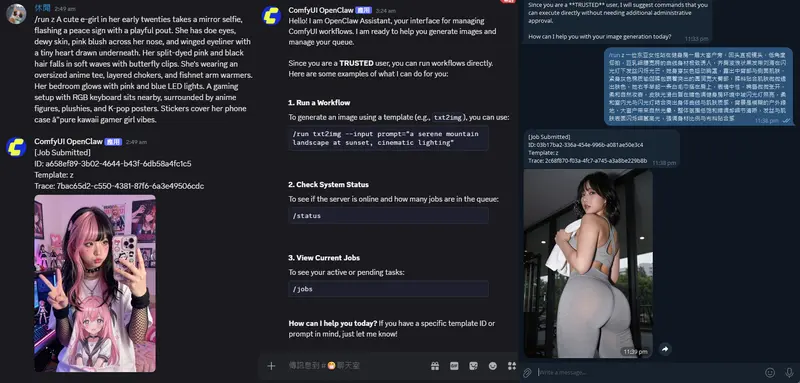
在AIGC内容创作中,文本到语音(TTS)正成为连接文字与听觉体验的关键一环。然而,大多数现有方案仍局限于单人朗读,难以满足对话类场景的需求——如AI聊天、虚拟主播、有声书或播客制作。
为此,1038Lab 推出 ComfyUI-FireRedTTS ——一个将 FireRedTTS-2 高质量语音合成模型深度集成至 ComfyUI 的自定义节点插件。
它不仅支持多说话者对话生成与独白叙述,还具备零样本声音克隆能力,并通过流式架构实现稳定长文本输出,适用于交互式语音应用与高质量音频生产。
核心特性一览
多说话者对话生成
支持 [S1]、[S2] 标记的结构化文本输入,自动区分不同角色并生成对应语音,实现自然的说话者交替。
高保真独白合成
适用于长篇叙述、旁白、文章朗读等单人语音场景,支持上下文感知韵律建模,语调更自然。
零样本声音克隆
无需训练,仅需一段参考音频和对应文本,即可复现目标音色,支持个性化语音定制。
多语言支持
覆盖中文、英语、日语、韩语、法语、德语、俄语,满足国际化内容需求。
自动化与设备适配
- 首次使用自动从 Hugging Face 下载模型(约2GB)
- 支持 CUDA、MPS、CPU 自动检测与切换
- 模型缓存机制避免重复下载
快速安装:两种方式任选
方法一:ComfyUI管理器(推荐)
- 打开 ComfyUI Manager
- 搜索
ComfyUI-FireRedTTS - 点击“安装”按钮,自动完成依赖安装
方法二:手动安装
cd ComfyUI/custom_nodes
git clone https://github.com/1038lab/ComfyUI-FireRedTTS.git
cd ComfyUI-FireRedTTS
pip install -r requirements.txt
重启 ComfyUI 后即可在节点列表中使用。
模型自动下载说明
首次运行时,系统将自动从 Hugging Face 获取主模型:
- 模型地址:
FireRedTeam/FireRedTTS2 - 存储路径:
ComfyUI/models/TTS/FireRedTTS2 - 文件大小:约 2GB
- 下载进度:界面显示实时进度条
下载完成后,模型被本地缓存,后续使用无需重新加载。
节点详解
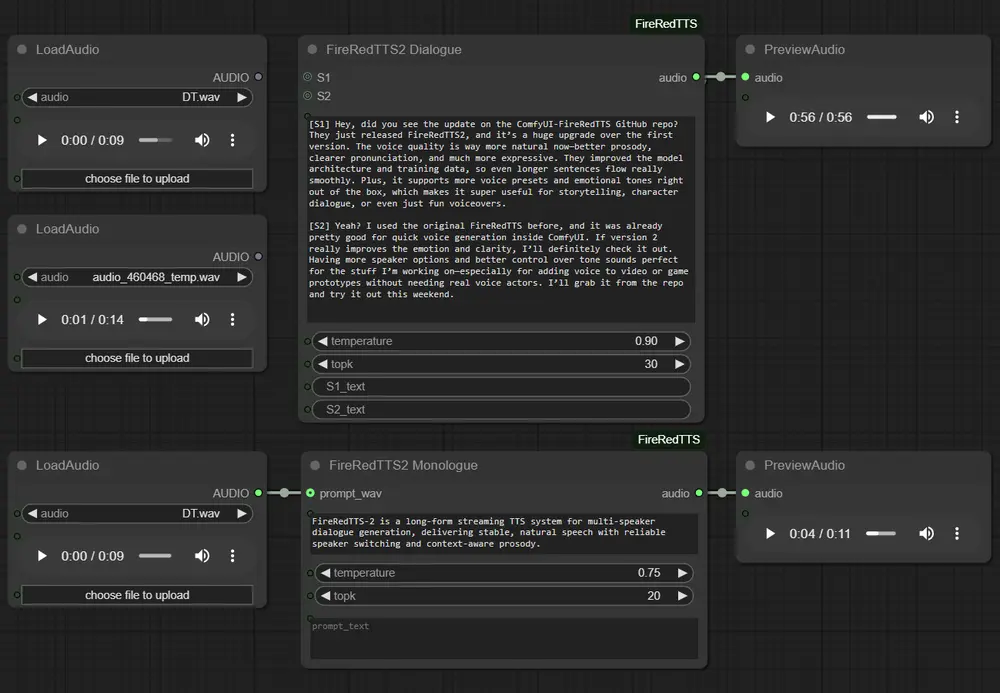
1. FireRedTTS2 对话节点(Dialogue Node)
用于生成包含多个角色的对话音频。
输入参数:
| 参数 | 类型 | 说明 |
|---|---|---|
text_list | STRING | 带说话者标签的文本,如 [S1]你好![S2]今天天气不错。 |
temperature | FLOAT | 控制语音随机性(默认 0.9) |
topk | INT | 控制采样多样性(默认 30) |
S1 / S2 | AUDIO (可选) | 参考音频,用于声音克隆 |
S1_text / S2_text | STRING (可选) | 对应参考音频的文本内容 |
输出:
audio:生成的对话音频(24kHz)sample_rate:采样率(固定为 24000 Hz)
2. FireRedTTS2 独白节点(Monologue Node)
适用于单人叙述、故事朗读等场景。
输入参数:
| 参数 | 类型 | 说明 |
