input节点,输入带段落标记的歌词,示例:[Verse] 走在空旷的街道上 想着你和我的过往 [Chorus] 我们属于彼此 从现在到永远 - 设置风格:添加
AceMusic Caption Input节点,输入风格标签,如pop, female vocal, energetic; - 连接生成:将 Model Loader、Settings、Lyrics Input、Caption Input 节点连接至
AceMusic Generator; - 预览输出:Generator 输出端连接
Preview Audio节点,点击运行,生成完成后可直接播放音频。
示例工作流可直接加载项目内 workflow/AceMusic_Lyrics_v3.json 文件,快速复用。
硬件要求与性能
显存要求
- 普通模式:≥8GB 显存,全速生成,适配 RTX 3090/4090/5090、A100 等;
- CPU Offload 模式:≈4GB 显存,生成速度较慢,适配低显存设备。
生成性能(27 步采样,1 分钟音频)
| 设备型号 | RTF 倍率 | 生成耗时 |
|---|---|---|
| RTX 5090 | ~50x | ~1.2 秒 |
| RTX 4090 | 34.48x | 1.74 秒 |
| A100 | 27.27x | 2.20 秒 |
| RTX 3090 | 12.76x | 4.70 秒 |
| M2 Max | 2.27x | 26.43 秒 |
使用提示
- 歌词输入需严格遵循段落标记格式,避免无标记纯文本,否则结构解析异常;
- 风格标签建议 3-5 个组合,过多标签会导致生成风格混乱;
- 低显存设备优先开启 CPU Offload,避免显存溢出;
- 生成长音频(≥3 分钟)时,建议降低采样步数,平衡速度与质量。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











