ComfyUI-CacheDiT是一款专为ComfyUI打造的DiT模型加速插件,核心亮点是无需手动配置、一键启用,通过智能缓存技术能为Z-Image、Qwen-Image、LTX-2等DiT模型带来1.4-2.0倍的推理加速,且对生成图像/视频质量的影响微乎其微,完美解决ComfyUI中DiT模型推理速度慢的痛点,上手门槛极低,新手也能快速解锁高效生成体验。
该插件灵感来源于英特尔XPU上的高性能GenAI解决方案llm-scaler,已对多款主流图像/视频DiT模型完成测试验证,不同模型的加速比清晰可查,无需担心兼容性问题。
核心亮点:无需配置、高效提速、兼容性强
- 显著提速,无需配置:一键启用智能缓存,无需调整复杂参数,即可实现1.4-2.0倍加速,不同模型提速效果可量化,落地即用;
- 多模型验证,兼容性佳:已测试验证Z-Image、Qwen-Image、LTX-2、WAN2.2 14B等多款图像/视频DiT模型,均能稳定运行并实现预期加速;
- 智能回退,稳定可靠:采用两级加速方案(主方案:cache-dit库DBCache算法;回退方案:轻量级前向钩子缓存),遇到非标准模型架构会自动激活回退方案,避免加速失效;
- 质量影响微乎其微:默认配置下,缓存加速仅优化推理速度,对图像/视频的细节、风格、时间一致性(视频)影响极小,兼顾效率与质量;
- 内置性能监控:支持显示性能仪表板,可直观查看缓存命中率等关键指标,方便排查加速问题。
已验证模型:提速比清晰,覆盖图像/视频场景
以下是官方已测试验证的模型列表,包含提速比、预热步数等关键信息,可作为使用参考:
| 模型 | 推荐步数 | 加速比 | 运行状态 | 预热步数 | 跳过间隔 |
|---|---|---|---|---|---|
| Z-Image | 50 | 1.3x | ✅ 正常 | 10 | 5 |
| Z-Image-Turbo | 9 | 1.5x | ✅ 正常 | 3 | 2 |
| Qwen-Image-2512 | 50 | 1.4-1.6x | ✅ 正常 | 5 | 3 |
| LTX-2 T2V(文生视频) | 20 | 2.0x | ✅ 正常 | 6 | 4 |
| LTX-2 I2V(图生视频) | 20 | 2.0x | ✅ 正常 | 6 | 4 |
| WAN2.2 14B T2V(文生视频) | 20 | 1.67x | ✅ 正常 | 4 | 2 |
| WAN2.2 14B I2V(图生视频) | 20 | 1.67x | ✅ 正常 | 4 | 2 |
备注:LTX-2和WAN2.2 14B为视频模型,需使用专用优化器节点(Node),才能保证最佳效果和时间一致性。
安装步骤:一步完成,依赖简单
该插件安装流程简洁,仅需满足Python前置依赖,再克隆仓库到ComfyUI自定义节点目录即可,无需安装任何外部运行环境,具体步骤如下:
步骤1:满足前置Python依赖
安装插件所需的Python依赖包:
pip install -r requirements.txt
备注:
requirements.txt位于插件仓库根目录,克隆仓库后可直接读取,也可提前查看仓库说明获取具体依赖清单。
步骤2:克隆仓库到ComfyUI自定义节点目录
# 进入ComfyUI的自定义节点目录
cd ComfyUI/custom_nodes/
# 克隆插件仓库
git clone https://github.com/Jasonzzt/ComfyUI-CacheDiT.git
步骤3:完成安装
克隆完成后,重启ComfyUI,即可在节点列表中找到⚡ CacheDiT Accelerator及专用视频模型优化器节点(Node),安装完成。
快速开始:三步上手,分场景使用
插件使用极致简单,无需复杂调参,仅需根据模型类型(图像/视频),连接对应的**ComfyUI节点(Node)**即可实现加速,具体操作如下:
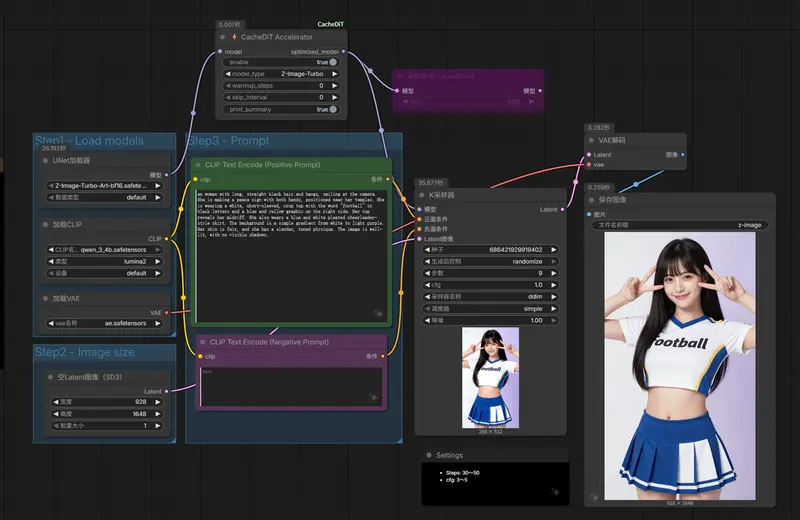
场景1:图像模型(Z-Image、Qwen-Image等)
核心节点连接流程:[加载检查点节点] → [⚡ CacheDiT 加速器节点] → [KSampler节点]
- 在ComfyUI中拖拽
Load Checkpoint节点(加载模型检查点),选择目标图像DiT模型(如Z-Image、Qwen-Image-2512); - 拖拽
⚡ CacheDiT Accelerator节点,将Load Checkpoint节点的MODEL输出端连接到该节点的model输入端; - 拖拽
KSampler节点(采样器),将⚡ CacheDiT Accelerator节点的MODEL输出端连接到KSampler的model输入端; - 正常配置其他节点(如提示词、图像尺寸、采样器参数等),点击运行,即可享受缓存加速,无需额外调整插件节点参数。
场景2:视频模型 - LTX-2(T2V/I2V)
核心节点连接流程:[加载检查点节点] → [⚡ LTX2 缓存优化器节点] → [阶段 1 KSampler节点]
- 拖拽