|---|---|---|
text | STRING | 输入文本内容 |
temperature | FLOAT | 默认 0.75 |
topk | INT | 默认 20 |
prompt_wav | STRING (可选) | 参考音频路径,启用声音克隆 |
prompt_text | STRING (可选) | 参考文本 |
输出:
audio:生成的独白音频(24kHz)sample_rate:24000 Hz
使用示例
示例一:基础对话生成
[S1]欢迎收听我们的科技播客!
[S2]今天我们要聊的是大模型推理优化。
[S1]这是一个非常热门的话题。
添加“FireRedTTS2 Dialogue”节点,粘贴上述文本,连接音频输出至预览或保存节点即可播放。
示例二:声音克隆对话
- 准备两位说话者的参考音频(WAV/MP3格式)
- 将音频文件拖入 S1 和 S2 输入端口
- 在
S1_text和S2_text中填入对应文本 - 运行节点,生成带有真实音色的对话
✅ 提示:参考音频建议长度 ≥3秒,清晰无背景噪音
示例三:长文本独白生成
适用于小说朗读、知识讲解等内容:
- 输入文本可自动分段处理(推荐每段<500字符)
- 可配合
prompt_wav实现特定音色播报 - 支持批量生成多个段落并拼接
参数调优指南
Temperature(温度)
| 范围 | 效果 |
|---|---|
| 0.1–0.5 | 发音稳定、重复性强,适合机器人语音 |
| 0.6–1.0 | 自然流畅,推荐日常使用 |
| 1.1–2.0 | 表现力强,但可能出现失真,慎用 |
建议值:对话场景 0.9,独白场景 0.75
TopK
| 范围 | 效果 |
|---|---|
| 1–20 | 保守采样,发音规整 |
| 21–50 | 平衡自然度与稳定性 |
| 51–100 | 多样性强,可能引入噪声 |
建议值:一般设为 30(对话)、20(独白)
常见问题与解决
| 问题 | 解决方案 |
|---|---|
| 模型下载失败 | 检查网络是否能访问 Hugging Face,尝试配置代理或镜像源 |
| CUDA 内存不足 | 减少文本长度、关闭声音克隆、临时设置 device="cpu" |
| 音频质量差 | 检查参考音频质量,调整 temperature 至 0.7–1.0 区间 |
| 说话者标签无效 | 确保格式为 [S1]、[S2],无多余空格 |
| 节点加载失败 | 检查 Python 版本、依赖安装情况及 ComfyUI 兼容性 |
性能优化建议
内存管理
- 长文本会自动切分处理,降低内存压力
- 模型实例被缓存复用,提升连续生成效率
速度提升
- 首次加载需下载模型,后续启动更快
- GPU 加速显著提高生成速度(NVIDIA 推荐 4GB+ VRAM)
- 批量处理多个短文本比单次超长输入更高效
系统要求
| 类别 | 最低要求 | 推荐配置 |
|---|---|---|
| Python | 3.8+ | 3.9+ |
| RAM | 4GB | 8GB+ |
| 存储 | 2GB(模型空间) | SSD 更佳 |
| GPU | 不强制 | NVIDIA GPU(4GB+ VRAM) |
支持 macOS(MPS)、Windows/Linux(CUDA/CPU)全平台运行。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...