Load Checkpoint节点,加载LTX-2模型检查点; - 拖拽专用节点
⚡ LTX2 缓存优化器,完成模型节点的串联; - 连接对应的视频采样节点(阶段1 KSampler),配置其他视频生成参数(如视频长度、帧率),点击运行即可。
备注:LTX-2采用双潜在路径(视频+音频),专用优化器节点可保证视频时间一致性,避免画面抖动、失真。
场景3:视频模型 - WAN2.2 14B(高噪+低噪MoE架构)
核心节点连接流程(双模型分别连接专用节点):
[高噪模型 Load Checkpoint节点] → [⚡ Wan 缓存优化器节点] → [KSampler节点]
[低噪模型 Load Checkpoint节点] → [⚡ Wan 缓存优化器节点] → [KSampler节点]
- 分别拖拽两个
Load Checkpoint节点,加载WAN2.2 14B的高噪模型和低噪模型检查点; - 为两个模型各拖拽一个
⚡ Wan 缓存优化器节点,完成对应模型的串联; - 分别连接到对应的
KSampler节点,配置视频生成参数,点击运行;备注:WAN2.2 14B为MoE架构,两个专家模型拥有独立缓存,需分别使用专用优化器节点,才能实现最佳加速效果。
节点参数说明:默认即可,无需调整
插件节点参数简洁,所有技术参数(阈值、fn_blocks、预热步数等)均会根据模型类型自动配置,默认值即可满足绝大多数场景需求,具体参数说明如下:
| 参数 | 类型 | 默认值 | 核心描述 |
|---|---|---|---|
model | MODEL | - | 输入模型(必填,连接Load Checkpoint节点的MODEL输出) |
enable | Boolean | True | 启用/禁用缓存加速,禁用后恢复模型原生推理 |
model_type | Combo | Auto | 自动检测模型类型,也可手动选择预设(如Z-Image、LTX-2) |
print_summary | Boolean | True | 启用性能仪表板,显示缓存命中率、加速比等指标 |
工作原理:智能两级加速,缓存逻辑清晰
ComfyUI-CacheDiT的核心是智能缓存系统,采用两级加速方案保证稳定性,同时通过简单的缓存逻辑实现推理提速,具体原理如下:
1. 两级加速方案
- 主方案:基于cache-dit库的DBCache算法,为标准DiT模型架构提供高效缓存加速,是核心提速手段;
- 回退方案:轻量级缓存(直接前向钩子替换),当遇到ComfyUI中非标准DiT模型架构(cache-dit的BlockAdapter无法追踪)时,自动激活该方案,保证加速功能不失效。
2. 核心缓存逻辑
缓存加速的关键是预热后复用缓存结果,避免重复计算,核心逻辑如下:
# 先经过预热阶段(步数由模型类型自动配置,如Z-Image-Turbo为3步)
if (current_step - warmup) % skip_interval == 0:
# 满足跳过间隔条件,计算新结果并保存到缓存
result = transformer.forward(...)
cache = result.detach() # 分离张量,保存到缓存中,避免梯度计算影响
else:
# 不满足条件,直接复用缓存结果,无需重复计算
result = cache
备注:
warmup(预热步数)和skip_interval(跳过间隔)均由插件根据模型类型自动配置,无需手动调整,预热阶段用于初始化缓存,跳过间隔用于平衡提速效果和生成质量。
常见问题解答:解决使用中的核心疑问
1. 关于LTX-2/WAN2.2 14B的专用节点注意事项
LTX-2采用双潜在路径(视频+音频),WAN2.2 14B是高噪+低噪MoE架构,使用标准⚡ CacheDiT Accelerator节点无法保证最佳效果(可能出现视频时间一致性差、提速不达标),必须使用对应的专用节点:⚡ LTX2 缓存优化器、⚡ Wan 缓存优化器。
2. 支持蒸馏低步数模型吗?
目前仅Z-Image-Turbo(9步) 经过官方测试验证,可稳定提速1.5x。其他低步数蒸馏模型(< 6步)暂未验证,且极低步数场景下,预热开销会显著抵消加速收益,牺牲质量换取微小提速通常不值得。
3. 性能仪表板显示缓存命中率为0%?
出现该问题通常有三个原因:
- 模型未被正确检测:尝试在
model_type参数中手动选择对应模型预设,而非使用Auto; - 推理步数过短(< 10步):预热阶段占据了大部分步数,缓存尚未进入复用阶段,可适当增加推理步数;
- 已启用轻量级缓存:查看ComfyUI日志,若有"轻量级缓存已启用"的消息,说明模型为非标准架构,轻量级缓存的命中率可能不显示或为0%,但仍在正常提速。
4. 加速会影响图像/视频质量吗?
在默认配置(自动匹配模型参数)下,对生成质量的影响微乎其微,肉眼几乎难以分辨。只有在手动修改核心技术参数(如预热步数、跳过间隔)时,才可能出现质量下降,建议保持默认配置。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...